| Bytes | Lang | Time | Link |
|---|---|---|---|
| 058 | AWK | 250826T164240Z | xrs |
| 010 | K ngn/k | 230710T192933Z | coltim |
| 035 | Zsh | 230726T221448Z | roblogic |
| 055 | Bash +coreutils | 230728T185842Z | roblogic |
| 004 | 05AB1E | 230728T081535Z | Kevin Cr |
| 026 | Arturo | 230728T034702Z | chunes |
| 037 | Factor | 230726T235200Z | chunes |
| 059 | JavaScript Node.js | 230710T134610Z | Fhuvi |
| 003 | Japt R | 230711T131544Z | Shaggy |
| 065 | R | 230711T151123Z | Dominic |
| 153 | Nibbles | 230711T121804Z | Dominic |
| nan | ><> Fish | 230710T190033Z | mousetai |
| 006 | Japt R | 230710T194847Z | Luis fel |
| 003 | Thunno 2 | 230709T185912Z | The Thon |
| 007 | MATL | 160827T132749Z | Suever |
| 045 | Perl6 | 160825T103107Z | bb94 |
| 035 | Ruby | 170105T094211Z | G B |
| 243 | Racket | 161012T070953Z | rnso |
| 045 | Bash + coreutils | 160827T120706Z | seshouma |
| 178 | C | 160901T210818Z | user5898 |
| 067 | R | 160901T150405Z | Billywob |
| 086 | PowerShell | 160831T235059Z | SomeShin |
| 070 | Elixir | 160828T202940Z | Flow |
| 103 | Java 8 | 160828T041120Z | Akash Th |
| 048 | Javascript ES5 | 160827T133708Z | Paul Sch |
| 055 | Clojure | 160827T131621Z | James B. |
| 065 | PowerShell | 160826T224434Z | Chirishm |
| 091 | Swift | 160825T030243Z | jrich |
| 095 | R | 160825T000843Z | Rudier |
| 046 | Clojure | 160826T111618Z | Michael |
| 053 | Scala | 160826T094045Z | AmazingD |
| 038 | Haskell | 160825T005452Z | xnor |
| 060 | ARM machine code on Linux | 160826T000728Z | Ian Chew |
| 265 | S.I.L.O.S | 160825T202335Z | Rohan Jh |
| 067 | Javascript using external Library Enumerable | 160825T031503Z | applejac |
| 098 | C# 98 Bytes | 160824T232458Z | user1954 |
| 041 | Python 3.5+ | 160824T230149Z | Copper |
| 011 | Dyalog APL | 160825T055143Z | Adá |
| 123 | Oracle SQL 11.2 | 160825T160256Z | Jeto |
| 109 | Processing | 160824T225320Z | Cody |
| 031 | Perl | 160825T150953Z | Ton Hosp |
| 067 | PHP | 160825T140700Z | Crypto |
| 044 | PowerShell v2+ | 160825T130308Z | AdmBorkB |
| 009 | Pyke | 160825T081105Z | Blue |
| 036 | Emacs | 160825T100818Z | YSC |
| 123 | Common Lisp | 160825T095506Z | MatthewR |
| 010 | CJam | 160825T080920Z | Martin E |
| 007 | Brachylog | 160824T223836Z | Leaky Nu |
| 005 | Pyth | 160825T054755Z | Steven H |
| 049 | ><> | 160825T030217Z | torcado |
| 036 | Mathematica | 160825T025213Z | Greg Mar |
| 013 | Retina | 160824T230243Z | NinjaBea |
| 107 | Python | 160825T013240Z | Destruct |
| 006 | Pyth | 160825T002859Z | FryAmThe |
| nan | Ruby | 160825T002240Z | Jordan |
| 041 | JavaScript ES6 | 160824T233448Z | Neil |
| 061 | Octave | 160824T232519Z | Luis Men |
| 028 | Perl 6 | 160824T235324Z | Brad Gil |
| 046 | Ruby | 160824T233645Z | Value In |
| 046 | Vim | 160824T224507Z | DJMcMayh |
| 040 | Haskell | 160824T230719Z | nimi |
| 007 | 2sable | 160824T225609Z | Adnan |
| 005 | Jelly | 160824T225327Z | Leaky Nu |
K (ngn/k), 11 10 bytes
-1 byte from @doug's improvement
{.x" "_=x}
Returns characters in order of appearance in original input.
