| Bytes | Lang | Time | Link |
|---|---|---|---|
| 029 | APLNARS | 250117T100837Z | Rosario |
| 004 | Nekomata | 230916T002517Z | alephalp |
| 003 | Thunno 2 L | 230729T165709Z | The Thon |
| 041 | SageMath | 230415T063815Z | 138 Aspe |
| 076 | ><> Fish | 230415T055033Z | mousetai |
| 034 | Arturo | 230414T210146Z | chunes |
| 131 | Regex ECMAScript | 190222T175037Z | Grimmy |
| 022 | Julia 1.x | 160622T082907Z | Glen O |
| 005 | Vyxal s | 210623T032400Z | Wasif |
| 007 | Husk | 201022T183543Z | Dominic |
| 016 | Brachylog v2 | 201022T145319Z | Unrelate |
| 042 | JavaScript Node.js | 200726T031012Z | user2027 |
| 002 | Japt mx | 191204T225151Z | Shaggy |
| 065 | C gcc | 190225T003445Z | ceilingc |
| 019 | TI84 BASIC | 190224T201156Z | SuperJed |
| 024 | Pari/GP | 190224T035303Z | alephalp |
| 005 | Japt mx | 190223T000455Z | Oliver |
| 053 | JavaScript ES6 | 190222T230627Z | Arnauld |
| 044 | Python 2 | 171014T144246Z | Dennis |
| 009 | J | 160622T100712Z | miles |
| 044 | Python 2 | 160623T072600Z | xnor |
| 144 | Batch | 160622T094015Z | Neil |
| 050 | Factor | 160624T013731Z | cat |
| 030 | Haskell | 160622T122210Z | sudee |
| 032 | Ruby | 160623T183532Z | Redouane |
| 028 | Haskell | 160623T071458Z | xnor |
| 057 | Python 2 | 160622T163753Z | Dennis |
| 007 | APL | 160623T002236Z | Alex A. |
| 021 | MATLAB / Octave | 160623T002138Z | Suever |
| 058 | Python >=3.5 | 160622T073749Z | jqkul |
| 056 | Hoon | 160622T181311Z | RenderSe |
| 058 | Common Lisp | 160622T142558Z | WarWeasl |
| 072 | PowerShell v2+ | 160622T132902Z | AdmBorkB |
| 007 | 05AB1E | 160622T122005Z | Emigna |
| 029 | Retina | 160622T093020Z | Leaky Nu |
| 022 | Mathematica | 160622T072010Z | Martin E |
| 067 | JavaScript ES6 | 160622T082556Z | Neil |
| 005 | Pyke | 160622T081300Z | Blue |
| 011 | Actually | 160622T071838Z | Leaky Nu |
| 004 | Jelly | 160622T075625Z | Leaky Nu |
| 006 | Pyth | 160622T065614Z | Leaky Nu |
| 007 | MATL | 160622T074916Z | David |
| 011 | J | 160622T070858Z | Leaky Nu |
| 025 | Brachylog | 160622T072928Z | Fatalize |
| 022 | Perl 6 | 160622T071817Z | Brad Gil |
APL(NARS), 29 chars
{×/(v-1)×(v←↑¨k)*¯1+≢¨k←⊂⍨π⍵}
It would factor the argument ⍵ in one array of factors where each appear the time the exponent. Than using one partition of itself (⊂⍨) it would find the each exponent (≢¨k), each prime (↑¨k) would apply the formula
phi(p1^a1 × p2^a2 × ...× pn^an)=(p1-1)×p1^(a1-1)×(p2-1)×p2^(a2-1)× ...×(pn-1)×pn^(an-1)
test:
{×/(v-1)×(v←↑¨k)*¯1+≢¨k←⊂⍨π⍵}¨1 2 3 8 9 26 44 105
┌8──────────────────┐
│ 1 1 2 4 6 12 20 48│
└~──────────────────┘
Thunno 2 L, 3 bytes
æĠḅ
Explanation
æĠḅ # Implicit input
æ # Filter by:
Ġ # GCD with input
ḅ # Equals one?
