| Bytes | Lang | Time | Link |
|---|---|---|---|
| 008 | Pip Classic | 160817T043356Z | DLosc |
| 007 | Japt | 240919T140751Z | Shaggy |
| 096 | Rust | 240919T083825Z | user9403 |
| 008 | UiuaSBCS | 240921T180003Z | Europe20 |
| 004 | 05AB1E | 210216T231001Z | Makonede |
| 069 | Lua | 231112T174534Z | bluswimm |
| 040 | Befunge | 160813T013730Z | daniero |
| 004 | Thunno 2 | 230618T091210Z | The Thon |
| 026 | Zsh | 210217T085705Z | pxeger |
| 005 | Vyxal | 210217T112558Z | Razetime |
| 026 | Phooey | 210217T214642Z | EasyasPi |
| 091 | Javascript | 210217T090653Z | emanresu |
| 006 | MathGolf | 210217T153756Z | Kevin Cr |
| 049 | Javascript | 180306T200423Z | Sebasti& |
| 022 | SmileBASIC | 180306T192414Z | 12Me21 |
| nan | JavaScript ES6 | 171130T011435Z | l4m2 |
| 012 | MATL | 170515T144856Z | Sanchise |
| 014 | Dyalog APL | 160815T073111Z | Adá |
| 018 | Matlab | 160816T125727Z | paul.ode |
| 012 | IA32 machine code | 160912T005311Z | anatolyg |
| 016 | x86_64 machine language for Linux | 160813T050053Z | ceilingc |
| 066 | C# | 160812T142846Z | Scepheo |
| 099 | Lua | 160816T051940Z | Trebuche |
| 027 | PHP | 160812T135558Z | Business |
| 115 | LaTeX | 160815T191511Z | MH. |
| 030 | Perl 6 | 160816T022509Z | Brad Gil |
| 062 | Clojure | 160815T131745Z | Michael |
| 005 | Jelly | 160812T234211Z | Jonathan |
| 021 | perl | 160814T122335Z | Ben Avel |
| 007 | Actually | 160814T064255Z | user4594 |
| 056 | Java 7 | 160812T125855Z | Leaky Nu |
| 024 | Julia | 160813T034532Z | Dennis |
| 015 | k4 | 160813T033450Z | Aaron Da |
| 042 | Ruby | 160813T010358Z | daniero |
| 034 | Mathematica | 160813T004440Z | alephalp |
| 035 | C | 160813T002914Z | Lemon Dr |
| 005 | Jelly | 160812T151409Z | Dennis |
| 058 | Python 3 | 160812T232658Z | Destruct |
| 064 | ForceLang | 160812T233544Z | SuperJed |
| 024 | Perl | 160812T130036Z | Dada |
| 019 | Labyrinth | 160812T173052Z | Martin E |
| 057 | Python 2 | 160812T130030Z | DJMcMayh |
| 084 | PHP | 160812T125255Z | gabe3886 |
| 014 | ><> | 160812T162146Z | Sp3000 |
| 039 | TIBasic | 160812T144554Z | Timtech |
| 010 | CJam | 160812T161112Z | Martin E |
| 010 | MATL | 160812T123850Z | Luis Men |
| 033 | Julia | 160812T151550Z | Mama Fun |
| 023 | R | 160812T133704Z | user5957 |
| 006 | MATL | 160812T144527Z | Dennis J |
| 022 | Matlab | 160812T142315Z | Dennis J |
| 212 | Oracle SQL 11.2 | 160812T141141Z | Jeto |
| 116 | Batch | 160812T141040Z | Neil |
| 045 | JavaScript ES6 | 160812T140829Z | user8165 |
| 027 | R | 160812T123649Z | Rudier |
| 011 | CJam | 160812T134539Z | Martin E |
| 061 | Clojure | 160812T133332Z | cliffroo |
| 012 | CJam | 160812T130010Z | Business |
| 063 | zsh | 160812T132143Z | izabera |
| 031 | PowerShell v2+ | 160812T124826Z | AdmBorkB |
| 038 | q | 160812T124638Z | skeevey |
| 005 | Pyth | 160812T125403Z | FryAmThe |
| 006 | 05AB1E | 160812T124725Z | Adnan |
| 018 | J | 160812T125042Z | Leaky Nu |
| 072 | Python 2 | 160812T124331Z | atlasolo |
Pip Classic, 8 bytes
(zr*r*h)
z is a built-in for the lowercase alphabet, h for 100. r is a special variable: each time it is evaluated, it generates a random number with uniform distribution, 0 <= r < 1. Thus, r*r*h squares the uniform distribution and scales it a hundredfold (saving a character over using 26). The result is used to index into z, auto-truncated and with index wrapping.
Try it online (generates a frequency chart of 100,000 runs, taking about 20 seconds).
Japt, 7 bytes
;Bå+ ¬ö
;Bå+ ¬ö
;B :Uppercase alphabet
å :Cumulatively reduce by
+ : Concatenation
¬ :Join
ö :Get a random element
Rust, 116 96 bytes
use rand::Rng;let f=||b"abcdefghijklmnopqrstuvwxyz"[rand::thread_rng().gen_range(0..26)]as char;
UiuaSBCS, 9 8 bytes
+@a√⚂₆₇₆
Explanation
+@a√⚂₆₇₆
⚂₆₇₆ random number in the range [0, 676)
√ square root
+@a to letter
Probabilities
P(a) = 1/676 ≈ 0.001479
P(b) = 3/676 ≈ 0.004437
P(c) = 5/676 ≈ 0.007396
P(d) = 7/676 ≈ 0.010355
P(e) = 9/676 ≈ 0.013313
P(f) = 11/676 ≈ 0.016272
P(g) = 13/676 ≈ 0.01923
P(h) = 15/676 ≈ 0.022189
P(i) = 17/676 ≈ 0.025147
P(j) = 19/676 ≈ 0.028106
P(k) = 21/676 ≈ 0.031065
P(l) = 23/676 ≈ 0.034023
P(m) = 25/676 ≈ 0.036982
P(n) = 27/676 ≈ 0.03994
P(o) = 29/676 ≈ 0.042899
P(p) = 31/676 ≈ 0.045857
P(q) = 33/676 ≈ 0.048816
P(r) = 35/676 ≈ 0.051775
P(s) = 37/676 ≈ 0.054733
P(t) = 39/676 ≈ 0.057692
P(u) = 41/676 ≈ 0.06065
P(v) = 43/676 ≈ 0.063609
P(w) = 45/676 ≈ 0.066568
P(x) = 47/676 ≈ 0.069526
P(y) = 49/676 ≈ 0.072485
P(z) = 51/676 ≈ 0.075443
05AB1E, 4 bytes
AƶJΩ
AƶJΩ # full program
Ω # random character from...
J # joined...
A # "abcdefghijklmnopqrstuvwxyz"...