=xgroup the input, returning a dictionary mapping distinct values to the indices in which they appear in the input" "_remove the space character.xindex back into the input using the indices returned above, and return just the values of the dictionary (i.e. the list of repeated characters)
Zsh, 35 bytes
for x (${(us::)1// })<<<${1//[^$x]}
Input via argument $1. Expression ${(us::)1// } splits $1 to array of unique chars, and removes spaces. Iterate over the unique array. For each x, print $1, removing non-x chars.
45 bytes: A=(${(s::)1});for x (${(u)A})<<<${(Mj::)A#$x}
05AB1E, 4 bytes
ðK{γ
Outputs as a list.
Try it online or verify all test cases.
ðK could alternatively be ðм or #J for the same byte-count.
Explanation:
ðK # Remove all spaces from the (implicit) input-string
{ # Sort the remaining characters
γ # Group adjacent equal characters together in substrings
# (after which the resulting list is output implicitly)
ðм # (Vectorized) remove all spaces from the (implicit) input-string
# # Split the (implicit) input-string by spaces (no-op if the input doesn't contain
# any spaces)
J # Join this list back together to a string (or no-op, by joining the stack
# consisting of just the single string if the input didn't contained any spaces)
Arturo, 26 bytes
$=>[sort&--` `|chunk=>[&]]
Takes input as a list of characters.
$=>[ ; a function where input is assigned to &
sort ; sort
&--` ` ; input with spaces removed
| ; then
chunk=>[&] ; split into groups of equal contiguous characters
] ; end function
Factor, 37 bytes
[ " " without [ ] collect-by values ]
" " withoutremove spaces[ ] collect-bygroup letters by lettervaluesdiscard the keys
JavaScript (Node.js), 59 bytes
Here's some JS solutions without regex. Uses linebreak as separators between groups.
s=>[...s].sort().map(c=>b==(b=c)?c:`
`+c,b=0).join``.trim()
Alternative that might not be supported by some browsers because of at(-1) (62 bytes) :
s=>[...s].sort().map(c=>a+=a.at(-1)==c?c:`
`+c,a="")&&a.trim()
Try it:
f=s=>[...s].sort().map(c=>a+=a.at(-1)==c?c:`
`+c,a="")&&a.trim()
;[
`Ah, abracadabra!`,
`\\o/\\o/\\o/`,
`A man, a plan, a canal: Panama!`,
`"Show me how you do that trick, the one that makes me scream" she said`
].forEach(s=>console.log(f(s)))Alternative funny solution (67 bytes) :
s=>[...s].sort().map(a=c=>c!=' '?a[c]=[a[c]]+c:0)&&Object.values(a)
Japt -R, 3 bytes
¸¬ü
¸¬ü :Implicit input of string
¸ :Split on spaces
¬ :Join
ü :Group & sort
:Implicit output joined with newlines
R, 65 bytes
cat(strrep(z<-names(y<-table(strsplit(readline(),""))),y)[z>" "])
Full program that accepts input by reading a line from the terminal, and outputs a space-separated string of character-groups. The input & output are chosen to be directly comparable to the earlier R answers of Billywob and Frédéric.
Nevertheless, we could also golf a little further within the original rules, by writing a function that accepts input as an array of characters, and outputs an array of strings:
R, 49 bytes
function(x)strrep(z<-names(y<-table(x)),y)[z>" "]
Note that this could be further shortened to 42 bytes using a version of R that is more-recent than the challenge to allow us to exchange function for \.
Nibbles, 1.5 bytes (3 nibbles)
=~|
=~| # full program
=~|$$$ # with implicit args added;
| # filter
$ # the input
$ # by itself (=remove spaces),
=~ # now group the remaining characters by
$ # themselves

><> (Fish), 53 50 46 bytes
l'~')?v0
v?(0:i<]r+1r[
\~rvol-1
^?:<;?('!'l~oa
Finally beat the current fish answer. Note the link pre-populates the stack to make it faster but this is unnecessary for the correctness of the program.
Each element of the stack stores how often the nth character appears in the input.

The top row pushes ord('~') 0s to the stack.
The second row reads the input. Use [r1+r] to get the nth element of the stack, add 1 to it, then put it back into place.
The left (red) half of the third row reverses the stack so the higher valued items are on the top. Now we know that the length of the stack is the character code of the count the top element represents. This allows very convenient printing.
The left (grey) half of the bottom row checks if the count of the nth character is 0. If so go to the right half of the third row.