# Length of list
# Implicit output
Regex (ECMAScript), 131 bytes
At least -12 bytes thanks to Deadcode (in chat)
(?=((xx+)(?=\2+$)|x+)+)(?=((x*?)(?=\1*$)(?=(\4xx+?)(\5*(?!(xx+)\7+$)\5)?$)(?=((x*)(?=\5\9*$)x)(\8*)$)x*(?=(?=\5$)\1|\5\10)x)+)\10|x
Output is the length of the match.
ECMAScript regexes make it extremely hard to count anything. Any backref defined outside a loop will be constant during the loop, any backref defined inside a loop will be reset when looping. Thus, the only way to carry state across loop iterations is using the current match position. That’s a single integer, and it can only decrease (well, the position increases, but the length of the tail decreases, and that’s what we can do math to).
Given those restrictions, simply counting coprime numbers seems impossible. Instead, we use Euler’s formula to compute the totient.
Here’s how it looks like in pseudocode:
N = input
Z = largest prime factor of N
P = 0
do:
P = smallest number > P that’s a prime factor of N
N = N - (N / P)
while P != Z
return N
There are two dubious things about this.
First, we don’t save the input, only the current product, so how can we get to the prime factors of the input? The trick is that (N - (N / P)) has the same prime factors > P as N. It may gain new prime factors < P, but we ignore those anyway. Note that this only works because we iterate over the prime factors from smallest to greatest, going the other way would fail.
Second, we have to remember two numbers across loop iterations (P and N, Z doesn’t count since it’s constant), and I just said that was impossible! Thankfully, we can swizzle those two numbers in a single one. Note that, at the start of the loop, N will always be a multiple of Z, while P will always be less than Z. Thus, we can just remember N + P, and extract P with a modulo.
Here’s the slightly more detailed pseudo-code:
N = input
Z = largest prime factor of N
do:
P = N % Z
N = N - P
P = smallest number > P that’s a prime factor of N
N = N - (N / P) + P
while P != Z
return N - Z
And here’s the commented regex:
# \1 = largest prime factor of N
# Computed by repeatedly dividing N by its smallest factor
(?= ( (xx+) (?=\2+$) | x+ )+ )
(?=
# Main loop!
(
# \4 = N % \1, N -= \4
(x*?) (?=\1*$)
# \5 = next prime factor of N
(?= (\4xx+?) (\5* (?!(xx+)\7+$) \5)? $ )
# \8 = N / \5, \9 = \8 - 1, \10 = N - \8
(?= ((x*) (?=\5\9*$) x) (\8*) $ )
x*
(?=
# if \5 = \1, break.
(?=\5$) \1
|
# else, N = (\5 - 1) + (N - B)
\5\10
)
x
)+
) \10
And as a bonus…
Regex 🐝 (ECMAScript 2018, number of matches), 23 bytes
x(?<!^\1*(?=\1*$)(x+x))
Output is the number of matches. ECMAScript 2018 introduces variable-length look-behind (evaluated right-to-left), which makes it possible to simply count all numbers coprime with the input.
It turns out this is independently the same method used by Leaky Nun's Retina solution, and the regex is even the same length (and interchangeable). I'm leaving it here because it may be of interest that this method works in ECMAScript 2018 (and not just .NET).
# Implicitly iterate from the input to 0
x # Don’t match 0
(?<! ) # Match iff there is no...
(x+x) # integer >= 2...
(?=\1*$) # that divides the current number...
^\1* # and also divides the input
Julia 1.x, 22 bytes
!n=sum(gcd.(1:n,n).<2)
This is the same as the old solution, but using newer features of the language, as the original solution dates back to something like Julia 0.4. This solution uses function broadcasting to achieve the result more efficiently.
Julia, 25 bytes
!n=sum(i->gcd(i,n)<2,1:n)
It's simple - the sum function allows you to give it a function to apply before summing - basically the equivalent of running map and then sum. This directly counts the number of relatively prime numbers less than n.