ƶ # with each character repeated 1-indexed index of character in string times
# implicit output
AƶJ generates the string 'abbcccddddeeeeeffffffggggggghhhhhhhhiiiiiiiiijjjjjjjjjjkkkkkkkkkkkllllllllllllmmmmmmmmmmmmmnnnnnnnnnnnnnnoooooooooooooooppppppppppppppppqqqqqqqqqqqqqqqqqrrrrrrrrrrrrrrrrrrsssssssssssssssssssttttttttttttttttttttuuuuuuuuuuuuuuuuuuuuuvvvvvvvvvvvvvvvvvvvvvvwwwwwwwwwwwwwwwwwwwwwwwxxxxxxxxxxxxxxxxxxxxxxxxyyyyyyyyyyyyyyyyyyyyyyyyyzzzzzzzzzzzzzzzzzzzzzzzzzz', so the chances are as follows:
a: 0.285%
b: 0.57%
c: 0.855%
d: 1.14%
e: 1.425%
f: 1.709%
g: 1.994%
h: 2.279%
i: 2.564%
j: 2.849%
k: 3.134%
l: 3.419%
m: 3.704%
n: 3.989%
o: 4.274%
p: 4.558%
q: 4.843%
r: 5.128%
s: 5.413%
t: 5.698%
u: 5.983%
v: 6.268%
w: 6.553%
x: 6.838%
y: 7.123%
z: 7.407%
Alternative, 4 bytes
AηJΩ
AηJΩ # full program
Ω # random character from...
J # joined...
η # prefixes of...
A # "abcdefghijklmnopqrstuvwxyz"
# implicit output
AηJ generates the string 'aababcabcdabcdeabcdefabcdefgabcdefghabcdefghiabcdefghijabcdefghijkabcdefghijklabcdefghijklmabcdefghijklmnabcdefghijklmnoabcdefghijklmnopabcdefghijklmnopqabcdefghijklmnopqrabcdefghijklmnopqrsabcdefghijklmnopqrstabcdefghijklmnopqrstuabcdefghijklmnopqrstuvabcdefghijklmnopqrstuvwabcdefghijklmnopqrstuvwxabcdefghijklmnopqrstuvwxyabcdefghijklmnopqrstuvwxyz', so the chances are as follows:
a: 7.407%
b: 7.123%
c: 6.838%
d: 6.553%
e: 6.268%
f: 5.983%
g: 5.698%
h: 5.413%
i: 5.128%
j: 4.843%
k: 4.558%
l: 4.274%
m: 3.989%
n: 3.704%
o: 3.419%
p: 3.134%
q: 2.849%
r: 2.564%
s: 2.279%
t: 1.994%
u: 1.709%
v: 1.425%
w: 1.14%
x: 0.855%
y: 0.57%
z: 0.285%
Befunge, 40 bytes
Revisiting this 7 years later, I realized I I could just add the whole alphabet in one string and pop off a random amount of letters before printing. Suddenly it beats Python!
"ZYXWVUTSRQPONMLKJIHGFEDCBA"> #$?:#@ #,_
Probabilities are the same as before; Starting from A, there is a 1/4 chance of printing the top of the stack, 2/4 to try again, and 1/4 to pop off one letter and repeat. If it somehow manages to move past Z it just starts over again with A. Trying a few times, the highest I got was an E.
Befunge, 168 164 bytes
More compact than the first one, with a little different probabilities: The first ? have a 1/4 chance of printing an A on "first try", 2/4 chance to come back to the same ?, and 1/4 to move to the next. The rest of the ?s each have 1/4 chance of printing the letter underneath them, 1/4 to try again, 1/4 moving to the next letter, 1/4 moving to the previous. Again, the probability of printing an A is a lot higher than printing a Z.
??????????????????????????>
""""""""""""""""""""""""""
ABCDEFGHIJKLMNOPQRSTUVWXYZ
""""""""""""""""""""""""""
>>>>>>>>>>>>>>>>>>>>>>>>>>,@
##########################
Befunge, 186 bytes
Obviously not gonna win with this, but I think it's an interesting answer nonetheless :)
v and > steers the cursor respectively downwards and to the right.
The ? operator sends the cursor off in one of four directions randomly. The first ? is "blocked" by v and > in two directions, so it only has two way to go: Either to print the A, or down to the next ?. So from the first ? alone there is a 50% chance of printing an A.
The next ? has a 1/3 chance of printing a B, 1/3 of going back up, and 1/3 of going further down. Etc etc.
It should be quite obvious that the higher letters have a much larger chance of being printed than the lower ones, but I'm not exactly sure what each letter's chances are.
Some help with the exact math would be appreciated :)
At least there's a 1/2 * 1/3^25 chance that the cursor moves all the way down to the Z on the first try, but I'm uncertain how the chances of the cursor moving up and down affects each letter.
,@ prints and quits.
v
>?"A"v
>?"B"v
>?"C"v
>?"D"v
>?"E"v
>?"F"v
>?"G"v
>?"H"v
>?"I"v
>?"J"v
>?"K"v
>?"L"v
>?"M"v
>?"N"v
>?"O"v
>?"P"v
>?"Q"v
>?"R"v
>?"S"v
>?"T"v
>?"U"v
>?"V"v
>?"W"v
>?"X"v
>?"Y"v
>?"Z">,@
Thunno 2, 4 bytes
ẠƒJɼ
This takes the prefixes of the lowercase alphabet, joins them, and takes a random character from this string. This means that the probabilities are as follows:
a: \$26/351\$b: \$25/351\$- \$...\$
y: \$2/351\$z: \$1/351\$
Ạ # Push the lowercase alphabet -> "abcdefghijklmnopqrstuvwxyz"
ƒ # Get the prefixes of this string -> ["a","ab",...,"abcdefghijklmnopqrstuvwxyz"]
J # Join them into a single string -> "aababc...abcdefghijklmnopqrstuvwxyz"
ɼ # Take a random character from this string
# Implicit output
Zsh, 26 bytes
eval shuf -en1 {{a..z}..z}
Try it online! Includes a basic frequency analysis.
Explanation:
{a..z}- construct the stringa b ... z{{a..z}..z}- construct the string{a..z} {b..z} ... {z..z}evaluate that string - executesshuf -en1 a b ... z b c ... z c d ... z ... y z zshuf -en1- picks one of those letters at random. In the pool,zis repeated 26 times,y25 times, etc., which creates the distinct probabilities.
Phooey, 26 bytes
~?675@(&>@+1@<--@@^)>+63$c
The demo contains a simple infinite loop which resets the tape (this program expects a clean tape and doesn't clean up lul)
Similar to a lot of other answers, this generates a number from \$0-675\$ and uses roughly \$\lfloor \sqrt{n}\rfloor\$ to select the letter with varying probability.
Unfortunately, AFAICT, there is no way of doing a square root automatically since the pow operator uses integers. Maybe there is a fixed point method, but idk yet.
However, the naïve subtraction method works and is probably shorter than any other solution. It's only going to be running a few iterations, so the inefficiency isn't that bad.
int64_t isqrt(int64_t n)
{
int64_t d = 0;
while (n >= 0) {
n -= d;
d += 1;
n -= d;
}
return d - 1;
}
My implementation actually has an off-by-one problem with my loop condition check. I use \$x^x\$ (@^) instead of \$2^x\$ (@&2^) which is the "proper" (at least, in Phooey) way to check for negatives, and when \$x = -1\$, it will report a false negative (or is it a false positive? 🤨), as \${-1}^{-1} = {-1}, {-1} \ne 0\$.
HOWEVER, that doesn't affect the output's randomness. It just means that Z will appear once instead of A and we need \$d - 2\$ instead of \$d - 1\$.