The right (blue) half of the bottom row prints a line break ao. Then pops the top of the stack. If we now have less than ord('!') items on the stack only spaces remain and we exit (since we shouldn't print spaces)
The right half of the third row runs if there is more than one occurrence of the top character. If so, we subtract one occurrence, then print the length of the stack as a character.
Thunno 2, 3 bytes
ðoÑ
ðo removes spaces from the string. Ñ is a built-in for "group by". There is no body so it just groups identical characters together.
Perl6, 48 47 45
slurp.comb.Bag.kv.map:{$^a.trim&&say $a x$^b}
Thanks to manatwork for the improvements.
Ruby, 35 bytes
->s{(?!..?~).map{|x|s.scan x}-[[]]}
Tried to turn the problem upside down to save some bytes. Instead of starting with the string, start with the possible character set.
Racket 243 bytes
(let*((l(sort(string->list s)char<?))(g(λ(k i)(list-ref k i))))(let loop((i 1)(ol(list(g l 0))))(cond((= i(length l))
(reverse ol))((equal?(g l(- i 1))(g l i))(loop(+ 1 i)(cons(g l i)ol)))(else(loop(+ 1 i)(cons(g l i)(cons #\newline ol)))))))
Ungolfed:
(define (f s)
(let*((l (sort (string->list s) char<?))
(g (λ (k i)(list-ref k i))) )
(let loop ((i 1)
(ol (list (g l 0))))
(cond
((= i (length l)) (reverse ol))
((equal? (g l (- i 1)) (g l i))
(loop (+ 1 i) (cons (g l i) ol)))
(else (loop (+ 1 i) (cons (g l i) (cons #\newline ol))))
))))
Testing:
(display (f "Ah, abracadabra!"))
Output:
(
!
,
A
a a a a a
b b
c
d
h
r r)
Bash + coreutils, 53 50 45 bytes
sed 's: ::g;s:\(.\)\1*:& :g'<<<`fold -1|sort`
There is no separator between the characters of a group and the groups are separated by space. There is one trailing group separator, but as I understood that's acceptable.
Run:
./explode_view.sh <<< '\o /\ o /\ o k'
Output:
// \\\ k ooo
C, 178
#define F for
#define i8 char
#define R return
z(i8*r,i8*e,i8*a){i8*b,c;F(;*a;++a)if(!isspace(c=*a)){F(b=a;*b;++b)if(r>=e)R-1;else if(*b==c)*b=' ',*r++=c;*r++='\n';}*r=0;R 0;}
z(outputArray,LastPointerOkinOutputarray,inputArray) return -1 on error 0 ok Note:Modify its input array too...
#define P printf
main(){char a[]="A, 12aa99dd333aA,,<<", b[256]; z(b,b+255,a);P("r=%s\n", b);}
/*
178
r=AA
,,,
1
2
aaa
99
dd
333
<<
*/
R, 67 bytes
Even though there's already an R-answer by @Frédéric I thought my solution deserves it's own answer because it's conceptually different.
for(i in unique(x<-strsplit(readline(),"")[[1]]))cat(x[x%in%i]," ")
The program prints the ascii characters in order of appearence in the string where groups are separated by two white spaces and chars within groups by one white space. A special case is if the string has whitespaces in itself, then at one specific place in the output there will be 4+number of white spaces in string white spaces separating two groups E.g:
Ah, abracadabra! => A h , a a a a a b b r r c d !
Ungolfed
Split up the code for clarity even though assignment is done within the unique functions and changed to order of evaluation:
x<-strsplit(readline(),"")[[1]]) # Read string from command line and convert into vector
for(i in unique(x){ # For each unique character of the string, create vector
cat(x[x%in%i]," ") # of TRUE/FALSE and return the elements in x for which
} # these are matched
PowerShell - 86
I imagine I could get this smaller, but I'll work on it later. This assumes that $d contains the string to explode.
$s="";$i=0;[Array]::Sort(($a=$d-split""));$a|%{$s+=$_;if($a[++$i]-cne$_){$s+="`n"}};$s
Elixir, 70 bytes
def f(s), do: '#{s}'|>Enum.group_by(&(&1))|>Map.delete(32)|>Map.values
Java 8, 121 120 110 103 Bytes
s->s.chars().distinct().filter(c->c!=32)
.forEach(c->out.println(s.replaceAll("[^\\Q"+(char)c+"\\E]","")))
Above lambda can be consumed with Java-8 Consumer. It fetches distinct characters and replaces other characters of the String to disassemble each character occurrence.
