| Bytes | Lang | Time | Link |
|---|---|---|---|
| 067 | Raku Perl 6 rakudo | 250417T162027Z | xrs |
| 065 | AWK | 250408T162840Z | xrs |
| 145 | Excel | 220110T200920Z | Engineer |
| 244 | Haskell | 150717T093252Z | Jeremy L |
| 6284 | Taxi | 210822T163146Z | JosiahRy |
| 018 | Japt S | 210819T084759Z | Shaggy |
| 018 | Stax | 210819T040834Z | Razetime |
| 027 | Husk | 210819T034925Z | Razetime |
| 018 | Vyxal | 210819T001002Z | emanresu |
| 177 | Haskell | 150804T193440Z | Leif Wil |
| 076 | KDBQ | 150626T085537Z | WooiKent |
| 162 | Java | 150618T005536Z | Geobits |
| 031 | CJam | 150618T004138Z | Dennis |
| 086 | JavaScript ES6 | 150618T023326Z | NinjaBea |
| 129 | SAS | 150618T033222Z | Fried Eg |
| 275 | rs | 150619T163534Z | kirbyfan |
| 146 | C | 150619T100733Z | edc65 |
| 019 | Pyth | 150619T003243Z | Jakube |
| 046 | Perl | 150618T154059Z | nutki |
| 184 | C | 150618T060327Z | some use |
| 101 | Bash | 150618T145628Z | Daniel W |
| 097 | Julia | 150618T030343Z | Alex A. |
| 116 | JavaScript | 150618T123308Z | C5H8NNaO |
| 084 | Python 2 | 150618T041123Z | Kade |
| 068 | Ruby | 150618T003230Z | Doorknob |
| 092 | PHP4.1 | 150618T093457Z | Ismael M |
| 078 | Python 2 | 150618T084947Z | xnor |
| 164 | SpecBAS | 150618T084124Z | Brian |
| 022 | Pyth | 150618T012827Z | izzyg |
| 118 | R | 150618T021414Z | MickyT |
Raku (Perl 6) (rakudo), 67 bytes
{$!=$^a;for <NBM BM NB M B N> ->$x {$_~=+($!~~s:g/$x//)~$x~' '};$_}
I'm convinced there's a shorter way with map...
{$!=$^a; # incoming parameters are r/o
for # for each member of
<NBM BM NB M B N> # this array
->$x # name the member
{$_~= # append to a string
+ # coerce to int
($!~~s:g/$x//) # return number of subs
~$x # append member
~' '} # append space
;$_} # return final string
AWK, 65 bytes
{for(;i++<split("NBM BM NB M B N",a);)s=gsub(d=a[i],FS)d" "s}$0=s
{for( # loop search strings
;i++< # each string
split("NBM BM NB M B N",a);) # search strings
s= # craft new string
gsub(d=a[i],FS) # return number of matches
d" " # append search string
s} # to front of string
$0=s # set output to string
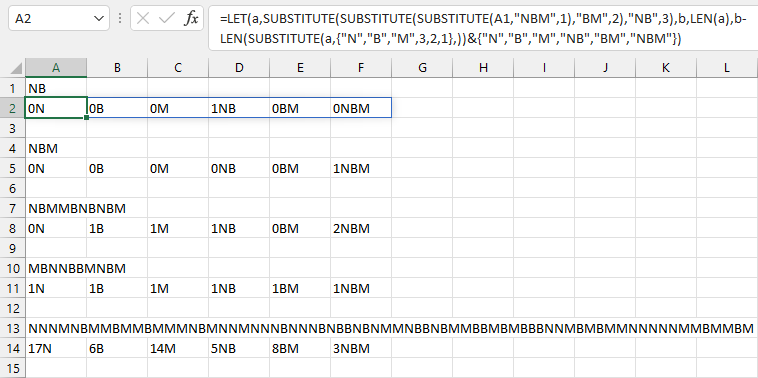
Excel, 149 145 bytes
Saved 4 bytes by realizing I can directly use LEN(a) after I rewrote the function from my first - never submitted - draft.