With all values from \$0-675\$ tested, this is the frequency:
A 3 B 5
C 7 D 9
E 11 F 13
G 15 H 17
I 19 J 21
K 23 L 25
M 27 N 29
O 31 P 33
Q 35 R 37
S 39 T 41
U 43 V 45
W 47 X 49
Y 51 Z 1
How it works:
~?675@(&>@+1@<--@@^)>+63$c
~?675 # Generate a random integer between 0 and 675 inclusive
@ # Push the initial n to the stack
# Begin our naïve semi-sqrt loop
( ) # while n >= 0
& # Pop n from the stack
> # Move left to d
@ # Push d
+1 # Increment d
@ # Push d + 1
< # Move back to n
-- # Subtract d and d + 1, popping them
# Use a modified method I found in my Brexit post to check for < 0
@ # Save a copy of n
@^ # Calculate n^n using double<->int64 conversion
# The current cell will contain zero if n < -1, or nonzero otherwise.
# Use that as our loop condition.
> # Move to d
+63 # d += 'A' - 2
$c # print as char
Javascript, 93 91 bytes
Yes there is a shorter one, but that does it differently. Also I spent half an hour on this so I'm not giving up.
q=>'abcdefghijklmnopqrstuvwxyz'.split``.map((i,k)=>i.repeat(k)).join``[Math.random()*351|0]
Explained:
q=> // define function, meaningless arg saves a byte
'abcdefghijklmnopqrstuvwxyz'.split`` // get each alphabet character in array
.map((i,k)=>i.repeat(k)) //replace each with it repeated index times
.join``[Math.random()*351|0] //turn to string and get random character.
Probability:
a - 1/351
b - 2/351
c - 3/351
Etcetera.
Note: according to this comment, I don't have to use a function declaration if it isn't recursive.
MathGolf, 6 bytes
▄mÅî*w
Explanation:
▄ # Push the lowercase alphabet
m # Map over each letter
Å # using the following two characters as inner code-block:
î # Push the 1-based map-index
* # Repeat the current character that many times
w # After the map: pop and push a random character from this string
# (after which the entire stack joined together is output implicitly as result)
Same probability as most other answers:
- a: \$\frac{1}{351}\$
- b: \$\frac{2}{351}\$
- ...
- y: \$\frac{25}{351}\$
- z: \$\frac{26}{351}\$
Javascript, 49 bytes
f=()=>String.fromCharCode(65+Math.random()**2*26)
SmileBASIC, 26 22 bytes
I think it's unfair that most of these are biased towards earlier letters.
Here's one that prints Z the most:
?CHR$(90-RND(RND(27)))
JavaScript ES6, 42 Bytes, modified from user81655's solution:
_=>(0|10+26*Math.random()**2).toString(36)
MATL, 12 bytes
1Y2toY"tnYr)
Explanation
1Y2 % Pushes the alphabet A...Z
to % Make a numeric copy [65 ... 90]
Y" % Run length decoding: 65 A's, 66 B's, etc. Let's call this [S]
nYr % Random number between 1 and length of [S], let's call this [i]
t ) % Index into a copy of [S] at the [i]'th position. Implicit display.
The selection from [S] is according to a uniform distribution, but since each letter in the alphabet occurs a distinct number of times in [S], the resulting distribution is also distinct for each letter in the alphabet.
Dyalog APL, 14 bytes
See this meta post for information about the code page.
(?351)⊃⎕A/⍨⍳26
Gives instant results. Works by selecting an evenly distributed random character among "ABBCCCDDDD..."
(?351) RandInt(1,351)
⊃picks among
⎕A "ABC...Z"
/⍨ element-by-element replicated
⍳26 {1, 2, 3, ..., 26} times
Matlab, 24 18 bytes
char(floor(26*rand^2+65))
it looks like using floor(x) isn't necessary as char also takes non-integer inputs
char(25*rand^2+65)
not using ['' x] instead of char(x) so I won't get warning: implicit conversion from numeric to char for "purer" output.
rand yields a uniformly distributed random number in the interval (0,1) but rand^2 isn't uniformy distributed anymore, the probability density function follows , see here.
with (b-a)*rand+a one can shift the interval of the distribution from (0,1) to (a,b), this also works with rand^2.
because i use floor i need to stretch the interval to (65,91) so i don't lose "Z"
It might no be the shortest answer but i like the approach with using a uniform random distribution to get a non-uniform random distribution.
Below is the count for each generated numbers after 20000 iterations (using my first version of my answer).
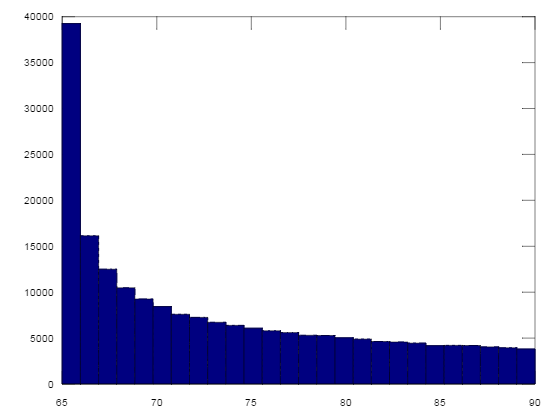
IA-32 machine code, 12 bytes
Hexdump:
0F C7 F0 F6 E4 88 E0 D4 1A 04 61 C3
Source code:
rdrand eax
mul ah
mov al, ah
aam 26
add al, 'a'
ret
Or, as a C expression (assuming r is a uniformly generated random number of type uint32_t):
(r & 0xff) * ((r >> 8) & 0xff) / 0x100 % 26 + 'a'
Running this expression on values in the range 0...65535 gives the probabilities of the letters:
z 1968
y 2012
x 2068
w 2076
v 2134
u 2140
t 2194
s 2209
r 2233
q 2292
p 2335
o 2358
n 2410
m 2437
l 2475
k 2545
j 2571
i 2654
h 2696
g 2738
f 2818
e 2922
d 2955
c 3098
b 3241
a 3957
x86_64 machine language for Linux, 15 19 17 16 bytes
L1:
48 0f c7 f0 rdrand %rax
f3 48 0f b8 c0 popcnt %rax,%rax
3c 1a cmp $0x1a,%al
7d f3 jge L1
04 41 add $0x41,%al
c3 retq
This requires support for the POPCNT and RDRAND instructions.
A uniform distributed random number is generated, the number of 1's in that number is counted, if that number is less than 26, a letter is returned. One will need to let the code run a long time before one sees a letter A.
To test, try something like
#include<stdio.h>
#define TEST "\x48\xf\xc7\xf0\xf3\x48\xf\xb8\xc0\x3c\x1a\x7d\xf3\4\x41\xc3"
int main(){
int hist[26]={0};
for(int i=0;i<10000000;i++){
hist[ ((int(*)())TEST)() - 'A' ]++;
}
for(int i=0;i<26;i++){
printf("%c %d\n", 'A'+i, hist[i] );
}
}
Sample output
A 0
B 0
C 0
D 0
E 0
F 0
G 0
H 0
I 0
J 0
K 0
L 8
M 32
N 137
O 511
P 1639
Q 5188
R 14475
S 37539
T 91670
U 205638
V 431381
W 842259
X 1536776
Y 2626524
Z 4206223
The analytical expression for the probability of each letter can be derived from the binomial distribution. The letter A is assigned index k=0, B is assigned k=1 and so on.