Husk, 7 bytes
ṁo=1⌋¹ḣ
ṁo=1⌋¹ḣ
ṁ ḣ # sum of function applied to 1..input
o # join 2 functions:
⌋¹ # greatest common divisor with input
=1 # equals 1
Brachylog v2, 16 bytes
{>ℕ≜;?ḋˢ{⊇ᵛ!}Ė}ᶜ
{ }ᶜ Count the number of possible ways that:
ℕ≜ some non-negative integer
> less than the input
;? and the input
ḋˢ have prime factorizations
{⊇ᵛ!} the largest shared subset of which
Ė is empty.
Brachylog v2, 16 bytes
⟨⟦₅zg⟩{ḋˢ⊇ᵛ!Ė}ˢl
z Cycling zip
⟦₅ the range from 0 to one less than the input
⟨ g⟩ with a list containing only the input.
{ }ˢ Map where possible over the pairs:
ḋˢ the prime factorizations'
⊇ᵛ! largest shared subset
Ė is empty.
l For how many pairs did it succeed?
A nuance that my explanations fail to capture is that ḋ fails given an input of 1, so if ḋˢ is given a list containing 1, the 1 is essentially discarded and ignored--so the ⊇ᵛ! (which is really "find any common subset, then discard all of this predicate's choice points", hence the braces in the first solution) of the remaining single number is its entire prime factorization, decidedly not empty, unless the list was nothing but 1s in which case everything is empty.
JavaScript (Node.js), 42 bytes
n=>(g=k=>k&&((k/n|0)*k%n>n-2)+g(k-1))(n*n)
Direct port of Dennis' solution (<- also see the explanation in that answer) to JavaScript.
Alternatives:
n=>(g=k=>k&&g(k-1)+!(~((k/n|0)*k)%n))(n*n)
n=>(g=k=>k&&g(k-1)+!(((k/n|0)*k-1)%n))(n*n)
n=>(g=k=>k&&g(k-1)+!((k/n|0)*k%n-n+1))(n*n)
f=(n,k=0)=>k<n*n&&((k/n|0)*k%n>n-2)+f(n,k+1)
C (gcc), 67 65 bytes
f(x,a,b,y,z){for(z=y=x;a=y--;z-=b>1)for(b=x;a^=b^=a^=b%=a;);x=z;}
Edit: Removed temp variable.
Edit2: -1 thanks to @HowChen
Slightly less golfed
f(x,a,b,y,z){
// counts y NOT coprime with x and subtract
for(z=y=x;a=y--;z-=b>1)
// compute GCD
for(b=x;a^=b^=a^=b%=a;);
x=z;
}
TI-84 BASIC, 19 bytes
Prompt A:sum(seq(1=gcd(A,B),B,1,A
Python 2, 44 bytes
lambda n:sum(k/n*k%n>n-2for k in range(n*n))
This uses the same method to identify coprimes as my answer to “Coprimes up to N”.
J, 9 bytes
(-~:)&.q:
This is based on the Jsoftware's essay on totient functions.
Given n = p1e1 ∙ p2e2 ∙∙∙ pkek where pk is a prime factor of n, the totient function φ(n) = φ(p1e1) ∙ φ(p2e2) ∙∙∙ φ(pkek) = (p1 - 1) p1e1 - 1 ∙ (p2 - 1) p2e2 - 1 ∙∙∙ (pk - 1) pkek - 1.