=LET(a,SUBSTITUTE(SUBSTITUTE(SUBSTITUTE(A1,"NBM",1),"BM",2),"NB",3),LEN(a)-LEN(SUBSTITUTE(a,{"N","B","M",3,2,1},))&{"N","B","M","NB","BM","NBM"})
Start by replacing NBM with 1 then BM with 2 and NB with 3. Now we have a string that is as many characters long as they are creatures. One by one, we check the difference between that string's length and it's length with one of the creatures removed. Output is an array of cells.
Haskell, 244 bytes
import Data.List
s="NBM"
[]#_=[[]]
a#[]=[]:a#s
l@(a:r)#(b:m)
|a==b=let(x:y)=r#m in((a:x):y)
|True=[]:l#m
c?t=length$filter(==t)c
p=["N","B","M","NB","BM","NBM"]
main=getLine>>= \l->putStrLn.intercalate " "$map(\t->show((l#[])?t)++t)p
Taxi, 6284 bytes
Go to Post Office:W 1 L 1 R 1 L.Pickup a passenger going to Chop Suey.Go to Chop Suey:N 1 R 1 L 4 R 1 L.[A]Switch to plan N if no one is waiting.Pickup a passenger going to Cyclone.N is waiting at Writer's Depot.Go to Zoom Zoom:N 1 L 3 R.Go to Writer's Depot:W.Pickup a passenger going to Crime Lab.Go to Cyclone:N.Pickup a passenger going to Cyclone.Go to Cyclone:N 1 R 1 R 1 R.Pickup a passenger going to Cyclone.Pickup a passenger going to Cyclone.Go to Cyclone:N 1 R 1 R 1 R.Pickup a passenger going to Tom's Trims.Pickup a passenger going to Tom's Trims.Go to Tom's Trims:S 1 L 2 R 1 L.Go to Cyclone:S 1 R 1 L 2 R.Pickup a passenger going to Crime Lab.Pickup a passenger going to Tom's Trims.Go to Tom's Trims:S 1 L 2 R 1 L.Go to Crime Lab:S 1 L 1 L.Switch to plan F if no one is waiting.Pickup a passenger going to Auctioneer School.Go to Rob's Rest:S 1 R 1 L 1 L 1 R 1 R.Switch to plan D if no one is waiting.Go to Bird's Bench:S.Switch to plan B if no one is waiting.Go to Rob's Rest:N.Pickup a passenger going to KonKat's.Go to Bird's Bench:S.Pickup a passenger going to KonKat's.Go to KonKat's:N 1 R 1 L 2 R 1 R 2 R.Pickup a passenger going to Sunny Skies Park.Go to Sunny Skies Park:N 1 L 2 L 1 L.Go to Auctioneer School:S.Pickup a passenger going to Rob's Rest.Go to Rob's Rest:N 2 L 1 R.Go to Cyclone:S 1 L 1 L 2 L.Switch to plan C.[B]Go to Auctioneer School:N 1 R 1 R.Pickup a passenger going to Sunny Skies Park.Go to Sunny Skies Park:N.Go to Cyclone:N 1 L.[C]Pickup a passenger going to Riverview Bridge.Go to Riverview Bridge:N 2 R.Go to Chop Suey:E 2 R.Switch to plan A.[D]Go to Bird's Bench:S.Switch to plan E if no one is waiting.Pickup a passenger going to Sunny Skies Park.[E]Go to Auctioneer School:N 1 R 1 R.Pickup a passenger going to Rob's Rest.Go to Rob's Rest:N 2 L 1 R.Go to Sunny Skies Park:S 1 L 1 L.Go to Cyclone:N 1 L.Switch to plan C.[F]B is waiting at Writer's Depot.Go to Writer's Depot:S 1 R 1 L 2 L.Pickup a passenger going to Crime Lab.Go to Cyclone:N.Pickup a passenger going to Cyclone.Go to Cyclone:N 1 R 1 R 1 R.Pickup a passenger going to Crime Lab.Go to Crime Lab:S 1 L 2 R 2 L.Switch to plan J if no one is waiting.Pickup a passenger going to Auctioneer School.Go to Bird's Bench:S 1 R 1 L 1 L 1 R 1 L.Switch to plan I if no one is waiting.Go to Rob's Rest:N.Switch to plan G if no one is waiting.Pickup a passenger going to KonKat's.