/ \
| 64 |
| k |
\ /
p(k)=------------
25
--- / \
\ | 64 |
/ | i |
--- \ /
i=0
p(A)~1.0483e-18
p(B)~6.7093e-17
p(C)~2.1134e-15
p(D)~4.3678e-14
p(E)~6.6608e-13
p(F)~7.9930e-12
p(G)~7.8598e-11
p(H)~6.5124e-10
p(I)~4.6401e-09
p(J)~2.8872e-08
p(K)~1.5879e-07
p(L)~7.7953e-07
p(M)~3.4429e-06
p(N)~1.3772e-05
p(O)~5.0169e-05
p(P)~1.6723e-04
p(Q)~5.1214e-04
p(R)~1.4460e-03
p(S)~3.7758e-03
p(T)~9.1413e-03
p(U)~2.0568e-02
p(V)~4.3095e-02
p(W)~8.4231e-02
p(X)~1.5381e-01
p(Y)~2.6276e-01
p(Z)~4.2042e-01
C#, 68 66 bytes
Thanks to Leaky Nun for fixing the chance distribution.
var r=new Random();char f(char c='A')=>c<'Z'&r.Next(3)>0?f(++c):c;
Surprisingly short for a C# answer.
It defines a function f that returns a random character between the given one and Z. It has a 1/3 chance of returning the current character, otherwise it recurses on the next. If the current character is Z, it always returns. Default parameter is A, so calling it without any argument satisfies the challenge.
The resulting chances follow 2^(n-1) / 3^n:
A: 1/3
B: 2/9
C: 4/27
D: 8/81
...
Y: 16777216/847288609443
Z: 67108864/2541865828329
Lua, 100 99 bytes
s="A"math.randomseed(os.time())for i=66,90 do
s=.6<math.random()and string.char(i)or s end
print(s)
Not really competitive, but still an interesting algorithm I think.
PHP, 44 36 29 27 bytes
Crossed out 44 is still regular 44 ;(
Thanks to insertusernamehere, Petah, and Crypto for all the help
<?=chr(65+rand(0,675)**.5);
It chooses a random number between 0 and 675 (=262-1), takes its square root, and floors it (the chr function converts its argument to an integer). Since the squares have different intervals between them, the probability of each number being chosen is distinct. Every n is chosen with probability (2n+1)/676.
Adding 65 to this number gives you a random character from A to Z.
LaTeX, 122 115 bytes
-7 bytes by replacing pgfmathparse{Hex(...)} with pgfmathHex{...}.
Or, if I'm allowed to skip the document class definition & setup, and just count the package import and functional code: 65 bytes.
pgfmathHex parses the expression and its (hexadecimal) result is then fed into \char which turns the code point into a unicode character. The expression itself is identical to many other answers here.
\documentclass{book}\usepackage{tikz}\begin{document}\pgfmathHex{65+sqrt(rnd)*26}\char"\pgfmathresult\char"\pgfmathresult\end{document}
Ungolfed (with cherry-picked for loop for page-filling output):
\documentclass{book}
\usepackage{tikz}
\begin{document}
\noindent
\foreach \n in {0,...,1513}
{
\pgfmathHex{65+sqrt(rnd)*26}\char"\pgfmathresult
}
\end{document}
Output (w/ free page number :) ):

Perl 6, 30 bytes
{('a'..'z'Zxx 1..*).flat.pick}
Explanation:
# bare block lambda
{
(
'a' .. 'z' # the alphabet
Z[xx] # zipped 「Z」 using the list repeat operator 「xx」
1 .. * # with 1 to 26
# ((a)(b b)(c c c)(d d d d)(e e e e e)...
)
.flat # flatten it from a list of lists into a single list
.pick # pick an element from the list
}
Clojure, 62 bytes
(loop[i 65](if(or(> i 89)(neg?(rand)))(char i)(recur(inc i))))
This is somewhat stupid shortcut. The probability of exact zero double - the only (rand) to not break on condition (pos? x) - is around 1/(2^62) [source].
So chance for letter char(65+N) is around (1/(2^62))^N, slightly higher for Z (because it is last).
With (rand-int 2) - 6 more bytes - it becomes testable.
Jelly, 5 bytes
ØAxJX
(Equal score, but a different method, to an existing Jelly solution by Dennis.)
The probability of yielding each letter is it's 1-based index in the alphabet divided by 351 - the 26th triangular number:
- P(
A) = 1 / 351, P(B) = 2 / 351, ..., P(Z) = 26 / 351.
Since 1+2+...+26 = 351, P(letter) = 1.
Implementation:
ØAxJX - no input taken
ØA - yield the alphabet: 'ABC...Z'
J - yield [1,...,len(Left)]: [1,2,3,...26]
x - Left times Right: 'abbccc...zzzzzzzzzzzzzzzzzzzzzzzzzz'
X - choose random element from Left
Test it on TryItOnline or get the distribution of 100K runs (code credit to Dennis)
perl, 21 bytes
say+(A..Z)[rand$$%27]
Needs -M5.010 or -E to run :
perl -E 'say+(A..Z)[rand$$%27]'
How it works : (A..Z) is an array. $$ is process ID, which introduces some randomness. $$%27 is a number between 0 and 26 (inclusive, and roughly evenly spread). Calling rand on that produces a number between 0 and 26 (inclusive at 0, exclusive at 26), but biased towards smaller numbers. We then use that number for an array lookup, which we print.
Opportunities for improvement :
$$ is random, but not cleanly random. We know that the chance of getting particular numbers differs, but not by much, and not in ways that are easy to predict cleanly. Therefore, the possibility of getting different each letter is probably not identical, but it's very close. If (and only if) we accept that probability{ $$%26 == x } is different for all x, then we could replace "rand$$%27" with "$$%26".
Alternately, we could replace "rand$$%27" with (for example) "26*sin$$", and save one character. This gives a much less regular spread than simply "$$%26":
perl -E 'for(1..32768){say+(A..Z)[26*sin$_]}' | sort | uniq -c
832 A
3269 B
1648 C
1360 D
1183 E
1133 F
1043 G
1071 H
959 I
978 J
985 K
939 L
926 M
950 N
924 O
939 P
985 Q
977 R
959 S
1072 T
1043 U
1135 V
1182 W
1360 X
1647 Y
3269 Z
But if you check, you'll see that it's not perfect. There are three pairs of numbers that have the same probability as each other: K&Q, I&S, L&P.
(If you use actual PIDs, then depending on what processes are actually running, and depending on the highest allowable pid on your machine, you might get more clashes, or less.)
"15*sin$$" works better, only 2 clashes - but that is still 2 clashes. (Any number between 13 and 26 will work, in the sense of producing all 26 letters, because sin(x) spans -1 to +1 and perl treats negative number array look-ups as starting from the array end).
There might be some way of getting all 26 numbers, with different probabilities, using less (or no more) than the 8 characters that "rand$$%27" needs. But if so, it isn't coming to me.
Actually, 7 bytes
ú#;╚♀MJ
This answer uses the same approach as Dennis's Jelly answer.
Explanation:
ú#;╚♀MJ
ú# lowercase English alphabet, as a list (this is to dodge a bug with the shuffle command)
;╚ duplicate, shuffle
♀M pairwise maximum
J random element
Java 7, 62 57 56 bytes
5 bytes thanks to Poke.