Usage
f =: (-~:)&.q:
(,.f"0) 1 2 3 8 9 26 44 105
1 1
2 1
3 2
8 4
9 6
26 12
44 20
105 48
f 12345
6576
Explanation
(-~:)&.q: Input: integer n
q: Prime decomposition. Get the prime factors whose product is n
( )& Operate on them
~: Nub-sieve. Create a mask where 1 is the first occurrence
of a unique value and 0 elsewhere
- Subtract elementwise between the prime factors and the mask
&.q: Perform the inverse of prime decomposition (Product of the values)
Python 2, 44 bytes
f=lambda n,d=1:d/n or-f(d)*(n%d<1)-~f(n,d+1)
Less golfed:
f=lambda n:n-sum(f(d)for d in range(1,n)if n%d<1)
Uses the formula that the Euler totients of the divisors of n have a sum of n:
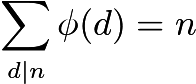
The value of ϕ(n) can then be recursively computed as n minus the sum over nontrivial divisors. Effectively, this is doing Möbius inversion on the identity function. I used the same method in a golf to compute the Möbius function.
Thanks to Dennis for saving 1 byte with a better base case, spreading the initial value of +n into +1 for each of the n loops, done as -~.
Batch, 151 145 144 bytes
@echo off
set t=
for /l %%i in (1,1,%1)do call:g %1 %%i
echo %t%
exit/b
:g
set/ag=%1%%%2
if not %g%==0 call:g %2 %g%
if %2%==1 set/at+=1
Edit: Saved 4 bytes by removing unnecessary spaces. Saved 1 byte by using +=. Saved 1 byte by clearing t as += will interpret that as 0 anyway. Saved 1 byte thanks to @EʀɪᴋᴛʜᴇGᴏʟғᴇʀ.
Factor, 50 bytes
[ dup iota swap '[ _ gcd nip 1 = ] filter length ]
Makes a range (iota) n, and curries n into a function which gets gcd x n for all values of 0 <= x <= n, tests if the result is 1. Filter the original range on whether the result of gcd x n was 1, and take its length.
Haskell, 31 30 bytes
\n->sum[1|x<-[1..n],gcd n x<2]
1 byte saved, thanks to @Damien.
Selects values with gcd = 1, maps each to 1, then takes the sum.
Ruby, 32 bytes
->n{(1..n).count{|i|i.gcd(n)<2}}
a lambda that takes an integer n, and returns the counts of how many integers in the range (1..n) are coprime with n.
Haskell, 28 bytes
f n=sum[1|1<-gcd n<$>[1..n]]
Uses Haskell's pattern matching of constants. The tricks here are fairly standard for golfing, but I'll explain to a general audience.
The expression gcd n<$>[1..n] maps gcd n onto [1..n]. In other words, it computes the gcd with n of each number from 1 to n:
[gcd n i|i<-[1..n]]
From here, the desired output is the number of 1 entries, but Haskell lacks a count function. The idiomatic way to filter to keep only 1's, and take the resulting length, which is much is too long for golfing.
Instead, the filter is simulated by a list comprehension [1|1<-l] with the resulting list l. Usually, list comprehensions bind values onto variable like in [x*x|x<-l], but Haskell allows a pattern to be matched against, in this case the constant 1.
So, [1|1<-l] generating a 1 on each match of 1, effectively extracting just the 1's of the original list. Calling sum on it gives its length.
Python 2, 57 bytes
f=lambda n,k=1,m=1:n*(k>n)or f(n-(n%k<m%k)*n/k,k+1,m*k*k)
Test it on Ideone.
Background
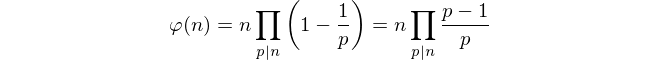
where φ denotes Euler's totient function and p varies only over prime numbers.
To identify primes, we use a corollary of Wilson's theorem:
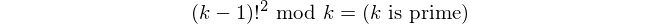
How it works
At all times, the variable m will be equal to the square of the factorial of k - 1. In fact, we named arguments default to k = 1 and m = 0!2 = 1.
As long as k ≤ n, n*(k>n) evaluates to 0 and the code following or gets executed.
Recall that m%k will yield 1 if m is prime and 0 if not. This means that x%k<m%k will yield True if and only if both k is a prime number and x is divisible by k.