[G]Go to Bird's Bench:S.Pickup a passenger going to KonKat's.Go to KonKat's:N 1 R 1 L 2 R 1 R 2 R.Pickup a passenger going to Sunny Skies Park.Go to Sunny Skies Park:N 1 L 2 L 1 L.Go to Auctioneer School:S.[H]Pickup a passenger going to Bird's Bench.Go to Bird's Bench:N 2 L 1 L.Go to Cyclone:N 1 R 1 L 2 L.Switch to plan C.[I]Go to Auctioneer School:N 1 R 1 R.Switch to plan H.[J]Go to Bird's Bench:S 1 R 1 L 1 L 1 R 1 L.Switch to plan L if no one is waiting.Go to Rob's Rest:N.Switch to plan K if no one is waiting.Pickup a passenger going to KonKat's.[K]Go to Bird's Bench:S.Pickup a passenger going to KonKat's.[L]Go to Cyclone:N 1 R 1 L 2 L.Pickup a passenger going to KonKat's.Go to KonKat's:N 2 R 2 R.Pickup a passenger going to Sunny Skies Park.Go to Rob's Rest:S 4 R 1 L 1 L 1 R 1 R.Switch to plan M if no one is waiting.Pickup a passenger going to Sunny Skies Park.[M]Go to Sunny Skies Park:S 1 L 1 L.Go to Chop Suey:N 1 R 1 R 3 R.Switch to plan A.[N]Go to Rob's Rest:N 1 L 3 L 1 L 2 R 1 R.Switch to plan O if no one is waiting.Pickup a passenger going to KonKat's.[O]Go to Bird's Bench:S.Switch to plan P if no one is waiting.Pickup a passenger going to KonKat's.[P]Go to KonKat's:N 1 R 1 L 2 R 1 R 2 R.Switch to plan Q if no one is waiting.Pickup a passenger going to Sunny Skies Park.[Q]Go to Sunny Skies Park:N 1 L 2 L 1 L.N is waiting at Writer's Depot.B is waiting at Writer's Depot.M is waiting at Writer's Depot.NB is waiting at Writer's Depot.BM is waiting at Writer's Depot.NBM is waiting at Writer's Depot.Go to Writer's Depot:N 1 L.Pickup a passenger going to Joyless Park.Pickup a passenger going to Joyless Park.Pickup a passenger going to Joyless Park.Go to Joyless Park:N 3 R 2 R 2 L.Go to Writer's Depot:W 1 R 2 L 2 L.Pickup a passenger going to Joyless Park.Pickup a passenger going to Joyless Park.Pickup a passenger going to Joyless Park.Go to Joyless Park:N 3 R 2 R 2 L.[R]Switch to plan Y if no one is waiting.Pickup a passenger going to Cyclone.0 is waiting at Starchild Numerology.Go to Starchild Numerology:W 1 L 2 R 1 L 1 L 2 L.Pickup a passenger going to Addition Alley.Go to Cyclone:W 1 R 4 L.[S]Pickup a passenger going to Auctioneer School.Go to Zoom Zoom:N.Go to Auctioneer School:W 2 L.Go to Sunny Skies Park:N.Switch to plan V if no one is waiting.Pickup a passenger going to Cyclone.Go to Cyclone:N 1 L.Pickup a passenger going to Crime Lab.Pickup a passenger going to Crime Lab.Go to Crime Lab:S 1 L 2 R 2 L.Switch to plan T if no one is waiting.Pickup a passenger going to Tom's Trims.Go to Tom's Trims:N 1 L 1 L.1 is waiting at Starchild Numerology.Go to Starchild Numerology:S 1 R 1 L 1 L 2 L.Pickup a passenger going to Addition Alley.Go to Addition Alley:W 1 R 3 R 1 R 1 R.Pickup a passenger going to Addition Alley.Go to Cyclone:N 1 L 1 L.Pickup a passenger going to Riverview Bridge.Go to Riverview Bridge:N 2 R.Go to Auctioneer School:W 2 L 1 L.Switch to plan U.