Javascript (ES5): 50 48 bytes
As a function:
function(i){return i.split("").sort().join(" ")}
The important code, replace the empty string with the search string (29 bytes):
"".split("").sort().join(" ")
Clojure (55 bytes)
(defn f[s](map(fn[[a b]](repeat b a))(frequencies s)))
Test Cases:
(f "Ah, abracadabra!")
;;=> ((\space) (\!) (\A) (\a \a \a \a \a) (\b \b) (\c) (\d) (\h) (\,) (\r \r))
(f "\\o/\\o/\\o/")
;;=> ((\\ \\ \\) (\o \o \o) (\/ \/ \/))
(f "A man, a plan, a canal: Panama!")
;;=> ((\space \space \space \space \space \space) (\!) (\A) (\a \a \a \a \a \a \a \a \a) (\c) (\, \,) (\l \l) (\m \m) (\n \n \n \n) (\P) (\p) (\:))
(f "\"Show me how you do that trick, the one that makes me scream\" she said")
;;=> ((\space \space \space \space \space \space \space \space \space \space \space \space \space \space) (\a \a \a \a \a) (\" \") (\c \c) (\d \d) (\e \e \e \e \e \e \e) (\h \h \h \h \h \h) (\i \i) (\k \k) (\,) (\m \m \m \m) (\n) (\o \o \o \o \o) (\r \r) (\S) (\s \s \s \s) (\t \t \t \t \t \t) (\u) (\w \w) (\y))
PowerShell, 65
@TimmyD has the shorter answer but I don't have enough rep to comment. Here's my answer in 65 bytes.
I didn't think to use group and I didn't know that you could stick -join in front of something instead of -join"" on the end and save two characters (using that would make my method 63).
([char[]]$args[0]-ne32|sort|%{if($l-ne$_){"`n"};$_;$l=$_})-join""
My method sorts the array, then loops through it and concatenates characters if they match the preceding entry, inserting a newline if they do not.
Swift, 105 91 bytes
Thanks to @NobodyNada for 14 bytes :)
Yeah, I'm pretty new to Swift...
func f(a:[Character]){for c in Set(a){for d in a{if c==d && c != " "{print(c)}}
print("")}}
Characters within a group are separated by a single newline. Groups are separated by two newlines.
R, 198 189 96 95 bytes
for(i in unique(a<-strsplit(gsub(" ","",readline()),"")[[1]]))cat(rep(i,sum(a==i)),"\n",sep="")
Ungolfed :
a<-strsplit(gsub(" ","",readline()),"")[[1]] #Takes the input from the console
for(i in unique(a)) #loop over unique characters found in variable a
cat(rep(i,sum(a==i)),"\n",sep="") # print that character n times, where n was the number of times it appeared
This solution is currently not entirely working, when \ are involved.
Now it is !
Thank a lot you to @JDL for golfing out 102 bytes !
Clojure, 46
#(partition-by identity(sort(re-seq #"\S" %)))
Long and descriptive function names for simplest of things, yeah.
Scala, 53 bytes
def?(s:String)=s.filter(_!=' ').groupBy(identity).map{_._2.mkString}
When run with REPL:
scala> ?("Ah, abracadabra!")
res2: scala.collection.immutable.Iterable[String] = List(!, A, aaaaa, ,, bb, c, h, rr, d)
scala> print(res2.mkString("\n"))
!
A
aaaaa
,
bb
c
h
rr
d
EDIT: Forgot to filter spaces
Haskell, 38 bytes
f s=[filter(==c)s|c<-['!'..],elem c s]
Basically nimi's solution, but explicitly checking only letters appearing in the string.
ARM machine code on Linux, 60 bytes
Hex Dump:
b590 4c0d f810 2b01 b11a 58a3 3301 50a3 e7f8 6222 2704 2001 f1ad 0101 2201 237f 5ce5 b135 700b df00 3d01 d8fc 250a 700d df00 3b01 d8f4 bd90 000200bc
This function basically creates an array of size 128, and whenever it reads a character from the input string it increment's the value at that characters position. Then it goes back through the array and prints each character array[character] times.
Ungolfed Assembly (GNU syntax):
.syntax unified
.bss @bss is zero-initialized data (doesn't impact code size)
countArray:
.skip 128 @countArray[x] is the number of occurances of x
.text
.global expStr
.thumb_func
expstr:
@Input: r0 - a NUL-terminated string.
