| Bytes | Lang | Time | Link |
|---|---|---|---|
| 045 | Python3 | 241228T052414Z | Ben Stok |
| 005 | Uiua | 241226T165631Z | Europe20 |
| 005 | APLNARS | 241223T072648Z | Rosario |
| 017 | Juby | 241223T023702Z | Jordan |
| 029 | Red | 241219T074947Z | Galen Iv |
| 071 | Tcl | 241213T234249Z | sergiol |
| 023 | Raku Perl 6 rakudo | 241213T220657Z | xrs |
| 034 | Trilangle | 230222T042117Z | Bbrk24 |
| 032 | Haskell | 230918T082555Z | xnor |
| 355 | convey | 230906T135452Z | ZeroCode |
| 142 | Pascal | 230901T190019Z | Kai Burg |
| 024 | Zsh | 201208T191552Z | roblogic |
| 011 | x8616 machine code | 190102T172234Z | 640KB |
| 002 | Thunno 2 | 230607T172210Z | The Thon |
| 047 | Excel | 230225T121150Z | Jos Wool |
| 018 | Julia 1.0 | 230221T145739Z | Ashlin H |
| nan | 230222T202000Z | The Thon | |
| 021 | Arturo | 221111T114715Z | chunes |
| 045 | rSNBATWPL | 221111T155311Z | rydwolf |
| 013 | K ngn/k | 221111T131057Z | oeuf |
| 002 | Vyxal | 220706T173834Z | naffetS |
| nan | See also my unary regex answer. Although other posts have already used a regex that take decimal input | 220630T191817Z | Deadcode |
| 061 | Regex ECMAScript / Perl / PCRE / Python / .NET | 220630T053046Z | Deadcode |
| 8332 | FRACTRAN | 220421T223708Z | benrg |
| 002 | Japt v2.0a0 | 180904T102532Z | Shaggy |
| 003 | Vyxal Ṡ | 210817T204328Z | emanresu |
| 025 | Julia | 201208T142713Z | MarcMush |
| 002 | Pyth | 201207T225731Z | Scott |
| nan | 140521T195117Z | xnor | |
| 004 | Husk | 201207T204142Z | Dominic |
| 003 | Jelly | 201207T180501Z | caird co |
| 012 | Perl 6 | 190413T222258Z | Phil H |
| 022 | JavaScript | 190102T172836Z | Shaggy |
| 012 | Braingolf | 190102T153639Z | Mayube |
| 028 | C# Visual C# Interactive Compiler | 190102T113507Z | dana |
| 034 | R | 141221T195239Z | MickyT |
| 029 | Python 3 | 180904T132857Z | ArBo |
| 001 | Brachylog | 180903T153400Z | Erik the |
| 034 | Haskell | 180903T115643Z | ovs |
| 002 | 05AB1E | 171102T172734Z | Magic Oc |
| 007 | Add++ | 180405T141923Z | caird co |
| 026 | PARI/GP | 171103T214555Z | Jeppe St |
| 008 | J | 171102T150242Z | Galen Iv |
| 058 | C | 140521T211124Z | Level Ri |
| 138 | Go | 151202T122940Z | cat |
| 002 | Burlesque | 151202T110310Z | mroman |
| 049 | Prolog | 151202T105131Z | Emigna |
| 013 | Candy | 151202T050852Z | Dale Joh |
| 023 | Clojure | 141224T230539Z | user2063 |
| nan | 140522T000829Z | Sp3000 | |
| 017 | Regular Expression | 141224T155128Z | hetzi |
| 040 | Python | 141224T150256Z | Caridorc |
| 065 | R | 140522T111537Z | plannapu |
| 106 | Python 2.7 | 141221T131250Z | JamJar00 |
| 008 | J | 141220T211044Z | ɐɔıʇǝɥʇu |
| 008 | k4 | 140521T222534Z | Aaron Da |
| 057 | Java | 140615T111656Z | barteks2 |
| 082 | C++ | 140615T141039Z | bebe |
| 019 | Mathematica 20 | 140607T171305Z | sanchez |
| nan | 140522T202124Z | ClickRic | |
| 040 | POSIX sh and egrep | 140522T135654Z | Thor |
| 082 | F# | 140528T133939Z | Alexan |
| 028 | Julia 29 | 140522T163419Z | Glen O |
| 062 | C | 140523T080038Z | Alchymis |
| 041 | Haskell | 140526T150759Z | Hollow_N |
| 033 | PHP | 140522T112103Z | kuldeep. |
| nan | 140525T131957Z | DCKing | |
| 010 | Rebmμ | 140522T104426Z | HostileF |
| 052 | Clojure 42 | 140525T020615Z | user1004 |
| 184 | VB.NET | 140524T143237Z | Lou |
| 074 | PHP 74 Chars | 140524T010101Z | Sammitch |
| 025 | Mathematica | 140521T194029Z | Martin E |
| 052 | R | 140522T094700Z | djhurio |
| 059 | C# | 140522T091625Z | Num Lock |
| 087 | C | 140522T225954Z | DreamWar |
| 145 | VBA | 140522T210734Z | Alex |
| 100 | Extended BrainFuck | 140522T205235Z | Sylweste |
| 064 | C# 44 | 140522T200229Z | DLeh |
| nan | 140522T142833Z | Paul Joh | |
| 047 | Ruby47 characters | 140522T134108Z | bsd |
| 076 | C | 140521T224426Z | user1220 |
| 019 | Perl 6 | 140522T132057Z | null |
| 026 | PowerShell | 140522T132037Z | Rynant |
| 036 | Groovy | 140521T195535Z | Will Lp |
| 067 | C# | 140522T112516Z | mai |
| 063 | Perl | 140522T104242Z | Thorbj&# |
| 109 | Cobra | 140522T062032Z | Οurous |
| 024 | Ruby | 140522T041946Z | John Fem |
| 019 | Perl | 140521T194355Z | Tal |
| 017 | Befunge 98 | 140521T232216Z | Justin |
| 023 | JavaScript 23 Characters | 140521T225125Z | MT0 |
| 073 | Javascript | 140521T224509Z | pllee |
| 044 | Julia | 140521T210939Z | gggg |
| 072 | C# | 140521T204609Z | Paul Ric |
| 006 | APL | 140521T202956Z | marinus |
| 087 | Golfscript | 140521T193929Z | John Dvo |
| 009 | J | 140521T200808Z | ɐɔıʇǝɥʇu |