1 byte thanks to trichoplax.
char r(){return(char)(65+(int)Math.sqrt(Math.random()*676));}
char r(){return(char)(65+Math.sqrt(Math.random()*676));}
char r(){return(char)(65+Math.sqrt(Math.random())*26);}Frequency diagram (1e6 runs, scaling factor 1/1000)
A: *
B: ****
C: *******
D: **********
E: *************
F: ****************
G: *******************
H: **********************
I: *************************
J: ***************************
K: ******************************
L: **********************************
M: ************************************
N: ***************************************
O: *******************************************
P: *********************************************
Q: ************************************************
R: ***************************************************
S: ******************************************************
T: *********************************************************
U: ************************************************************
V: ***************************************************************
W: ******************************************************************
X: *********************************************************************
Y: ************************************************************************
Z: ***************************************************************************
Julia, 24 bytes
!c='a':c|>rand;c()=!!'z'
How it works
The function c() simply calls ! twice, with initial argument z. In turn !c creates a character range from a to its argument c and pseudo-randomly selects a character from this range. The distribution of probabilities is as follows.
Let x1, …, x26 denote the letters of the alphabet in their natural order. Select a letter Y among these, uniformly at random, then select a letter X from L1, … Y, also uniformly at random.
Fix n and k in 1, …, 26.
If n ≤ k, then p(X = xn | Y = xk) = 1/k. On the other hand, if n > k, then p(X = xn | Y = xk) = 0.
Therefore, p(X = xn) = Σ p(Y = xk) * p(X = xn | Y = xk) = 1/26 · (1/n + ⋯ + 1/26), giving the following probability distribution.
p(X = a) = 103187226801/696049754400 ≈ 0.148247
p(X = b) = 76416082401/696049754400 ≈ 0.109785
p(X = c) = 63030510201/696049754400 ≈ 0.090555
p(X = d) = 54106795401/696049754400 ≈ 0.077734
p(X = e) = 47414009301/696049754400 ≈ 0.068119
p(X = f) = 42059780421/696049754400 ≈ 0.060426
p(X = g) = 37597923021/696049754400 ≈ 0.054016
p(X = h) = 33773473821/696049754400 ≈ 0.048522
p(X = i) = 30427080771/696049754400 ≈ 0.043714
p(X = j) = 27452509171/696049754400 ≈ 0.039440
p(X = k) = 24775394731/696049754400 ≈ 0.035594
p(X = l) = 22341654331/696049754400 ≈ 0.032098
p(X = m) = 20110725631/696049754400 ≈ 0.028893
p(X = n) = 18051406831/696049754400 ≈ 0.025934
p(X = o) = 16139182231/696049754400 ≈ 0.023187
p(X = p) = 14354439271/696049754400 ≈ 0.020623
p(X = q) = 12681242746/696049754400 ≈ 0.018219
p(X = r) = 11106469546/696049754400 ≈ 0.015956
p(X = s) = 9619183746/696049754400 ≈ 0.013820
p(X = t) = 8210176146/696049754400 ≈ 0.011795
p(X = u) = 6871618926/696049754400 ≈ 0.009872
p(X = v) = 5596802526/696049754400 ≈ 0.008041
p(X = w) = 4379932326/696049754400 ≈ 0.006293
p(X = x) = 3215969526/696049754400 ≈ 0.004620
p(X = y) = 2100505176/696049754400 ≈ 0.003018
p(X = z) = 1029659400/696049754400 ≈ 0.001479
Ruby, 42 bytes
$><<(?A..?Z).flat_map{|c|[c]*c.ord}.sample
Quite straightforward: Generate 65 A's; 66 B's; ... 90 Z's, and randomly pick one of the letters generated.
Mathematica, 34 bytes
RandomChoice[Range@26->Alphabet[]]
RandomChoice[wlist -> elist] gives a random choice of elist weighted by wlist.
C, 35 bytes
This program assumes RAND_MAX is (2^32 / 2) - 1 as it is on gcc by default. Compile with the -lm flag to link the sqrt function. The output is written to stdout as capital letters without trailing newlines.
f(){putchar(sqrt(rand())/1783+65);}
Optionally, if RAND_MAX is (2^16 / 2) - 1, a shorter 32 byte version can be used:
f(){putchar(sqrt(rand())/7+65);}
Just for fun, I also made a version that does not use the sqrt function or require the math library included (this one must have RAND_MAX as (2^32 / 2) - 1), but it ended up being longer even though I thought it was pretty cool:
f(){float r=rand()/64+1;putchar((*(int*)&r>>23)-62);}
Explanation
[First Program]
For the first two using sqrt, the function simply maps the range [0, RAND_MAX) to [0, 25] through division, and then adds 65 (ASCII A) to the value to shift it into the ASCII alphabet before outputting it.
[Second Program]
The second program is a bit more complex as it does a similar strategy, but without the sqrt operator. Since a floating point's exponent bits are automatically calculated upon assigning an integer, they can effectively be used as a crude way to get the base 2 logarithm of a number.
Since we only want the range up to RAND_MAX to reach an encoded exponent value of 25, the calculation (2^32 / 2 - 1) / (2 ^ 25) gives us just about 64, which is used during the division of rand to map it to this new range. I also added 1 to the value as 0's floating point representation is rather odd and would break this algorithm.
Next, the float is type-punned to an integer to allow for bitshifting and other such operations. Since in IEEE 754 floating point numbers the exponent bits are bits 30-23, the number is then shifted right 23 bits, cutting off the mantissa and allowing the raw exponent value to be read as an integer. Do note that the sign bit is also beyond the exponent bits, but since there are never any negatives it does not have to be masked out.
Rather than adding 65 to this result like we did before however, floating point exponents are represented as an unsigned 8 bit integer from 0 to 255, where the exponent value of 0 is 127 (Simply subtract 127 to get the actual "signed" exponent value). Since 127 - 65 is 62, we instead simply subtract 62 to both shift it out of this floating point exponent range and into the ASCII alphabet range all in one operation.
Distribution
I'm not math expert so I cannot say for sure the exact formula for these distributions, but I can (and did) test every value on the range [0, RAND_MAX) to show that the distance between where one letter's range ends and the other begins are never the same. (Note these tests assume the (2^32 / 2) - 1) random maximum)
[First Program]
Letter - Starting Location
A - 0
B - 3179089
C - 12716356
D - 28611801
E - 50865424
F - 79477225
G - 114447204
H - 155775361
I - 203461696
J - 257506209
K - 317908900
L - 384669769
M - 457788816
N - 537266041
O - 623101444
P - 715295025
Q - 813846784
R - 918756721
S - 1030024836
T - 1147651129
U - 1271635600
V - 1401978249
W - 1538679076
X - 1681738081
Y - 1831155264
Z - 1986930625
[Second Program]
Letter - Starting Location
A - 0
B - 64
C - 192
D - 448
E - 960
F - 1984
G - 4032
H - 8128
I - 16320
J - 32704
K - 65472
L - 131008
M - 262080
N - 524224
O - 1048512
P - 2097088
Q - 4194240
R - 8388544
S - 16777152
T - 33554368
U - 67108800
V - 134217664
W - 268435392
X - 536870848
Y - 1073741760
Z - 2147483520
Jelly, 5 bytes
ØA»ẊX
How it works
ØA«ẊX Main link. No arguments.