@Output: Groups of characters to STDOUT
push {r4,r7,lr}
ldr r4,=countArray @Load countArray into r4
readLoop:
ldrb r2,[r0],#1 @r2=*r0++
cbz r2,endReadLoop @If r2==NUL, break
ldr r3,[r4,r2] @r3=r4[r2]
adds r3,r3,#1 @r3+=1
str r3,[r4,r2] @r4[r2]=r3
b readLoop @while (true)
endReadLoop:
@Now countArray[x] is the number of occurances of x.
@Also, r2 is zero
str r2,[r4,#' ] @'<character> means the value of <character>
@What that just did was set the number of spaces found to zero.
movs r7,#4 @4 is the system call for write
movs r0,#1 @1 is stdout
sub r1,sp,#1 @Allocate 1 byte on the stack
@Also r1 is the char* used for write
movs r2,#1 @We will print 1 character at a time
movs r3,#127 @Loop through all the characters
writeLoop:
ldrb r5,[r4,r3] @r5=countArray[r3]
cbz r5,endCharacterLoop @If we're not printing anything, go past the loop
strb r3,[r1] @We're going to print byte r3, so we store it at *r0
characterLoop:
swi #0 @Make system call
@Return value of write is number of characters printed in r0
@Since we're printing one character, it should just return 1, which
@means r0 didn't change.
subs r5,r5,#1
bhi characterLoop
@If we're here then we're done printing our group of characters
@Thus we just need to print a newline.
movs r5,#10 @r5='\n' (reusing r5 since we're done using it as a loop counter
strb r5,[r1]
swi #0 @Print the character
endCharacterLoop:
subs r3,r3,#1
bhi writeLoop @while (--r3)
pop {r4,r7,pc}
.ltorg @Store constants here
Testing script (also assembly):
.global _start
_start:
ldr r0,[sp,#8] @Read argv[1]
bl expstr @Call function
movs r7,#1 @1 is the system call for exit
swi #0 @Make system call
S.I.L.O.S 265
The (non competing) code better input format is at the bottom, feel free to try it online!
def : lbl
loadLine :
a = 256
:a
:s
x = get a
z = x
z - 32
z |
if z u
a + 1
GOTO s
:u
if x c
GOTO e
:c
b = x
b + 512
c = get b
c + 1
set b c
a + 1
if x a
:e
a = 512
b = 768
l = 10
:Z
j = a
j - b
if j z
z = get a
c = a
c - 512
:3
if z C
printChar l
a + 1
GOTO Z
:C
printChar c
z - 1
GOTO 3
:z
Input for the above is a series of command line arguments representing ascii values, terminated with a zero.Try it online!.
For a more reasonable method of input we must up the byte count (and use features that were nonexistent before the writing of this challenge).
For 291 bytes we get the following code.
\
def : lbl
loadLine :
a = 256
:a
:s
x = get a
z = x
z - 32
z |
if z u
a + 1
GOTO s
:u
if x c
GOTO e
:c
b = x
b + 512
c = get b
c + 1
set b c
a + 1
if x a
:e
a = 512
b = 768
l = 10
:Z
j = a
j - b
if j z
z = get a
c = a
c - 512
:3
if z C
printChar l
a + 1
GOTO Z
:C
printChar c
z - 1
GOTO 3
:z
Feel free to test this version online!. The backslash is unnecessary but is there to show the important leading line feed.
Javascript (using external Library - Enumerable) (78 67 bytes)
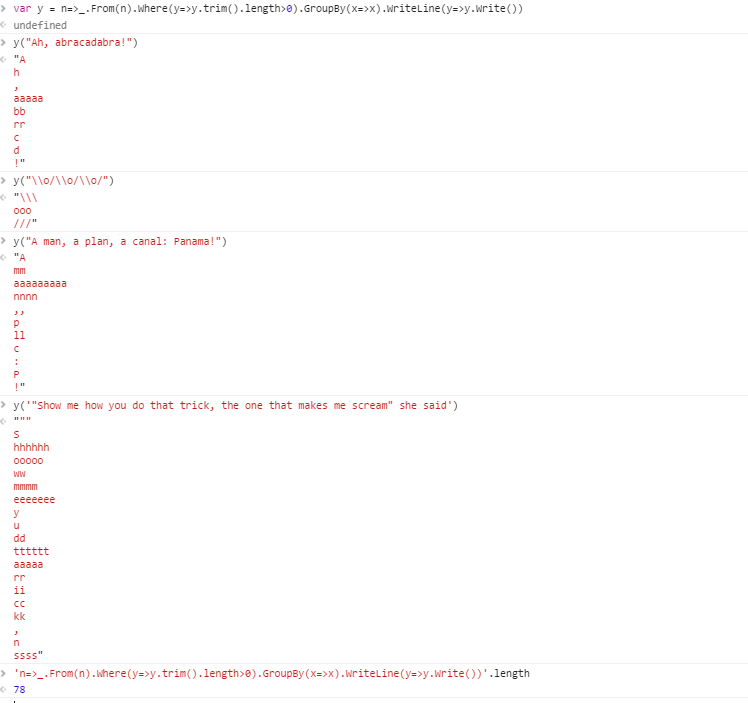
n=>_.From(n).Where(y=>y!=' ').GroupBy(x=>x).WriteLine(y=>y.Write())
Link to lib: https://github.com/mvegh1/Enumerable
Code explanation: This is what Enumerable was made to do! Load the string into the library, which converts it to a char array. Filter out the white space entries. Group by char. Write each group to a line, according to the specified predicate. That predicate says to join all the elements of the current group into a string, without a delimiter.