| 151 | C | 140521T194709Z | bacchusb |
| 059 | C99 | 140521T192055Z | Thomas |
Python3, 45 Bytes & Characters
def a(s):return len(str(s))==len(set(str(s)))
And a 32 byte version: (string and length already given)
def a(s,l):return l==len(set(s))
Uiua, 5 bytes
≍◴.°⋕
Explanation
Code | Description | Unique example | Repeating example
≍◴.°⋕ | Description | 10946 | 27462
°⋕ | Convert to string | "10946" | "27462"
. | Copy | "10946" "10946" | "27462" "27462"
◴ | Deduplicate | "10946" "10946" | "27462" "2746"
≍ | Check equality | 1 | 0
APL(NARS), 5 chars
≡∘∪⍨⍕
It would return in an numeric: 0 for false, 1 for true. Pheraps i don't understand why one other APL answer is 6 when can be 5... test
≡∘∪⍨⍕48778584
0
~
≡∘∪⍨⍕17308459
1
~
J-uby, 17 bytes
:digits|:==%:uniq
J-uby, 11 bytes
If we can take a string as input we can save six bytes.
A|:==%:uniq
Tcl, 71 bytes
puts [expr [llength [lsort -u [set L [split $argv ""]]]]==[llength $L]]
Raku (Perl 6) (rakudo), 23 bytes
{.comb.unique.join==$_}
{.comb # split num into array
.unique # keep uniques
.join # back together
==$_} # see if still the same
Trilangle, 34 bytes
UB is only disallowed in C, huh?
'0.<".@|>i\re@..j..2'2#!>.(&,\,<.-
This works on x64, at least. Can't guarantee it'll work on other architectures.
Expects the number on STDIN, immediately followed by EOF (no trailing newline). Prints "0" (with trailing newline) iff the digits are unique.
Edit: there is now an online interpreter. This code seems to work in wasm, too (but I still haven’t tested native ARM or other processors).
High-level Overview
Roughly equivalent to this C code:
#include <stdio.h>
int main() {
// A bitfield of the seen numbers:
// e.g. if "12" is input, this is 0b0000'0000'0000'0110;
// if "3" is input, this is 0b0000'0000'0000'1000; etc.
int seen = 0;
while (1) {
// Get a number in. If EOF is read,
// we haven't encountered a duplicate, so indicate success.
int i = getchar();
if (i == EOF) {
puts("0");
break;
}
// Check if the digit has already been seen.
// If so, exit without printing anything.
// If not, add this digit to the bitfield.
i = 1 << (i - '0');
if (i & seen) break;
seen = seen | i;
}
}
How does Trilangle work?
Trilangle is a 2-D programming language laid out in a triangular grid (hence the name). The IP can move in one of six directions; it starts heading southwest. If it walks off the edge of the grid, it continues one row or diagonal to its left.
The memory model is like a stack, but it's possible to index into it.
Explanation of the Code
The interpreter unfolds that code into this triangular grid:
'
0 .
< " .
@ | > i
\ r e @ .
. j . . 2 '
2 # ! > . ( &
, \ , < . - . .
I hope this explanation makes any sense. Here goes nothing.
Below is an image of the code, with the IP's paths highlighted in various colors.
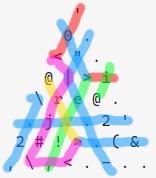
The IP starts on the red path, where it hits the following instructions:
'0: Push the number 0 to the stack<: Change the direction of control flowi: Get a character from STDIN and push it to the stack; pushes -1 on EOF>: Branch on the sign of the top of the stack
If the value is negative, EOF was read, and the IP continues on the green path:
e: Pop from the stack, and push1 << value. This is the UB:1 << -1is undefined. At least on x64, it evaluates to 0..: No-op!: Print the top of the stack as a decimal integer,: Pop from the stacki: Attempt to read from STDIN again (always sees EOF on this path)@: End program
The ,i aren't strictly necessary on this code path, but they're harmless to leave in.
If a character was successfully read, control flow continues on the blue path:
"0: Push the value of the character '0' (i.e. 48) to the stack-: Pop two values from the stack and push their difference..: No-opse: Pop from the stack and push1 << value|: Redirect control flow".,: Push the value of the character '.' and immediately pop it, effectively a no-op2: Duplicate the top of the stack.: Another no-op\: Redirect control flow'2: Push the number 2 to the stack..: Even more no-opsj: The indexing function. After this, the stack contains{ seen, i, i, seen }(from the C code above), in that order..: Yet another no-op&: Pop two values from the stack and pusha & b(bitwise and)(: Decrement the top of the stack. Ifseen & iis 0, the top of the stack is now negative; otherwise, it's still positive.: Yep, still a no-op>: Branch
If i and seen have any bits in common, the IP follows the yellow path; otherwise, the IP follows the magenta path.