ØA Set argument and return value to the alphabet.
Ẋ Shuffle it.
» Yield the maximum of each letter in the sorted alphabet, and the
corresponding character in the shuffled one.
X Pseudo-randomly select a letter of the resulting array.
Background
Let L0, …, L25 denotes the letters of the alphabet in their natural order, and S0, …, S25 a uniformly at random selected permutation of L. Define the finite sequence M by Mn = max(Ln, Sn).
Fix n in 0, … 25 and define k as the index such that Ln = Sk.
With probability 1 / 26, Ln = Sn and n = k, so Mn = Ln and Ln occurrs once in M.
With probability 25 /26, Ln ≠ Sn and n ≠ k. In this case, the following happens.
With probability n / 25, Sn is one of L0, …, Ln - 1, so Ln > Sn and Mn = Ln.
Independently, also with probability n / 25, k is one of 0, … n - 1, so Sk > Lk and Mk = Sk = Ln.
Thus, the expected number of occurrences of Ln in M is 1/26 + 25/26 · (n/25 + n/25) = (2n + 1)/26.
Finally, if we now select a term m of M uniformly at random, the letter Ln we be chosen with probability (2n + 1)/26 / 26 = (2n + 1)/676.
This yields the following distribution of probabilities.
p(m = A) = 1/676 ≈ 0.00148
p(m = B) = 3/676 ≈ 0.00444
p(m = C) = 5/676 ≈ 0.00740
p(m = D) = 7/676 ≈ 0.01036
p(m = E) = 9/676 ≈ 0.01331
p(m = F) = 11/676 ≈ 0.01627
p(m = G) = 13/676 ≈ 0.01923
p(m = H) = 15/676 ≈ 0.02219
p(m = I) = 17/676 ≈ 0.02515
p(m = J) = 19/676 ≈ 0.02811
p(m = K) = 21/676 ≈ 0.03107
p(m = L) = 23/676 ≈ 0.03402
p(m = M) = 25/676 ≈ 0.03698
p(m = N) = 27/676 ≈ 0.03994
p(m = O) = 29/676 ≈ 0.04290
p(m = P) = 31/676 ≈ 0.04586
p(m = Q) = 33/676 ≈ 0.04882
p(m = R) = 35/676 ≈ 0.05178
p(m = S) = 37/676 ≈ 0.05473
p(m = T) = 39/676 ≈ 0.05769
p(m = U) = 41/676 ≈ 0.06065
p(m = V) = 43/676 ≈ 0.06361
p(m = W) = 45/676 ≈ 0.06657
p(m = X) = 47/676 ≈ 0.06953
p(m = Y) = 49/676 ≈ 0.07249
p(m = Z) = 51/676 ≈ 0.07544
You can empirically verify the distribution by calling the link 100,000 times (takes a few seconds).
Python 3, 58 bytes
from random import*;print(chr(randint(65,randint(65,91))))
it is like that perl answer.
ForceLang, 64 bytes
Noncompeting, uses language features (the string.char method) that postdate the question.
set s math.sqrt 676.mult random.rand()
io.write string.char 65+s
Perl, 24 bytes
-4 bytes thanks to @Martin Ender
-1 byte thanks to @Dom Hastings
say+(A..Z)[rand rand 26]
Needs -M5.010 or -E to run :
perl -E 'say+(A..Z)[rand rand 26]'
Running the following code will show the occurrence of each letter :
perl -MData::Printer -E '$h{(A..Z)[rand rand 26]}++ for 1 .. 1_000_000;$h{$_} = int($h{$_} / 100) / 100 for A .. Z;p %h;'
A 16.4
B 11.02
C 8.99
...
Z 0.07
How it works : I guess the code is pretty explicit, but still : it chooses a random number between 0 and rand 26. So there is a much higher probability that numbers close to 0 (letter A) are choosen.
Labyrinth, 19 bytes
__v6%_65+.@
" )
"^2
This is a loop which, at each iteration, either a) increments a counter which starts at zero or b) terminates, both with probability 50%. At the end of the loop, the counter is taken modulo 26 and added to 65 to give a letter between A and Z.
This gives a probability for A just a bit over 50%, B just a bit over 25% and so on up to Z just a bit over 1/226. In theory, there is the possibility of this running forever, but this event has probability zero as required by the challenge (in practice that's probably not possible anyway because the PRNG will return both possible results at some point over its period).
Python 2, 58 57 bytes
from random import*
print chr(int(65+(random()*676)**.5))
Explanation: this generates a random floating point number in the interval [0, 676), takes the square root and then floors it. Then it adds 65 (the ascii value of "A"), converts it to a char, and prints it.
This gives each number from 0 to 25 a distinct probability. To understand why, think about it like this. How many numbers, ignoring non-integers, when you take the square root and floor give 0? Only one number will (zero). This means that zero has a probability of 1/676. How many numbers will produce 1? 3 will, 1, 2, and 3. This means one has a probability of 3/676. A two can be produced with a 4, 5, 6, 7, or 8, giving it probability 5, a three has probability 7, etc. and since the difference between consecutive squares increases steadily by two, this pattern continues for every number up to 25 (Z).
1 byte saved thanks to leaky nun!
PHP, 92 84 bytes
for($i=65,$x=0;$i<91;$a.=str_repeat(chr($i++),$x))$x++;echo substr($a,rand(0,$x),1);
Builds a string of all letters, repeated the number of times through the loop we are, and then picks a letter from that string at random. Letters later in the alphabet have a higher probability as a result
Thanks to insertusernamehere for shaving off bytes
outcome probabililities (ordered by %)
A => 0.29%
B => 0.62%
C => 0.82%
D => 1.15%
E => 1.50%
F => 1.65%
G => 2.00%
H => 2.27%
I => 2.52%
J => 2.80%
K => 3.13%
L => 3.47%
M => 3.72%
N => 3.93%
O => 4.15%
P => 4.59%
Q => 4.81%
R => 5.17%
S => 5.44%
T => 5.68%
U => 6.06%
V => 6.13%
W => 6.60%
X => 6.95%
Y => 7.17%
Z => 7.38%
><>, 14 bytes
lx
;>dd+%'A'+o
><> is a toroidal 2D language, and the distinct probabilities part just naturally happens due to the language's only source of randomness. Try it online!
The relevant commands are:
[Row 1]
l Push length of stack
x Change the instruction pointer direction to one of up/down/left/right
This gives a 50/50 chance of continuing on the first row (moving
left/right) or going to the next row (moving up/down, wrapping if up)
[Row 2]
> Change IP direction to right
dd+% Take top of stack mod 26 (dd+ = 13+13 = 26)
'A'+ Add 65
o Output as character
; Halt
Thus the output probabilities are:
A: 1/2^1 + 1/2^27 + 1/2^53 + ... = 33554432 / 67108863 ~ 0.50000000745
B: 1/2^2 + 1/2^28 + 1/2^54 + ... = half of chance for A
C: 1/2^3 + 1/2^29 + 1/2^55 + ... = half of chance for B
...
Z: 1/2^26 + 1/2^52 + 1/2^78 + ... = half of chance for Y
TI-Basic, 39 bytes
sub("ABCDEFGHIJKLMNOPQRSTUVWXYZ",int(26^rand),1
rand generates a uniform value in (0,1]. This gives 26^rand a different probability to equal the integers from 1 to 26.