[T]Go to Cyclone:N 4 L 2 L.Pickup a passenger going to Narrow Path Park.Go to Narrow Path Park:N 2 R 1 L 1 R.Go to Auctioneer School:W 1 L 1 R 2 L 1 L.[U]Pickup a passenger going to Cyclone.Go to Cyclone:N 4 L.Switch to plan S.[V]Go to Addition Alley:N 1 R 1 R 1 R.Pickup a passenger going to The Babelfishery.Go to The Babelfishery:N 1 R 1 R.Pickup a passenger going to Post Office.Go to Cyclone:N 1 L 1 L 2 R.Pickup a passenger going to Post Office." " is waiting at Writer's Depot.Go to Writer's Depot:S.Pickup a passenger going to Post Office.Go to Post Office:N 1 R 2 R 1 L.Go to Auctioneer School:S 1 R 1 L 1 L.Pickup a passenger going to Tom's Trims.Go to Narrow Path Park:N 3 R 1 R 1 L 1 R.[W]Switch to plan X if no one is waiting.Pickup a passenger going to Sunny Skies Park.Go to Sunny Skies Park:W 1 L 1 R 2 L 1 L.Go to Zoom Zoom:N 1 R.Go to Narrow Path Park:W 1 L 1 L 1 R.Switch to plan W.[X]Go to Tom's Trims:E 1 R 4 R 1 L.Go to Joyless Park:N 1 R 1 L 3 R.Switch to plan R.[Y]
This ain't winning me any Code Golf competitions, but this was a nice reminder for me not to write any more complex programs in Taxi. (Sooo many special cases, and sooo much gas management...)
A more commented version can be found here, if you dare.
Japt -S, 18 bytes
Outputs in reverse order.
"NBM"ã ÔËiUèDU=rDS
Try it (footer reverses the output)
"NBM"ã ÔËiUèDU=rDS :Implicit input of string U
"NBM"ã :Substrings of "NBM"
Ô :Reverse
Ë :Map each D
i : Prepend
UèD : Count of D in U
U= : Reassign to U*
rD : Replace D with
S : Space
:Implicit output joined with spaces
*This is done within the second argument of the è method but as that only expects 1 argument, it's result is ignored within the mapping & prepending.
Husk, 27 bytes
;zS`+ös←Lx₁GoΣ`x⁰₁
↔ÖLQ"NBM
uses the splitting technique from the Vyxal answer.
Husk, 28 bytes
m§+osL←k€₁Ẋ`-U¡Ṡ-(→n₁ḣ
Q"NBM
Funny set intersection based idea.
Vyxal, 18 bytes
`NBM`KṘ(n/₅‹n+¨…_∑
`NBM` # 'NBM'
K # Substrings
Ṙ( # Iterate over
n/ # Split current string by current substring of NBM
₅‹ # Duplicate and decrement length
np¨…_ # Prepend current substring of NBM and output with a trailing space
∑ # Concatenate for next iteration
Haskell - 177 bytes (without imports)
n s=c$map(\x->(show$length$filter(==x)(words$c$zipWith(:)s([f(a:[b])|(a,b)<-zip s(tail s)]++[" "])))++x++" ")l
f"NB"=""
f"BM"=""
f p=" "
l=["N","B","M","NB","BM","NBM"]
c=concat
(Sorry for the internet necromancy here.)
The Haskell Platform doesn't have string search without imports, and I wanted to show off and exploit the fact that the searched strings are all substrings of one (without repetitions), so that grouping characters can be done by identifying pairs that are allowed to follow each other, which is what f does here.
I still need the full list l in the end to check for equality and display exactly as required, but would not, had the challenge only been to report the number of occurrences of the possible words in any order.