The yellow path contains a harmless r (bitwise or) instruction, before the IP hits @ and the program ends.
On the magenta path, the IP continues as follows:
<: Redirect control flow,: Pop from the stack\: Redirect control flow#: Ignore the next instruction (j)r: Pop two values from the stack and pusha | b(bitwise or)|: Redirect control flow<: Redirect control flow, merging with the red path
From which it reads the next character from STDIN, and continues until it either reads the same character twice or reads EOF.
Disassembly
I recently added a --disassemble flag to the interpreter. The output is fairly straightforward if you understand the syntax:
0.0: PSI #0
0.2: GTC
0.3: BNG 2.0
1.0: PSC '0' ; 0x30
1.1: SUB
1.4: EXP
1.6: PSC '.' ; 0x2e
1.7: POP
1.8: DUP
1.11: PSI #2
1.14: IDX
1.16: AND
1.17: DEC
1.19: BNG 4.0
JMP 3.0
2.0: EXP
2.2: PTI
2.3: POP
2.4: GTC
2.5: EXT
3.1: IOR
3.2: EXT
4.1: POP
4.4: IOR
4.7: JMP 0.2
Haskell, 32 bytes
(\s->s==[x|x<-s,y<-s,x==y]).show
Repeats each character once per each character that equals it, and checks that this gives the original digits string.
convey, 355 bytes
1-} 1-} 1-} 1-} 1-} 1-} 1-} 1-} 1-} 1-}
>>vv<">>~>>?;~>>?;~>>?;~>>?;~>>?;~>>?;~>>?;~>>?;~>>?;~>>?;}
^ ;<1@>]3 >>!3 >>!3 >>!3 >>!3 >>!3 >>!3 >>!3 >>!3 >>!3 >>!
,{>">" >#v0 >#v0 >#v0 >#v0 >#v0 >#v0 >#v0 >#v0 >#v0 >#v0
.10|>#>>"@^>#"@^>#"@^>#"@^>#"@^>#"@^>#"@^>#"@^>#"@^>#"@^>#]
_<<<<%10>=0 1>=1 1>=2 1>=3 1>=4 1>=5 1>=6 1>=7 1>=8 1>=9 1
I don't believe that this was the more optimal solution in convey, but it's cool to see it running at least (You can watch all the process in the "Try it online" link):

Pascal, 142 bytes
This function requires a processor compliant with Extended Pascal, ISO standard 10206.
In particular the card function must be available.
function f(x:integer):Boolean;var d:set of 0..9;w:integer;begin d:=[];w:=0;repeat d:=d+[x mod 10];x:=x div 10;w:=w+1 until x=0;f:=w=card(d)end
Ungolfed:
type
{ This will permit a proper `function` domain restriction. }
integerNonNegative = 0..maxInt;
{ Returns `true` if `x` as decimal number contains no duplicate digits. }
function hasUniqueDecimalDigits(x: integerNonNegative): Boolean;
var
{ The decimal digits that appear in `x`. }
digits: set of 0‥9 value [];
{ The total width of a decimal representation of `x`. }
width: integer value 0;
begin
{ If there are as many distinct decimal `digits` as
the total `width` of the decimal number,
we can tell that no digit appears twice. }
repeat
begin
digits ≔ digits + [x mod 10];
x ≔ x div 10;
width ≔ width + 1;
end
until x = 0;
{ `card` returns the cardinalty of a set,
that is the number of members in a set. }
hasUniqueDecimalDigits ≔ card(digits) = width;
end;
Zsh, 28 24 bytes
If output is 0, the digits are unique. Otherwise, there are dupes
<<<$[$#1-${#${(us::)1}}]
x86-16 machine code, 11 bytes
FC 51 AC 8B FE F2 AE 59 E0 F7 C3
Listing:
SEARCH:
FC CLD ; string direction forward
51 PUSH CX ; save loop counter
AC LODSB ; load next digit from SI into AL, advance SI
8B FE MOV DI, SI ; DI is offset of next digit
F2/ AE REPNZ SCASB ; search until match, ZF=1 if found
59 POP CX ; restore loop counter
E0 F7 LOOPNZ SEARCH ; loop until match found or CX is 0
C3 RET ; return to caller
ENDM
Callable function, input as digit array at DS:SI, length in CX. Output ZF=0 if unique, ZF=1 if not unique.
Test program in IBM PC DOS that reads input from command line args, displays T or F:

Thunno 2, 2 bytes
U=
Explanation
U= # Implicit input
U # Uniquify the input
= # Does it equal the input?
# Implicit output
Excel, 47 bytes
=LET(a,ROW(1:10)-1,COUNT(SEARCH(a&"*"&a,A1))=0)
Input in cell A1.
Thunno, \$ 6 \log_{256}(96) \approx \$ 4.94 bytes
dDZUA=
Explanation
dDZUA= # Implicit input
dD # Cast to digits and duplicate
ZU # Uniquify this list
A= # Are they equal?
# Implicit output
Arturo, 27 26 21 bytes
$=>[=unique<=digits&]
-1 byte from abusing Arturo's hidden stack features. >:)
-5 bytes from using a tacit function and using the dup operator over the function.