Older version, 45 bytes
sub("ABCDEFGHIJKLMNOPQRSTUVWXYZAAA",1+int(4abs(invNorm(rand))),1
Limited precision of the TI-Basic integers limits normal distributions to generating numbers within µ±7.02σ (see randNorm(). So we get the absolute value of a random number with µ 0 and σ 1, multiplying by four to increase the practical range mentioned before to µ±28.08σ. Then, we floor the value and add 1, since sub( is 1-indexed, giving us a range from 1-29 with different probabilities of each.
CJam, 10 bytes
CJam approach #3...
26mr)mr'A+
This creates a uniformly random number x between 1 and 26 and then uses that to create a uniformly random number between 0 and x-1 which is added to A. This biases results towards smaller characters.
MATL, 10 bytes
1Y2rU26*k)
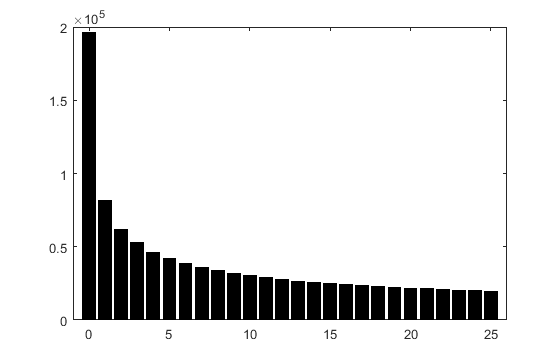
The code generates a uniform random variable on the interval (0,1) (r) and computes its square (U). This results in a non-uniform, decreasing probability density. Multiplying by 26 (26*) ensures that the result is on the interval (0,26), and rounding down (k) produces the values 0,1,...,25 with decreasing probabilities. The value is used as an index ()) into the uppercase alphabet (1Y2). Since MATL uses 1-based modular indexing, 0 corresponds to Z, 1 to A, 2 to B etc.
As an illustration that the probabilities are distinct, here's a discrete histogram resulting from 1000000 random realizations. The graph is produced by running this in Matlab:
bar(0:25, histc(floor(26*rand(1,1e6).^2), 0:25))
Julia, 33 bytes
f()=['A':'Z'][ceil(26*√rand())]
Applies the square root to RNG.
Graph showing distribution:
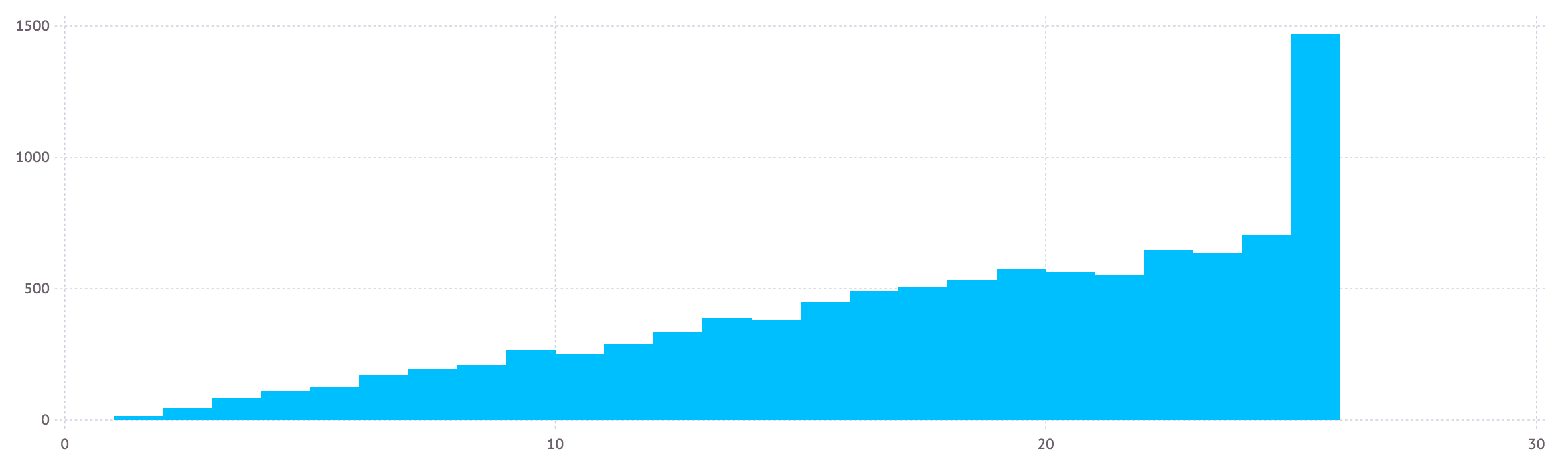 Generated with:
Generated with:
using Gadfly
plot(x=ceil(26*√rand(10000)),Geom.histogram)
R, 23 bytes
sample(LETTERS,1,,1:26)
Just 'samples' a letter from a builtin. the 1:26 is a vector of weights giving each letter a different probability.
MATL, 6 Characters
1Y2Xr)
Explanation:
Xr Take a normally distributed random number
) Use this to index into...
1Y2 The alphabet
The distribution is symmetrical around 0, and the translation of number to char is symmetrical around 0.5. As such the probabilities should be distinct.
Matlab, 22
Will often return early letters, but can theoretically touch them all!
Takes one devided by a random number, limits this to 26 and turns it in to a character.
['' 96+min(1/rand,26)]
Not very short of course, but perhaps the concept can inspire other answers.
Oracle SQL 11.2, 212 bytes
Using character position in the alphabet as probability
SELECT c FROM(SELECT dbms_random.value(0,351)v FROM DUAL),(SELECT c,e,LAG(e,1,0)OVER(ORDER BY c)s FROM(SELECT CHR(LEVEL+64)c,SUM(LEVEL)OVER(ORDER BY LEVEL)e FROM DUAL CONNECT BY LEVEL<27))WHERE v BETWEEN s AND e;
Un-golfed
SELECT c FROM
(SELECT dbms_random.value(0,351)v FROM DUAL), -- random value
(
SELECT c,e,LAG(e,1,0)OVER(ORDER BY c)s -- Mapping each character to its interval
FROM (
-- Each char has it's position in the alphabet as probability
SELECT CHR(LEVEL+64)c,SUM(LEVEL)OVER(ORDER BY LEVEL)e
FROM DUAL
CONNECT BY LEVEL<27
)
)
WHERE v BETWEEN s AND e -- match the random value to an interval
Batch, 116 bytes
@set/ar=%random%%%676,s=r/26,r%%=26,s-=(r-s)*(r-s^>^>31)
@set a=ABCDEFGHIJKLMNOPQRSTUVWXYZ
@call echo %%a:~%s%,1%%
Works by picking the larger or smaller (I forget which) of two random variables.
JavaScript (ES6), 45 bytes
_=>(n=Math.random(),10+n*n*26|0).toString(36)
Achieves non-uniform distribution by squaring the random value. Math.random() returns a float of the range [0,1) so the result of squaring this tends towards 0 (or a).