KDB(Q), 76 bytes
{" "sv string[-1+count@'enlist[x]{y vs" "sv x}\l],'l:" "vs"NBM NB BM N B M"}
Explanation
l:" "vs"NBM NB BM N B M" / substrings
enlist[x]{y vs" "sv x}\l / replace previous substring with space and cut
-1+count@' / counter occurrence
string[ ],' / string the count and join to substrings
{" "sv } / concatenate with space, put in lambda
Test
q){" "sv string[-1+count@'enlist[x]{y vs" "sv x}\l],'l:" "vs"NBM NB BM N B M"}"NNNMNBMMBMMBMMMNBMNNMNNNBNNNBNBBNBNMMNBBNBMMBBMBMBBBNNMBMBMMNNNNNMMBMMBM"
"3NBM 5NB 8BM 17N 6B 14M"
q){" "sv string[-1+count@'enlist[x]{y vs" "sv x}\l],'l:" "vs"NBM NB BM N B M"}""
"0NBM 0NB 0BM 0N 0B 0M"
Java, 166 162
void f(String a){String[]q="NBM-NB-BM-N-B-M".split("-");for(int i=0,c;i<6;System.out.print(c+q[i++]+" "))for(c=0;a.contains(q[i]);c++)a=a.replaceFirst(q[i],".");}
And with a few line breaks:
void f(String a){
String[]q="NBM-NB-BM-N-B-M".split("-");
for(int i=0,c;i<6;System.out.print(c+q[i++]+" "))
for(c=0;a.contains(q[i]);c++)
a=a.replaceFirst(q[i],".");
}
It works pretty simply. Just loop over the tokens, replacing them with dots and counting as long as the input contains some. Counts the big ones first, so the little ones don't mess it up.
I originally tried replacing all at once and counting the difference in length, but it took a few more characters that way :(
CJam, 36 32 31 bytes
l[ZYX]"NBM"few:+{A/_,(A+S@`}fA;
Thanks to @Optimizer for golfing off 1 byte.
Try it online in the CJam interpreter.
How it works
l e# Read a line L from STDIN.
[ZYX]"NBM" e# Push [3 2 1] and "NBM".
few e# Chop "NBM" into slices of length 3 to 1.
:+ e# Concatenate the resulting arrays of slices.
{ }fA e# For each slice A:
A/ e# Split L at occurrences of A.
_,( e# Push the numbers of resulting chunks minus 1.
A+ e# Append A.
S e# Push a space.
@` e# Push a string representation of the split L.
; e# Discard L.
JavaScript ES6, 86 bytes
f=s=>'NBM BM NB M B N'.replace(/\S+/g,e=>(i=0,s=s.replace(RegExp(e,'g'),_=>++i))&&i+e)
(I just had to answer this.) It goes through each substring of NBM, starting with the longer ones, which take higher priority. It searches for each occurrence of that particular string and removes it (in this case replacing it with the current count so it won't be matched again). It finally replaces each substring with the count + the string.
This Stack Snippet is written in the ES5 equivalent of the above code to make it easier to test from any browser. It is also slightly ungolfed code. The UI updates with every keystroke.
f=function(s){
return'NBM BM NB M B N'.replace(/\S+/g,function(e){
i=0
s=s.replace(RegExp(e,'g'),function(){
return++i
})
return i+e
})
}
run=function(){document.getElementById('output').innerHTML=f(document.getElementById('input').value)};document.getElementById('input').onkeyup=run;run()<input type="text" id="input" value="NBMMBNBNBM" /><br /><samp id="output"></samp>SAS, 144 142 139 129
data;i="&sysparm";do z='NBM','NB','BM','N','B','M';a=count(i,z,'t');i=prxchange(cats('s/',z,'/x/'),-1,i);put a+(-1)z@;end;
Usage (7 bytes added for sysparm):
$ sas -stdio -sysparm NNNMNBMMBMMBMMMNBMNNMNNNBNNNBNBBNBNMMNBBNBMMBBMBMBBBNNMBMBMMNNNNNMMBMMBM << _S
data;i="&sysparm";do z='NBM','NB','BM','N','B','M';a=count(i,z,'t');i=prxchange(cats('s/',z,'/x/'),-1,i);put a+(-1)z@;end;
_S
or
%macro f(i);i="&i";do z='NBM','NB','BM','N','B','M';a=count(i,z,'t');i=prxchange(cats('s/',z,'/x/'),-1,i);put a+(-1)z@;end;%mend;
Usage:
data;%f(NNNMNBMMBMMBMMMNBMNNMNNNBNNNBNBBNBNMMNBBNBMMBBMBMBBBNNMBMBMMNNNNNMMBMMBM)
Result:
3NBM 5NB 8BM 17N 6B 14M
rs, 275 bytes
(NBM)|(NB)|(BM)|(N)|(B)|(M)/a\1bc\2de\3fg\4hi\5jk\6l
[A-Z]+/_
#
+(#.*?)a_b/A\1
+(#.*?)c_d/B\1
+(#.*?)e_f/C\1
+(#.*?)g_h/D\1
+(#.*?)i_j/E\1
+(#.*?)k_l/F\1
#.*/
#
#(A*)/(^^\1)NBM #
#(B*)/(^^\1)NB #
#(C*)/(^^\1)BM #
#(D*)/(^^\1)N #
#(E*)/(^^\1)B #
#(F*)/(^^\1)M #
\(\^\^\)/0
#/
The workings are simple but a little odd:
(NBM)|(NB)|(BM)|(N)|(B)|(M)/a\1bc\2de\3fg\4hi\5jk\6l
This creatively uses groups to turn input like:
NBMBM
into
aNBMbcdeBMfghijkl
The next line:
[A-Z]+/_
This replaces the sequences of capital letters with underscores.