Checks whether the list of digits of the input number is equal to itself when uniquified.
rSNBATWPL, 45 bytes
n~(d=1;rdc{norm{n}sort<}$a~b~(d=d*a!b;b);d)
A (probably golfable) approach, which looks for duplicate characters. Instead of a costly cast.string, I use norm, which applies Unicode normalization, which is a no-op here. I use rdc as an expensive hack to iterate over pairs. The most important part of the solution is d=d*a!b (I use d=d*... rather than d*=... since *= requires whitespace to prevent ambiguity), which multiplies d (initially 1) by a!b, which after being cast to an int will be 1 only if a and b aren't equal.
K (ngn/k), 13 bytes
{(#t)=#?t:$x}
I think there's a way this one could be a train...
Explanation:
{(#t)=#?t:$x} Main function. x is input
$x Convert x to string
t: Assign it to variable t
? Unique
# Length
= Equal to
(#t) The length of t
See also my unary regex answer. Although other posts have already used a regex that take decimal input, this post provides a unified presentation, and outgolfs some of the previous posts (including a language in which there wasn't previously any regex post).
Regex (ECMAScript or better), 13 bytes
^(?!(.)+.*\1)
Takes its input in decimal. Returns a match for numbers with all-unique digits.
Regex (ECMAScript or better), 7 bytes
(.).*\1
Takes its input in decimal. Returns a non-match for numbers with all-unique digits.
\$\large\textit{Anonymous functions}\$
R v3.5.2, 29 bytes
pryr::f(!grepl('(.).*\\1',n))
Uses the same regex as MickyT's R answer, but ,,T is unnecessary (the regex doesn't need to run in PCRE mode) and omitting it saves 3 bytes. Using pryr's lambda syntax saves another 2 bytes.
R v4.1.0+, 24 bytes
\(n)!grepl('(.).*\\1',n)
PHP, 35 bytes
fn($n)=>!preg_match('/(.).*\1/',$n)
Java, 33 bytes
n->!(n+"").matches("(.)+.*\\1.*")
This uses a regex 1 byte shorter than barteks2x's answer.
Perl, 19 bytes
sub{pop!~/(.).*\1/}
Ruby, 23 bytes
->n{n.to_s !~/(.).*\1/}
Takes an integer as input. Returns a native boolean, true if the digits are unique.
Ruby, 18 bytes
->s{s !~/(.).*\1/}
Takes a string as input. Returns a native boolean, true if the digits are unique.
This is identical to John Feminella's 20 byte answer except for removing the unnecessary parentheses surrounding the function parameter, saving 2 bytes.
\$\large\textit{Full programs}\$
Retina, 12 bytes
A`(.).*\1
^.
PHP, 37 bytes
<?=!preg_match('/(.).*\1/',$argv[1]);
Perl, 16 bytes
say<>!~/(.).*\1/
This uses a regex 1 byte shorter than Tal's answer. Another 2 bytes are saved by using say (requiring Perl v5.010+) instead of print.
Regex (ECMAScript / Perl / PCRE / Python / .NET), 66 61 bytes
^(?!((?=(x{10})*(x*))(^|(?=(x*)(\5{9}x*))\6)+){2}\B\2*\3$)|^$
Takes its input in unary, as the length of a string of xs.
Try it online! - ECMAScript
Try it online! - Perl
Try it online! - PCRE
Try it online! - Python
Try it online! - .NET
This regex apparently does not work in Java, Boost, or Ruby. The reasons are unknown as of yet.
^ # tail = N = input number
(?! # Assert that there is no way for the below to match
(
(?=
(x{10})*(x*) # \2 = 10; \3 = tail % 10
)
(
^ # Allow the loop to iterate once without doing
# anything iff this is the first iteration of the
# main loop.
|
(?=
(x*) # \5 = floor(tail / 10)
(\5{9}x*) # \6 = tool to make tail = \5
)\6 # tail = \5
)+ # Execute the above loop an arbitrary positive
# number of times.
){2} # Execute the above loop exactly twice, so that \3
# will contain the value it had at the beginning of
# the loop's second iteration.
\B # Assert that we aren't at the beginning or end, or
# that N==0; the latter "or" part is undesirable,
# because it prevents this main algorithm from being
# able to match N==0, but even still, using "(?!^|$)"
# would be longer than "\B" and "|^$" combined.
# Note that if (x{10})* repeated zero times, \2 will be a non-participating
# capture group (unset). In ECMAScript this means it will behave as if \2=0.
# In all other flavors, it means \2* will only be able to repeat zero times,
# because \2 alone won't match anything. But this doesn't matter, since if
# it was only able to match zero times before, it wouldn't be able to match
# more than zero times now, anyway.
\2*\3$ # Assert tail % 10 != \3
)
|^$ # Match N==0, which the main algorithm above can't.
See also my decimal regex answer. I feel that this unary version is more interesting, especially since unary is like a native integer data format for regex, whereas decimal is like passing an integer as a string, but it's definitely worth presenting decimal versions as well.
FRACTRAN, 15 fractions, 83 (or 32) bytes
This beats Sp3000's 38-fraction solution.
$$\frac25,\frac{875}{88},\frac78,\frac{25{\cdot}17^c}{92},\frac14,\frac{15}{38},\frac{69}{2},\frac{23}{17},\frac{19}{3^b},\frac43,\frac{7}{23},\frac{26}{19},\frac{11}{7^c},\frac{1}{91},\frac{8}{11}$$
The initial state is \$3^n\cdot 13\cdot 23\$. It halts at \$1\$ if every digit in the base-\$b\$ representation of \$n\$ occurs fewer than \$c\$ times, and at some other value otherwise. Plug in \$b=10, c=2\$ to get the answer to the challenge as posed.