In this case, (n%k<m%k)*n/k yields n / k, and subtracting it from n replaces its previous value with n(1 - 1/k), as in Euler's product formula. Otherwise, (n%k<m%k)*n/k yields 0 and n remains unchanged.
After computing the above, we increment k and multiply m by the "old" value of k2, thus maintaining the desired relation between k and m, then call f recursively with the updated arguments.
Once k exceeds n, n*(k>n) evaluates to n, which is returned by the function.
APL, 7 bytes
+/1=⊢∨⍳
This is a monadic function train that takes an integer on the right. The approach here is the obvious one: sum (+/) the number of times the GCD of the input and the numbers from 1 to the input (⊢∨⍳) is equal to 1 (1=).
MATLAB / Octave, 21 bytes
@(n)sum(gcd(n,1:n)<2)
Creates an anonymous function named ans which can be called with the integer n as the only input: ans(n)
Python >=3.5, 76 64 58 bytes
Thanks to LeakyNun for golfing off 12 (!) bytes.
Thanks to Sp3000 for golfing off 6 bytes.
import math
lambda n:sum(math.gcd(n,x)<2for x in range(n))
I love how readable Python is. This makes sense, even through the golfedness.
Hoon, 56 bytes
|=
a/@
(lent (skim (gulf 1 a) |=(@ =(1 d:(egcd +< a)))))
Measure the length of the list [1...a] after keeping all the elements where GCD(i, a) == 1
Common Lisp, 58 bytes
(defun o(x)(loop for i from 1 to x if (=(gcd x i)1)sum 1))
This is a simple loop which counts up 1 to the given n and increments the sum if gcd = 1. I use the function name o since t is the true boolean value. Not nearly the shortest but fairly simple.
PowerShell v2+, 72 bytes
param($n)1..$n|%{$a=$_;$b=$n;while($b){$a,$b=$b,($a%$b)};$o+=!($a-1)};$o
PowerShell doesn't have a GCD function available to it, so I had to roll my own.
This takes input $n, then ranges from 1 to $n and pipes those into a loop |%{...}. Each iteration we set two helper variables $a and $b and then execute a GCD while loop. Each iteration we're checking that $b is still non-zero, and then saving $a%$b to $b and the previous value of $b to $a for the next loop. We then accumulate whether $a is equal to 1 in our output variable $o. Once the for loop is done, we place $o on the pipeline and output is implicit.
As an example of how the while loop works, consider $n=20 and we're on $_=8. The first check has $b=20, so we enter the loop. We first calculate $a%$b or 8%20 = 8, which gets set to $b at the same time that 20 gets set to $a. Check 8=0, and we enter the second iteration. We then calculate 20%8 = 4 and set that to $b, then set $a to 8. Check 4=0, and we enter the third iteration. We calculate 8%4 = 0 and set that to $b, then set $a to 4. Check 0=0 and we exit the loop, so the GCD(8,20) is $a = 4. Thus, !($a-1) = !(4-1) = !(3) = 0 so $o += 0 and we don't count that one.
05AB1E, 7 bytes
Lvy¹¿i¼
Explained
Lv # for each x in range(1,n)
y¹¿ # GCD(x,n)
i¼ # if true (1), increase counter
# implicitly display counter
Retina, 36 29 bytes
7 bytes thanks to Martin Ender.
.+
$*
(?!(11+)\1*$(?<=^\1+)).
Explanation
There are two stages (commands).
First stage
.+
$*
It is a simple regex substitution, converting the input to that many ones.
For example, 5 would be converted to 11111.
Second stage
(?!(11+)\1*$(?<=^\1+)).
This regex tries to match the positions which satisfy the condition (co-prime with input), and then return the number of matches.
Mathematica, 27 22 bytes
Range@#~GCD~#~Count~1&
An unnamed function that takes and returns an integer.