#
This simply inserts a pound sign at the beginning of the line.
+(#.*?)a_b/A\1
+(#.*?)c_d/B\1
+(#.*?)e_f/C\1
+(#.*?)g_h/D\1
+(#.*?)i_j/E\1
+(#.*?)k_l/F\1
#.*/
This is the beginning cool part. It basically takes the sequences of lowercase letters and underscores, converts them into capital letters, groups them together, and places them before the pound that was inserted. The purpose of the pound is to manage the sequences that have already been processed.
#
The pound is re-inserted at the beginning of the line.
#(A*)/(^^\1)NBM #
#(B*)/(^^\1)NB #
#(C*)/(^^\1)BM #
#(D*)/(^^\1)N #
#(E*)/(^^\1)B #
#(F*)/(^^\1)M #
\(\^\^\)/0
#/
The capital letters are replaced by their text equivalents with the associated counts. Because of a bug in rs (I didn't want to risk fixing it and getting disqualified), the empty sequences are converted into (^^), which is replaced by a 0 in the second-to-last line. The very last line simply removes the pound.
C, 146
f(char*s)
{
char*p,*q="NBM\0NB\0BM\0N\0B\0M",i=0,a=2;
for(;i<6;q+=a+2,a=i++<2)
{
int n=0;
for(;p=strstr(s,q);++n)*p=p[a>1]=p[a]=1;
printf("%d%s ",n,q);
}
}
// Main function, just for testing
main(c,a)char**a;{
f(a[1]);
}
Pyth, 19 bytes
jd+Ltl=zc`zd_.:"NBM
This is a mixture of @isaacg's Pyth solution and @xnor's incredible Python trick.
Try it online: Demonstration or Test harness
Explanation
jd+Ltl=zc`zd_.:"NBM implicit: z = input string
.:"NBM generate all substrings of "NBM"
_ invert the order
+L add left to each d in ^ the following:
`z convert z to a string
c d split at d
=z assign the resulting list to z
tl length - 1
jd join by spaces and implicit print
Perl, 46
#!perl -p
$_="NBM BM NB M B N"=~s/\w+/~~s!$&!x!g.$&/ger
C, 205 186 184 bytes
A little different approach based on state machine. where t is the state.
a[7],t,i;c(char*s){do{i=0;t=*s==78?i=t,1:*s-66?*s-77?t:t-4?t-2?i=t,3:5:6:t-1?i=t,2:4;i=*s?i:t;a[i]++;}while(*s++);printf("%dN %dB %dM %dNB %dBM %dNBM",a[1],a[2],a[3],a[4],a[5],a[6]);}
Expanded
int a[7],t,i;
void c(char *s)
{
do {
i = 0;
if (*s == 'N') {
i=t; t=1;
}
if (*s == 'B') {
if (t==1) {
t=4;
} else {
i=t;
t=2;
}
}
if (*s == 'M') {
if (t==4) {
t=6;
} else if (t==2) {
t=5;
} else {
i=t;
t=3;
}
}
if (!*s)
i = t;
a[i]++;
} while (*s++);
printf("%dN %dB %dM %dNB %dBM %dNBM",a[1],a[2],a[3],a[4],a[5],a[6]);
}
Test function
#include <stdio.h>
#include <stdlib.h>
/*
* 0 : nothing
* 1 : N
* 2 : B
* 3 : M
* 4 : NB
* 5 : BM
* 6 : NBM
*/
#include "nbm-func.c"
int main(int argc, char **argv)
{
c(argv[1]);
}
Bash - 101
I=$1
for p in NBM BM NB M B N;{ c=;while [[ $I =~ $p ]];do I=${I/$p/ };c+=1;done;echo -n ${#c}$p\ ;}
Pass the string as the first argument.