The final state is actually \$13^{k - \mathrm{wt}_c\left(\sum c^{d_i}\right)}\$, where \$d_1\cdots d_k\$ are the base-\$b\$ digits of \$n\$, and \$\mathrm{wt}_c\$ is the base-\$c\$ digit sum. Adding a power of \$c\$ increases the digit sum by \$1\$ if there is no carry, and doesn't increase it if there is a carry, so the final state is \$1\$ iff each digit occurs fewer than \$c\$ times.
The length of the \$b=10, c=2\$ version is 83 bytes in the decimal coding (2/5,875/88,...) that seems to be standard here. With a more efficient coding (Elias δ), it's 32 bytes.
There's a fast online interpreter here. I see no way to encode a program in the URL, so you'll have to copy-paste this:
2%5 875%88 7%8 25*17^2%92 1%4 15%38 69%2 23%17 19%3^10 4%3 7%23 26%19 11%7^2 1%91 8%11
Then enter, e.g., [3,48778584],[13,1],[23,1] as the input.
Julia, 25 bytes
the best I could come up with was the same as one of the top voted answers
n->10^length(Set("$n"))>n
Python 2 (28) (32)
lambda n:10**len(set(`n`))>n
The backticks take the string representation. Converting to a set removes duplicates, and we check whether this decreases the length by comparing to 10^d, which is bigger than all d-digit number but no (d+1)-digit numbers.
Old code:
lambda n:len(set(`n`))==len(`n`)
Husk, 4 bytes
S=ud
S # Hook: S fgx means f x(gx)
= # are they equal:
# x (implied by S)
# and
u # unique elements of x
d # when x is the decimal digits of the input
Jelly, 3 bytes
DQƑ
How it works
DQƑ - Main link. Takes n on the left
D - Convert to digits
Ƒ - Is it unchanged under:
Q - Deduplication?
Braingolf, 12 bytes
dlMulMve1:0|
Explanation
dlMulMve1:0| Implicit input from args
d Split into digits
lM Push length of stack to next stack
u Keep only first occurrence of each unique digit
lM Push length of stack to next stack
v Switch to next stack
e If top 2 items are equal
1 - Push 1
: Else
0 - Push 0
| EndIf
Implicit output of top of stack
C# (Visual C# Interactive Compiler), 28 bytes
i=>(i+"").ToDictionary(c=>c)
This lambda uses presence or absence of an exception to determine whether a number has unique digits. If a digit occurs more than once, a duplicate key exception will be thrown when converting the string to a dictionary.
R, 53 51 48 34 Bytes
function(n)!grepl("(.).*\\1",n,,T)
Convert to a string and split. Convert to a table of counts minus 1, sum and negate
Inspired by Most common number answer by Alex and suggestion by Hugh.
A couple saved, thanks to @plannapus One more from @Gregor And a couple from making it an anonymous function
Now with wonderful regex goodness thanks to @J.Doe. This looks for any single char in the number that matches itself else where in the string. The grepl command returns a logical that is then returned. Perl style regexes is set to True.
Python 3, 29 bytes
lambda x:10**len({*str(x)})>x
Inspired on this answer in Python 2; for Python 3 to only lag behind 2 by one byte is pretty rare :)
05AB1E, 2 bytes
ÙQ
-1 thanks to Kaldo
{ # Sort.
¥ # Consecutive differences.
P # Product.
Works on negatives, though OP never specified...
J, 8 bytes
-:~.&.":
Explanation:
": - converts the integer to a string
&. - "under" conjuction - uses the result from ": as operand to ~.
then applies the inverse to the result, so converts the string back to integer
~. - removes duplicates
-: - matches the operands
So, it first converts the number to a string, removes the duplicates and converts the resulting string to a number. Then the original number is matched against the transformed one.
In fact it is a hook of two verbs: -: and ~.&.":
┌──┬──────────┐
│-:│┌──┬──┬──┐│
│ ││~.│&.│":││
│ │└──┴──┴──┘│
└──┴──────────┘
C, 58 bytes
f;a(x){for(f=0;x;x/=10)f+=1<<x%10*3;return!(f&920350134);}
Can keep a tally of up to 7 identical digits before rolling over.
in test program (it's easier to see how it works with the constant in octal)
a(x){int f=0;for(;x;x/=10)f+=1<<x%10*3;return!(f&06666666666);}
main(){
scanf("%d",&r);
printf("%o\n",a(r));}
If you happen to have a large power of 2 handy the constant can be calculated like f&(1<<30)/7*6
Go, 138 bytes
Bad language choice.
run it like uniqchars 112345678
package main
import(."fmt"
."os"
."strings")
func main(){s:=Args[1]
f:=true
for _,e:=range s{if Count(s,string(e))>1{f=false}}
Println(f)}Burlesque, 2 bytes
Using the Unique built-in:
blsq ) 17308459U_
1
blsq ) 48778584U_
0
Prolog, 49 bytes
Code:
p(N):-number_codes(N,L),sort(L,S),msort(L,T),S=T.