Not much to explain here, except that @ is prefix notation for function calls and ~...~ is (left-associative) infix notation, so the above is the same as:
Count[GCD[Range[#], #], 1] &
JavaScript (ES6), 67 bytes
f=n=>[...Array(n)].reduce(r=>r+=g(n,++i)<2,i=0,g=(a,b)=>b?g(b,a%b):a)
Actually, 11 bytes
;╗R`╜g`M1@c
Explanation
;╗R`╜g`M1@c register stack remarks
44
; 44 44
╗ 44 44
R 44 [1 2 3 .. 44]
M 44 10 for example
╜ 44 10 44
g 44 2
44 [1 2 1 .. 44] gcd of each with register
1 44 [1 2 1 .. 44] 1
@ 44 1 [1 2 1 .. 44]
c 44 20 count
With built-in
▒
Jelly, 4 bytes
Rgċ1
Explanation
Rgċ1 Main monadic chain. Argument: z
R Yield [1 2 3 .. z].
g gcd (of each) (with z).
ċ1 Count the number of occurrences of 1.
With built-in
ÆṪ
Explanation
ÆṪ Main monadic chain. Argument: z
ÆṪ Totient of z.
Pyth, 6 bytes
smq1iQ
/iLQQ1
Explanation
smq1iQ input as Q
smq1iQdQ implicitly fill variables
m Q for d in [0 1 2 3 .. Q-1]:
iQd gcd of Q and d
q1 equals 1? (1 if yes, 0 if no)
s sum of the results
/iLQQ1 input as Q
iLQQ gcd of each in [0 1 2 3 .. Q-1] with Q
/ 1 count the number of occurrences of 1
MATL, 7 bytes
t:Zd1=s
You can TryItOnline. Simplest idea, make a vector 1 to N, and taken gcd of each element with N (Zd does gcd). Then, find which elements are equal to 1, and sum the vector to get the answer.
J, 11 bytes
+/@(1=+.)i.
Usage
>> f =: +/@(1=+.)i.
>> f 44
<< 20
where >> is STDIN and << is STDOUT.
Explanation
+/ @ ( 1 = +. ) i.
│
┌───────────┴┐
+/@(1=+.) i.
│
┌─┼──┐
+/ @ 1=+.
┌─┼─┐
1 = +.
>> (i.) 44 NB. generate range
<< 0 1 2 3 4 ... 43
>> (+.i.) 44 NB. calculate gcd of each with input
<< 44 1 2 1 4 ... 1
>> ((1=+.)i.) 44 NB. then test if each is one (1 if yes, 0 if no)
<< 0 1 0 1 0 ... 1
>> (+/@(1=+.)i.) 44 NB. sum of all the tests
<< 20
Brachylog, 25 bytes
:{:1e.$pdL,?$pd:LcCdC}fl.
Explanation
Brachylog has no GCD built-in yet, so we check that the two numbers have no prime factors in common.
Main predicate:
:{...}fl. Find all variables which satisfy predicate 1 when given to it as output and with Input as input. Unify the Output with the length of the resulting listPredicate 1:
:1e. Unify Output with a number between Input and 1 $pdL L is the list of prime factors of Output with no duplicates , ?$pd:LcC C is the concatenation of the list of prime factors of Input with no duplicates and of L dC C with duplicates removed is still C
Perl 6, 26 24 22 bytes
{[+] (^$^n Xgcd $n) X== 1}
{+grep 2>*,(^$_ Xgcd$_)}
{[+] 2 X>(^$_ Xgcd$_)}Explanation:
{
[+] # reduce using &infix:<+>
2
X[>] # crossed compared using &infix:«>»
(
^$_ # up to the input ( excludes input )
X[gcd] # crossed using &infix:<gcd>
$_ # the input
)
}
Example:
#! /usr/bin/env perl6
use v6.c;
my &φ = {[+] 2 X>(^$_ Xgcd$_)};
say φ(1) # 1
say φ(2) # 1
say φ(3) # 2
say φ(8) # 4
say φ(9) # 6
say φ(26) # 12
say φ(44) # 20
say φ(105) # 48
say φ 12345 # 6576