C# 125 98 Bytes
using System.Linq;s=>s.GroupBy(c=>c).Where(g=>g.Key!=' ').Select(g=>new string(g.Key,g.Count())));
Explanation
//Using anonymous function to remove the need for a full signature
//And also allow the implicit return of an IEnumerable
s =>
//Create the groupings
s.GroupBy(c => c)
//Remove spaces
.Where(g=> g.Key!=' ')
//Generate a new string using the grouping key (the character) and repeating it the correct number of times
.Select(g => new string(g.Key, g.Count()));
- Thanks to @TheLethalCoder who suggested the use of an anonymous function, which also allowed me to remove the
ToArraycall and just implicitly return an IEnumerable which collectively saves 27 bytes
Python 3.5+, 77 46 44 41 bytes
lambda s:[a*s.count(a)for a in{*s}-{' '}]
Pretty simple. Goes through the unique characters in the string by converting it to a set (using Python 3.5's extended iterable unpacking), then uses a list comprehension to construct the exploded diagrams by counting the number of times each character occurs in the string with str.count. We filter out spaces by removing them from the set.
The order of the output may vary from run to run; sets are unordered, so the order in which their items are processed, and thus this answer outputs, cannot be guaranteed.
This is a lambda expression; to use it, prefix lambda with f=.
Try it on Ideone! Ideone uses Python 3.4, which isn't sufficient.
Usage example:
>>> f=lambda s:[a*s.count(a)for a in{*s}-{' '}]
>>> f('Ah, abracadabra!')
[',', 'A', 'aaaaa', 'd', '!', 'bb', 'h', 'c', 'rr']
Saved 3 bytes thanks to @shooqie!
Dyalog APL, 11 bytes
Function returning list of strings.
(⊂∩¨∪)~∘' '
(⊂∩¨∪) the intersection of the entirety and its unique characters
~∘' ' except spaces
Oracle SQL 11.2, 123 bytes
SELECT LISTAGG(c)WITHIN GROUP(ORDER BY 1)FROM(SELECT SUBSTR(:1,LEVEL,1)c FROM DUAL CONNECT BY LEVEL<=LENGTH(:1))GROUP BY c;
Un-golfed
SELECT LISTAGG(c)WITHIN GROUP(ORDER BY 1)
FROM (SELECT SUBSTR(:1,LEVEL,1)c FROM DUAL CONNECT BY LEVEL<=LENGTH(:1))
GROUP BY c
Processing, 109 bytes
void s(char[] x){x=sort(x);char l=0;for(char c:x){if(c!=l)println();if(c!=' '&&c!='\n'&&c!='\t')print(c);l=c;}}
Its the brute force approach, sort the array, then loop through it. If it doesn't match the last character printed, print a newline first. If it is whitespace, skip the printing step.
Perl, 31 bytes
Includes +1 for -p
Run with input on STDIN:
explode.pl <<< "ab.ceaba.d"
explode.pl:
#!/usr/bin/perl -p
s%.%$&x s/\Q$&//g.$/%eg;y/
//s
If you don't care about spurious newlines inbetween the lines the following 24 bytes version works too:
#!/usr/bin/perl -p
s%.%$&x s/\Q$&//g.$/%eg
PHP, 67 bytes
Space as separator
PHP5 using deprecated ereg_replace function.
for(;++$i<128;)echo ereg_replace("[^".chr($i)."]","",$argv[1])." ";
PHP7, 73 bytes
for(;++$i<128;)echo str_repeat($j=chr($i),substr_count($argv[1],$j))." ";
Using built in is worse :(
foreach(array_count_values(str_split($argv[1]))as$a=>$b)echo str_repeat($a,$b)." ";
PowerShell v2+, 44 bytes
[char[]]$args[0]-ne32|group|%{-join$_.Group}
Takes input $args[0] as a command-line argument literal string. Casts that as a char-array, and uses the -not equal operator to pull out spaces (ASCII 32). This works because casting has a higher order precedence, and when an array is used as the left-hand operator with a scalar as the right-hand, it acts like a filter.