Explained:
p(N):-number_codes(N,L), % Convert int to list (of charcodes)
sort(L,S), % Sort list and remove duplicates
msort(L,T), % Sort list and keep duplicates
S=T. % Check if lists are equal
Example:
p(48778584).
false
p(17308459).
true
Candy, 13 bytes
This is a late post, but...
(k&{1k1.|0})0
Invokation with -I , which is actually for string parameters.
The long form:
while # while we are still consuming characters from the stack
setSP # pop the next stack-id from the stack. It's the ord of the digit
stackSz # test for empty stack
if
digit1 setSP # goto stack #1, and push the true indicator on
digit1
retSub # and halt
else
digit0 # mark the stack as having been visited
endif
endwhile
digit0 # push the false indicator if we got this far
Clojure, 23
#(=(distinct x)(seq x))
Usage: (#(=(distinct x)(seq x)) "23563462464543")
FRACTRAN - 53 38 fractions
47/10 3/5 106/47 3599/54272 53/61 2881/27136 2479/13568 2077/6784 1943/3392 1541/1696 1273/848 1139/424 871/212 737/106 469/53 142/3953 67/71 5/67 1/147 1/363 1/507 1/867 1/1083 1/1587 1/2523 1/2883 1/4107 1/5547 1/7 1/11 1/13 1/17 1/19 1/23 1/29 1/31 1/37 1/43
Uses division to count the number of occurrences of each digit. Call by putting n in register 2 and setting register 5 to 1, gives output in register 3 (0 if false, 1 if true). Also, make sure the rest of your program uses only registers > 71.
Edit 25/12/14: It's been 7 months and we've since gotten Stack Snippets, so here's one to test the code (using my could-be-better interpreter here).
var ITERS_PER_SEC=1E5;var TIMEOUT_MILLISECS=5E3;var ERROR_INPUT="Invalid input";var ERROR_PARSE="Parse error: ";var ERROR_TIMEOUT="Timeout";var ERROR_INTERRUPT="Interrupted by user";var running,instructions,registers,timeout,start_time,iterations;function clear_output(){document.getElementById("output").value="";document.getElementById("stderr").innerHTML=""};function stop(){running=false;document.getElementById("run").disabled=false;document.getElementById("stop").disabled=true;document.getElementById("clear").disabled=false}function interrupt(){error(ERROR_INTERRUPT)}function error(msg){document.getElementById("stderr").innerHTML=msg;stop()}function factorise(n){var factorisation={};var divisor=2;while(n>1){if(n%divisor==0){var power=0;while(n%divisor==0){n/=divisor;power+=1}if(power!=0)factorisation[divisor]=power}divisor+=1}return factorisation};function fact_accumulate(fact1,fact2){for(var reg in fact2)if(reg in fact1)fact1[reg]+=fact2[reg];else fact1[reg]=fact2[reg];return fact1};function exp_to_fact(expression){expression=expression.trim().split(/\s*\*\s*/);var factorisation={};for(var i=0;i<expression.length;++i){var term=expression[i].trim().split(/\s*\^\s*/);if(term.length>2)throw"error";term[0]=parseInt(term[0]);if(isNaN(term[0]))throw"error";if(term.length==2){term[1]=parseInt(term[1]);if(isNaN(term[1]))throw"error";}if(term[0]<=1)continue;var fact_term=factorise(term[0]);if(term.length==2)for(var reg in fact_term)fact_term[reg]*=term[1];factorisation=fact_accumulate(factorisation,fact_term)}return factorisation}function to_instruction(n,d){instruction=[];divisor=2;while(n>1||d>1){if(n%divisor==0||d%divisor==0){reg_offset=0;while(n%divisor==0){reg_offset+=1;n/=divisor}while(d%divisor==0){reg_offset-=1;d/=divisor}if(reg_offset!=0)instruction.push(Array(divisor,reg_offset))}divisor+=1}return instruction};function run(){clear_output();document.getElementById("run").disabled=true;document.getElementById("stop").disabled=false;document.getElementById("clear").disabled=true;timeout=document.getElementById("timeout").checked;var code=document.getElementById("code").value;var input=document.getElementById("input").value;instructions=[];code=code.trim().split(/[\s,]+/);for(i=0;i<code.length;++i){fraction=code[i];split_fraction=fraction.split("/");if(split_fraction.length!=2){error(ERROR_PARSE+fraction);return}numerator=parseInt(split_fraction[0]);denominator=parseInt(split_fraction[1]);if(isNaN(numerator)||isNaN(denominator)){error(ERROR_PARSE+fraction);return}instructions.push(to_instruction(numerator,denominator))}try{registers=exp_to_fact(input)}catch(err){error(ERROR_INPUT);return}running=true;iterations=0;start_time=Date.now();fractran_iter(1)};function regs_to_string(regs){reg_list=Object.keys(regs);reg_list.sort(function(a,b){return a-b});out_str=[];for(var i=0;i<reg_list.length;++i)if(regs[reg_list[i]]!