bash nmb.sh MBNNBBMNBM
Explained a bit:
# We have to save the input into a variable since we modify it.
I=$1
# For each pattern (p) in order of precedence
for p in NBM BM NB M B N;do
# Reset c to an empty string
c=
# Regexp search for pattern in string
while [[ $I =~ $p ]];do
# Replace first occurance of pattern with a space
I=${I/$p/ }
# Append to string c. the 1 is not special it could be any other
# single character
c+=1
done
# -n Suppress's newlines while echoing
# ${#c} is the length on the string c
# Use a backslash escape to put a space in the string.
# Not using quotes in the golfed version saves a byte.
echo -n "${#c}$p\ "
done
Julia, 106 97 bytes
b->for s=split("NBM BM NB M B N") print(length(matchall(Regex(s),b)),s," ");b=replace(b,s,".")end
This creates an unnamed function that takes a string as input and prints the result to STDOUT with a single trailing space and no trailing newline. To call it, give it a name, e.g. f=b->....
Ungolfed + explanation:
function f(b)
# Loop over the creatures, biggest first
for s = split("NBM BM NB M B N")
# Get the number of creatures as the count of regex matches
n = length(matchall(Regex(s), b))
# Print the number, creature, and a space
print(n, s, " ")
# Remove the creature from captivity, replacing with .
b = replace(b, s, ".")
end
end
Examples:
julia> f("NBMMBNBNBM")
2NBM 0BM 1NB 1M 1B 0N
julia> f("NNNMNBMMBMMBMMMNBMNNMNNNBNNNBNBBNBNMMNBBNBMMBBMBMBBBNNMBMBMMNNNNNMMBMMBM")
3NBM 8BM 5NB 14M 6B 17N
JavaScript, 108 116 bytes
Just a straight forward approach, nothing fancy
o="";r=/NBM|NB|BM|[NMB]/g;g={};for(k in d=(r+prompt()).match(r))g[d[k]]=~-g[d[k]];for(k in g)o+=~g[k]+k+" ";alert(o);
Python 2, 93 88 89 84 Bytes
Taking the straightforward approach.
def f(n):
for x in"NBM BM NB M B N".split():print`n.count(x)`+x,;n=n.replace(x,"+")
Call like so:
f("NBMMBNBNBM")
Output is like so:
2NBM 0BM 1NB 1M 1B 0N
Ruby, 166 80 72 68 characters
f=->s{%w(NBM BM NB M B N).map{|t|c=0;s.gsub!(t){c+=1};c.to_s+t}*' '}
Explanation:
The counting is done in reverse. This is because the longer ninjas and bears and monkeys take precedence over the shorter ones.
For
NBM,BM, andNB, the sequences aregsub!'d out of the original string with a block to count how many of these sequences exist (yes, the function modifies its argument).- However, they can't be replaced with nothing, since otherwise
BNBMMwould be counted asNBMandBMinstead ofB,NBM, andM(because when theNBMwould be removed, it would put theBandMtogether and there wouldn't be a way to distinguish it). Originally I returned a single character string (.gsub!('NBM'){c+=1;?|}), but I realized I could just return the result of the+=(which is a number, so it can't be any ofNBM).
- However, they can't be replaced with nothing, since otherwise
ForNow it's a loop (don't know why I didn't think of that in the first place), so these are done the same way.M,B, andN, I can justcounthow many of them there are in the string (no need to remove them viagsub!).
Similar solution in Ostrich, 54 51 chars:
:s;`NBM BM NB M B N`" /{:t0:n;s\{;n):n}X:s;nt+}%" *
Unfortunately not a valid solution, as there is a bug in the current Ostrich version (that is now fixed, but after this challenge was posted).