We pass that array of characters to Group-Object, which does exactly what it says. Note that since we're passing characters, not strings, this properly groups with case-sensitivity.
Now, we've got a custom object(s) that has group names, counts, etc. If we just print that we'll have a host of extraneous output. So, we need to pipe those into a loop |%{...} and each iteration -join the .Group together into a single string. Those resultant strings are left on the pipeline, and output is implicit at program completion.
Example
PS C:\Tools\Scripts\golfing> .\exploded-view-of-substrings.ps1 'Programming Puzzles and Code Golf'
PP
rr
ooo
gg
aa
mm
i
nn
u
zz
ll
ee
s
dd
C
G
f
Emacs, 36 keystrokes
C-SPACE C-EM-xsort-rTABRETURN.RETURN.RETURNC-AC-M-S-%\(\(.\)\2*\)RETURN\1C-QC-JRETURN!
Result
A man, a plan, a canal: Panama! -->
!
,,
:
A
P
aaaaaaaaa
c
ll
mm
nnnn
p
Explanation
- C-SPACE C-E
- M-x
sort-rTAB RETURN .RETURN .RETURN - C-A
- C-M-S-%
\(\(.\)\2*\)RETURN\1C-Q C-JRETURN !
- Select the input line;
- Call
sort-regexp-fieldswith arguments.and.;- Argument #1: Regexp scpecifying records to sort
- Argument #2: Regexp scpecifying key within records
- Return at line start;
- Apply regexp substitution
\(\(.\)\2*\)->\1\non all matches.
Common Lisp, 123
(lambda(s &aux(w(string-trim" "(sort s'char<))))(princ(elt w 0))(reduce(lambda(x y)(unless(char= x y)(terpri))(princ y))w))
Ungolfed:
(lambda (s &aux (w (string-trim " " (sort s 'char<))))
(princ (elt w 0))
(reduce
(lambda (x y)
(unless (char= x y) (terpri))
(princ y))
w))
Not the most golf friendly language. This could probably be modified to return list of lists instead of printing string.
CJam, 10 bytes
{S-$e`::*}
An unnamed block that expects the string on top of the stack and replaces it with a list of strings.
Explanation
S- Remove spaces.
$ Sort.
e` Run-length encode, gives pairs [R C], where R is the run-length and
C is the character.
::* Repeat the C in each pair R times.
Brachylog, 14 7 bytes
7 bytes thanks to Fatalize.
:@Sxo@b
:@Sxo@b
:@Sx remove spaces
o sort
@b group
Pyth, 5 bytes
.gksc
Takes input as a Python string (i.e. wrapped in quotes, escaped quotes and slashes as necessary).
Explanation:
c Split (implied) input on whitespace
s Sum together
.gk Group by value
If you guarantee at least one space in the input, there's a 4-byte solution:
t.gk
Explanation:
.gk (Q) groups the characters in the string by their value
this sorts them by their value, which guarantees that spaces are first
t Remove the first element (the spaces)
><>, 49 bytes
i:0(?v
84}0~/&{!*
v!?: <}/?=&:&:<
>&1+&}aol1-?!;^
Very spaciously wasteful in the output, but i assume is still allowed given the lenience of the rules
Explanation:
i:0(?v Collects text from input
84}0~/&{!* adds 32 (first ascii starting at space) to register and 0 to stack
v!?: <}/?=&:&:< checks all characters to the current register, if equal:
o prints the character and continues looping
>&1+&}aol1-?!;^ when all characters are checked, adds 1 to register, prints a newline,
checks the stack length to halt the program if 0, and starts looping again
fit some things in pretty tight, even using jumps to get around some functions so i could run the pointer vertically.
Basically this puts each ASCII character on its own newline, and if none of that character exists, the line will be blank
Edit: i was wrong there was an error in the code what would cause it to never complete if there was a space in the input
Mathematica, 36 bytes
Built-in functions Gather and Characters do most of the work here.
Gather@Select[Characters@#,#!=" "&]&
Retina, 13 bytes
O`.