=0)out_str.push(reg_list[i]+"^"+regs[reg_list[i]]);out_str=out_str.join(" * ");if(out_str=="")out_str="1";return out_str};function fractran_iter(niters){if(!running){stop();return}var iter_start_time=Date.now();for(var i=0;i<niters;++i){program_complete=true;for(var instr_ptr=0;instr_ptr<instructions.length;++instr_ptr){instruction=instructions[instr_ptr];perform_instr=true;for(var j=0;j<instruction.length;++j){var reg=instruction[j][0];var offset=instruction[j][1];if(registers[reg]==undefined)registers[reg]=0;if(offset<0&®isters[reg]<-offset){perform_instr=false;break}}if(perform_instr){for(var j=0;j<instruction.length;++j){var reg=instruction[j][0];var offset=instruction[j][1];registers[reg]+=offset}program_complete=false;break}}if(program_complete){document.getElementById("output").value+=regs_to_string(registers);stop();return}iterations++;if(timeout&&Date.now()-start_time>TIMEOUT_MILLISECS){error(ERROR_TIMEOUT);return}}setTimeout(function(){fractran_iter(ITERS_PER_SEC*(Date.now()-iter_start_time)/1E3)},0)};<div style="font-size:12px;font-family:Verdana, Geneva, sans-serif;"><div style="float:left; width:50%;">Code:<br><textarea id="code" rows="4" style="overflow:scroll;overflow-x:hidden;width:90%;">47/10 3/5 106/47 3599/54272 53/61 2881/27136 2479/13568 2077/6784 1943/3392 1541/1696 1273/848 1139/424 871/212 737/106 469/53 142/3953 67/71 5/67 1/147 1/363 1/507 1/867 1/1083 1/1587 1/2523 1/2883 1/4107 1/5547 1/7 1/11 1/13 1/17 1/19 1/23 1/29 1/31 1/37 1/43</textarea><br>Input:<br><textarea id="input" rows="2" style="overflow:scroll;overflow-x:hidden;width:90%;">2^142857 * 5</textarea><p>Timeout:<input id="timeout" type="checkbox" checked="true"></input></p></div><div style="float:left; width:50%;">Output:<br><textarea id="output" rows="6" style="overflow:scroll;width:90%;"></textarea><p><input id="run" type="button" value="Run" onclick="run()"></input><input id="stop" type="button" value="Stop" onclick="interrupt()" disabled="true"></input><input id="clear" type="button" value="Clear" onclick="clear_output()"></input> <span id="stderr" style="color:red"></span></p></div></div>Replace 142857 with another number. Output should be 3^1 if true, 1 = 3^0 if false. Takes a while for larger numbers (well, this is FRACTRAN...).
Regular Expression 17 bytes
^(?:(.)(?!.*\1))*$
Original expression taken from https://stackoverflow.com/a/12870549.
Python, 40
f=lambda x:len(str(x))==len(set(str(x)))
The built-in set removes the duplicates, so if the length of a thing and the length of his set are equal, the thing does not have repeated elements.
R, 66 65 characters
f=function(x)!sum(duplicated((x%%10^(i<-1:nchar(x)))%/%10^(i-1)))
Separate the digits using integer division and modulo, then check if they are duplicates.
Usage:
> f(48778584)
[1] FALSE
> f(17308459)
[1] TRUE
Or, as @MickyT suggested, for 63 characters:
f=function(x)!anyDuplicated((x%%10^(i<-1:nchar(x)))%/%10^(i-1))
Python 2.7 114 106 bytes
First golf, and this is no way going to win :P
def d(a):
f=[];
for i in str(a):
if i in f:return False
f.append(i)
return True
Kinda want to see how other people would improve this :)
EDIT: With ProgramFOX's comments:
def d(a):
f=[];
for i in str(a):
if i in f:return 1<0
f+=[i];
return 0<1
J (8)
Competely sepertae from my previous answer.
*/@~:@":
k4 (8)
{x=.?$x}48778584
0b
{x=.?$x}17308459
1b
inspired by a combination of the J and Golfscript answers
Java ( 131 59 57)
57 characters:
removed ^ and $ as @n̴̖̋h̷͉̃a̷̭̿h̸̡̅ẗ̵̨́d̷̰̀ĥ̷̳ suggested
boolean u(int n){return !(n+"").matches(".*(.).*\\1.*");}
59 characters (works also with negative numbers!):
boolean u(int n){return !(n+"").matches("^.*(.).*\\1.*$");}
79 78 characters (thanks @n̴̖̋h̷͉̃a̷̭̿h̸̡̅ẗ̵̨́d̷̰̀ĥ̷̳ ):
Use for loop to save a few charachers and use int as a boolean array.
Use & instead of && to save 1 character (It turns out that java allows it).
boolean u(int n){for(int x=0;n>0&(x>>n%10&1)==0;n/=10)x|=1<<n%10;return n==0;}
131 characters (returns true for negative numbers):
boolean u(int n){int[] p=new int[]{2,3,5,7,11,13,17,19,32,29};double a=9001312320D;while(n>0){a/=p[n%10];n/=10;}return (long)a==a;}
with comments:
boolean unique(int n){
int[] p=new int[]{2,3,5,7,11,13,17,19,32,29};//list of 10 first primes
double a=9001312320D;//10 first primes multiplied
while(n>0){
a/=p[n%10];//divide by (n%10+1)th prime
n/=10;//divide n by 10, next digit
}
return (long)a==a;//if a is integer then n has all digits unique
}
And answer that is technically correct (character count includes only the function, not global variables), but I think it's cheating, 29 characters:
boolean u(int i){return m[i];}
m[] is boolean array that contains correct answers for all 32-bit integers.