PHP4.1, 92 bytes
Not the shortest one, but what else would you expect from PHP?
To use it, set a key on a COOKIE, POST, GET, SESSION...
<?foreach(split(o,NBMoNBoBMoMoBoN)as$a){echo count($T=split($a,$S))-1,"$a ";$S=join('',$T);}
The apporach is basic:
- Split the string into the names of the creatures
- Count how many elements there are
- Subtract 1 (an empty string would give an array with 1 element)
- Output the count and the creature name
- Join it all together, using an empty string (which will reduce the string and remove the last creature)
Easy, right?
Python 2, 78
n=input()
for x in"NBM BM NB M B N".split():n=`n`.split(x);print`len(n)-1`+x,
A variant of Vioz-'s answer. Fun with Python 2 string representations!
Counts occurrences of the substring indirectly by splitting on it, counting the parts, and subtracting 1. Instead of replacing the substrings by a filler symbol, replaces the string by the list that split produced. Then, when we take its string representation, the parts are separated by spaces and commas.
SpecBAS - 164
1 INPUT s$
2 FOR EACH a$ IN ["NBM","BM","NB","M","B","N"]
3 LET n=0
4 IF POS(a$,s$)>0 THEN INC n: LET s$=REPLACE$(s$,a$,"-"): GO TO 4: END IF
5 PRINT n;a$;" ";
6 NEXT a$
Uses the same approach as a lot of others. Line 4 keeps looping over the string (from largest first), replaces it if found.
SpecBAS has some nice touches over original ZX/Sinclair BASIC (looping through lists, finding characters) which I'm still finding out.
Pyth, 22 bytes
f|pd+/zTT=:zTd_.:"NBM
Quite hackish way to save 1 byte, thanks to @Jakube.
Pyth, 23 bytes
FN_.:"NBM")pd+/zNN=:zNd
Prints in reverse order, with a trailing space and no trailing newline.
.:"NBM") is all the substrings, _ puts them in the right order, /zN counts occurences, and =:zNd in-place substitutes each occurence of the string in question with a space.
FN_.:"NBM")pd+/zNN=:zNd
FN for N in :
_ reversed( )
.: ) substrings( )
"NBM" "NBM"
pd print, with a space at the end,
/zN z.count(N)
+ N + N
=:zNd replace N by ' ' in z.
R, 153 134 118
This got longer really quickly, but hopefully I'll be able to shave a few. Input is STDIN and output to STDOUT.
Edit Change of tack. Got rid of the split string and counting parts. Now I replace the parts with a string one shorter than the part. The difference between the string lengths is collected for output.
N=nchar;i=scan(,'');for(s in scan(,'',t='NBM BM NB M B N'))cat(paste0(N(i)-N(i<-gsub(s,strtrim(' ',N(s)-1),i)),s),'')
Explanation
N=nchar;
i=scan(,''); # Get input from STDIN
for(s in scan(,'',t='NBM BM NB M B N')) # Loop through patterns
cat( # output
paste0( # Paste together
N(i) - # length of i minus
N(i<-gsub( # length of i with substitution of
s, # s
strtrim(' ',N(s)-1) # with a space string 1 shorter than s
,i) # in i
),
s) # split string
,'')
Test run
> N=nchar;i=scan(,'');for(s in scan(,'',t='NBM BM NB M B N'))cat(paste0(N(i)-N(i<-gsub(s,strtrim(' ',N(s)-1),i)),s),'')
1: NNNMNBMMBMMBMMMNBMNNMNNNBNNNBNBBNBNMMNBBNBMMBBMBMBBBNNMBMBMMNNNNNMMBMMBM
2:
Read 1 item
Read 6 items
3NBM 8BM 5NB 14M 6B 17N
> N=nchar;i=scan(,'');for(s in scan(,'',t='NBM BM NB M B N'))cat(paste0(N(i)-N(i<-gsub(s,strtrim(' ',N(s)-1),i)),s),'')
1: NBMMBNBNBM
2:
Read 1 item
Read 6 items
2NBM 0BM 1NB 1M 1B 0N
>