!`(\S)\1*
The sorting is very easy (it's a builtin), it's separating the letters that takes 9 bytes. Try it online!
The first line sOrts all matches of the regex . (which is every character), giving us !,Aaaaaabbcdhrr.
Match is the default stage for the last line of a program, and ! makes it print a linefeed-separated list of matches of the regex. The regex looks for one or more instances of a non-space character in a row.
Python, 107
Could be shortened by lambda, but later
x=sorted(input())
i=0
while i<len(x):x[i:]=[' '*(x[i]!=x[i-1])]+x[i:];i-=~(x[i]!=x[i-1])
print("".join(x))
Pyth, 6
.gk-zd
Try it here or run a Test Suite.
Pretty simple, -zd removes spaces from the input, and .gk groups each remaining element by its value. Unfortunately, I haven't found a way to make use of auto-fill variables. Note that the output is shown as Python strings, so certain characters (read: backslashes) are escaped. If you want it to be more readable, add a j to the beginning of the code.
Ruby, 41 + 1 = 42 bytes
+1 byte for -n flag.
gsub(/(\S)(?!.*\1)/){puts$1*$_.count($1)}
Takes input on stdin, e.g.:
$ echo 'Ah, abracadabra!' | ruby -ne 'gsub(/(\S)(?!.*\1)/){puts$1*$_.count($1)}'
A
h
,
c
d
bb
rr
aaaaa
!
JavaScript (ES6), 41 bytes
s=>[...s].sort().join``.match(/(\S)\1*/g)
Octave, 61 bytes
@(x)mat2cell(y=strtrim(sort(x)),1,diff(find([1 diff(+y) 1])))
This is an anoymous function that takes a string as input and outputs a cell arrray of strings.
How it works
sortsorts the input string. In particular, spaces will be at the beginning.strtrimremoves leading spaces.diff(+y)computes consecutive differences between characters (to detect group boundaries)...- ... so
diff(find([1 diff(+y) 1])gives a vector of group sizes. mat2cellthen splits the sorted string into chunks with those sizes.
Perl 6, 28 bytes
*.comb(/\S/).Bag.kv.map(*x*)
Note that Bag like a Hash or Set is unordered so the order of results is not guaranteed.
Explanation:
# Whatever lambda 「*」
# grab the characters
*.comb(
# that aren't white-space characters
/\S/
)
# ("A","h",",","a","b","r","a","c","a","d","a","b","r","a","!")
# Turn into a Bag ( weighted Set )
.Bag
# {"!"=>1,","=>1,"A"=>1,"a"=>5,"b"=>2,"c"=>1,"d"=>1,"h"=>1,"r"=>2}
# turn into a list of characters and counts
.kv
# ("!",1,",",1,"A",1,"a",5,"b",2,"c",1,"d",1,"h",1,"r",2)
# map over them 2 at a time
.map(
# string repeat the character by the count
* x *
)
# ("!",",","A","aaaaa","bb","c","d","h","rr")
Ruby, 46 bytes
->s{(s.chars-[' ']).uniq.map{|c|c*s.count(c)}}
My original full program version, 48 bytes after adding the n flag:
p gsub(/\s/){}.chars.uniq.map{|c|c*$_.count(c)}
Vim, 50, 46 bytes
i <esc>:s/./&\r/g
:sor
qq:%s/\v(.)\n\1/\1\1
@qq@qD
Explanation/gif will come later.
Haskell, 40 bytes
f x=[v:w|d<-['!'..],v:w<-[filter(==d)x]]
Usage example: f "Ah, abracadabra!"-> ["!",",","A","aaaaa","bb","c","d","h","rr"].
The pattern v:w matches only list with at least one element, so all characters not in the input are ignored.
Also 40 bytes:
import Data.List
group.sort.filter(>' ')
2sable, 7 bytes
Code:
Úð-vyÃ,
Explanation:
Ú # Uniquify the string, aabbcc would result into abc
ð- # Remove spaces
vy # For each character...
à # Keep those in the string, e.g. 'aabbcc', 'a' would result into 'aa'
, # Pop and print with a newline
Uses the CP-1252 encoding. Try it online!
Jelly, 5 bytes
ḟ⁶ṢŒg
It does return an array, just that when it is printed to STDOUT, the separator is gone.
This is indeed a function that can be called as such (in Jelly, each line is a function).
ḟ⁶ṢŒg
ḟ⁶ filter out spaces
Ṣ sort
Œg group