Test
var solution =
_=>(n=Math.random(),10+n*n*26|0).toString(36)
var frequency = Array(26).fill(0);
for (var i = 0, tests = 1000000; i < tests; i++)
frequency[solution().charCodeAt(0) - 97]++;
result.textContent = frequency
.map((n, i) => [ String.fromCharCode(97 + i), n ])
.sort((a, b) => b[1] - a[1])
.map((x) => `${x[0]}: ${(x[1] / tests * 100).toFixed(2)}%`)
.join('\n');<pre id="result"></pre>R, 40 27 bytes
LETTERS[sample(26,1,,1:26)]
This will take 1 number from 26 numbers generated with growing probability toward Z, without replacing, and display a letter the index of which is this number, from the list of uppercase letters LETTERS.
The arguments of the sample function are :
sample(
26, #How many numbers to generate
1, #How many numbers to sample
, #Replacing ? Here, no by default
1:26, #Weight of probabilities
)
CJam, 11 bytes
4.mrmqC*'A+
or
676.mrmq'A+
This solution is similar to Luis's idea and creates a non-uniform distribution by taking the square root of the random variable.
Clojure, 61 bytes
#(char(- 90(count(take-while(fn[a](<(rand)0.5))(range 26)))))
Takes each successive element from the range of 26 elements with probability 1/2. So the chance that one element is taken is 1/2, 2 elements - 1/4 and so on. After that subtract from 90 number of elements taken and turn it into char.
p(Z) = 1/2, p(Y) = 1/4, p(X) = 1/8 ... p(A) = 1/2^(26)
See it online: https://ideone.com/Cg15FY
CJam, 21 17 12 bytes
Thanks to Martin Ender for saving me 5 bytes!
New version
'\,:,s_el-mR
This forms an array of strings following the pattern A, AB, ABC, and so on. It flattens it and chooses a random character. Since this string contains 26 A's, 25 B's, 24 C's, and so on, each letter has a distinct probability of being chosen.
Explanation
'\, e# Push the range of all characters up to 'Z'
:, e# For each one, take the range of all characters up to it
s e# Convert the array of ranges to one string
_el- e# Subtract the lower case version of the string from itself
e# This leaves only capital letters in the string
mR e# Take a random character from it
Old version
26,:)'[,'A,- .*M*mr0=
Gets distinct probabilities by making a string in which each letter appears a number of times equal to its position in the alphabet.
26,:) e# Push 1, 2, ... 26
'[,'A,- e# Push 'A', 'B', ... 'Z'
.* e# Vectorize: repeat each letter the corresponding number of times
M* e# Join with no separator
mr e# Shuffle the string
0= e# Get the first character
zsh, 63 bytes
for i in {A..Z};for j in {1..$[#i]};s+=$i;echo $s[RANDOM%$#s+1]
it works by creating this string:
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEEFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIIJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJJKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKKLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMMNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPPQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQQRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRRSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZ
aka 65 times A, 66 times B, 67 times C...
and then it chooses a random character in it
PowerShell v2+, 33 31 bytes
[char](65..90|%{,$_*$_}|Random)
Takes a range from 65 to 90 (i.e., ASCII A to Z), pipes it through a loop. Each iteration, we use the comma-operator to create an array of that element times that number. For example, this will make 65 65s, 66 66s, 67 67s, etc. That big array is piped to Get-Random which will (uniformly PRNG) select one element. Since there are different quantities of each element, each character has a slightly distinct percentage chance of being picked. We then encapsulate that in parens and cast it as a char. That's left on the pipeline and output is implicit.
(Thanks to @LeakyNun for golfing a few bytes even before it was posted. :D)
The probabilities
(slight rounding so I could demonstrate the P option of the -format operator)
PS C:\Tools\Scripts\golfing> 65..90|%{"$([char]$_): {0:P}"-f($_/2015)}
A: 3.23 %
B: 3.28 %
C: 3.33 %
D: 3.37 %
E: 3.42 %
F: 3.47 %
G: 3.52 %
H: 3.57 %
I: 3.62 %
J: 3.67 %
K: 3.72 %
L: 3.77 %
M: 3.82 %
N: 3.87 %
O: 3.92 %
P: 3.97 %
Q: 4.02 %
R: 4.07 %
S: 4.12 %
T: 4.17 %
U: 4.22 %
V: 4.27 %
W: 4.32 %
X: 4.37 %
Y: 4.42 %
Z: 4.47 %
q, 38 bytes
Not particularly short but...
.Q.A(reverse 0.9 xexp til 26)binr 1?1f
The discrete cumulative distribution function is the sequence
0.9 ^ 26, 0.9 ^ 25, ..., 0.9 ^ 0
And we merely sample from the distribution.
Pyth, 5
Os._G
Computes the prefixes of the alphabet, so: ["a", "ab", "abc", ..., "abcdefghijklmnopqrstuvwxyz"]. Then flattens the list and selects a random element from it uniformly. This means that since a appears 26 times, while b appears 25 times, all the way down to z with only 1 appearance, each letter has a different chance of appearing. The total string has 351 characters.
05AB1E, 6 bytes
Code
A.pJ.R
Explanation
A # Pushes the alphabet
.p # Computes all prefixes
J # Join them together
We now have the following string:
aababcabcdabcdeabcdefabcdefgabcdefghabcdefghiabcdefghijabcdefghijkabcdefghijklabcdefghijklmabcdefghijklmnabcdefghijklmnoabcdefghijklmnopabcdefghijklmnopqabcdefghijklmnopqrabcdefghijklmnopqrsabcdefghijklmnopqrstabcdefghijklmnopqrstuabcdefghijklmnopqrstuvabcdefghijklmnopqrstuvwabcdefghijklmnopqrstuvwxabcdefghijklmnopqrstuvwxyabcdefghijklmnopqrstuvwxyz
After that, we pick a random element using .R.
The probabilities
a > 7.4074074074074066%
b > 7.122507122507122%
c > 6.837606837606838%
d > 6.552706552706553%
e > 6.267806267806268%
f > 5.982905982905983%
g > 5.698005698005698%
h > 5.413105413105414%
i > 5.128205128205128%
j > 4.843304843304843%
k > 4.5584045584045585%
l > 4.273504273504274%
m > 3.988603988603989%
n > 3.7037037037037033%
o > 3.418803418803419%
p > 3.133903133903134%
q > 2.849002849002849%
r > 2.564102564102564%
s > 2.2792022792022792%
t > 1.9943019943019944%
u > 1.7094017094017095%
v > 1.4245014245014245%
w > 1.1396011396011396%
x > 0.8547008547008548%
y > 0.5698005698005698%
z > 0.2849002849002849%
J, 20 18 bytes
({~?@#)u:64+#~1+i.26({~?@#)u:64+#~i.27
Uppercase.
Each letter's probability is its 1-based index in the alphabet.
Python 2, 72 bytes
from random import*
print choice(''.join(i*chr(i)for i in range(65,91)))
Multiplies the character by its ascii value, then picks one character at random from the resulting string.
Here are the probabilities for each letter being selected, in percentages:
A 3.23
B 3.28
C 3.33
D 3.37
E 3.42
F 3.47
G 3.52
H 3.57
I 3.62
J 3.67
K 3.72
L 3.77
M 3.82
N 3.87
O 3.92
P 3.97
Q 4.02
R 4.07
S 4.12
T 4.17
U 4.22
V 4.27
W 4.32
X 4.37
Y 4.42
Z 4.47
Try it: https://repl.it/Cm0x