C++ 82
this code is at least legitimate
int a(uint32_t i,uint32_t r=0,uint32_t h=0)
{return i?r&h?0:a(i/10,r|h,1<<i%10):1;} // thanks to DreamWarrior
C 47
this works if you compile it in debug mode or provide two more arguments set to 0
a(i,r,h){return i?r&h?0:a(i/10,r|h,1<<i%10):1;}
Mathematica (20 19)
(22 21 if function needs a name)
Max@DigitCount@#<2&
or
Max@DigitCount@#|1&
where | ist entered as [Esc]divides[Esc]
COBOL 66 with Object Cobol extensions
Microfocus Cobol (721 659 592)
method-id u.
local-storage section.
77 i pic s9(9) comp.
77 c pic 9 occurs 10 value 0.
77 g pic 9.
01 s pic 9(9).
01 t redefines s pic 9 occurs 9.
linkage section.
77 n pic s9(9) comp.
77 d pic x.
88 f value is 'y'.
procedure division using by value n returning d.
move n to s. move 'n' to d. perform p varying i from 1 by 1 until i greater than 9 or f. goback.
p. move t (i) to g. if c (g) is not zero then move 'y' to d. add 1 to c (g).
end method.
Hmmm, I think I should go back to pitch & putt :(
EDIT: OMGZ I CAN USE LOWER CASE!!!
POSIX sh and egrep (47, 43, 40)
f()([ ! `echo $1|egrep '([0-9]).*\1'` ])
- [-1 char]: Use
!instead of-zwithtest- Thanks DigitalTrauma - [-1 char]: Use
`CODE`instead of$(CODE)- Thanks DigitalTrauma - [-2 chars]: Use
fold -1instead ofgrep -o .1 - Thanks DigitalTrauma. - [-3 chars]: Check for repeated digits with a backreferenced regular expression.
If POSIX compliance is not important echo PARAM | can be replaced by <<<PARAM, reducing the functions length to 37:
f()([ ! `egrep '([0-9]).*\1'<<<$1` ])
Usage:
$ if f 48778584; then echo true; else echo false; fi
false
$ if f 17308459; then echo true; else echo false; fi
true
1 The fold -N notation is deprecated in some versions of fold.
F# - 82
let f i =
let s = i.ToString()
s |> Set.ofSeq|> Seq.length = s.Length;;
Julia - 29 28
f(n)=unique("$n")=="$n".data
Old version:
f(n)=join(unique("$n"))=="$n"
C - 62
int m[10];f(int a){while(m[a%10]++?0:a/=10);return m[a%10]<2;}
I've included the count of the globally declared array (which ensures initialisation to 0).
As a bonus, here is a much shorter technically correct answer:
f(int a){return 1}
The question does not state that non-unique digits should return false. Therefore I claim the current lead for C code with 18 characters, although I expect to be beaten by a scripting language with an answer like:
1
Haskell (41)
import Data.List
f x=show x==nub(show x)
About 23 characters shorter than the other Haskell answer and a fair bit more intuitive I think. Basically the same process but using Haskell's built-in list functions is much easier and shorter.
PHP - 44 33
var_dump(max(count_chars($n))<2);
Or Proper function 42 Characters
function(){return max(count_chars($n))<2;}
UPDATE : Thanks for @scrblnrd3 pointed out for shorter solution.
Scala
Cheating with library functions (29/12 characters):
def t(i:String)=i==i.distinct
Scala version of the GolfScript version (36/19 characters):
def t(i:String)=i.intersect(i).size>0
Doing the counting work manually (91/74 characters):
def t(i:String)=(Map.empty[Char,Int]/:i)((m,c)=>m+(c->(m.getOrElse(c,0)+1))).forall(_._2<2)
Rebmμ (10 characters)
e? AtsAuqA
Rebmu's "mushing" trick is that it's case-insensitive, so characters are run together. Whenever a case transition is hit, that splits to the next token. By using transitions instead of a CamelCase kind of thing, the unique choice to start with a capital run means a "set-word" is made. (While set-words can be used for other purposes in symbolic programming, they are evaluated as assignments by default).
So this "unmushes" to:
e? a: ts a uq a
The space is needed because once you've begun a series of runs of alternating cases, you can't use that trick to get a set-word after the first unless you begin a new run. So e?AtsAuqA would have gotten you e? a ts a uq a...no assignment.
(Note: For what may be no particularly good reason, I tend to prefer rethinking solutions so that there are no spaces, if character counts are equal. Since brackets, parentheses, and strings implicitly end a symbol...there are often a fair number of opportunities for this.)
In any case, when mapped to the Rebol that it abbreviates:
equal? a: to-string a unique a
Throwing in some parentheses to help get the gist of the evaluation order:
equal? (a: (to-string a)) (unique a)
So the prefix equality operator is applied to two arguments--the first the result of assigning to a of the string version of itself, and the second the result of unique being run against that string. It so happens that unique will give you back the elements in the same order you passed them...so unique of "31214" is "3124" for instance.
Run it with:
>> rebmu/args "e? AtsAuqA" 17308459
== true
There's also some stats and debug information:
>> rebmu/args/stats/debug "e? AtsAuqA" 48778584
Original Rebmu string was: 10 characters.
Rebmu as mushed Rebol block molds to: 10 characters.
Unmushed Rebmu molds to: 15 characters.
Executing: [e? a: ts a uq a]
== false
If the requirement is that one must define a named/reusable function you can make an "A-function" which implicitly takes a parameter named a with a|. (A B-function would be created with b| and take a parameter named A then one named B). So that would add five more characters...let's say you call the function "f"
Fa|[e? AtsAugA]
"You laugh! They laughed at Einstein! Or wait...did they? I...don't know."
Clojure - (42 - 52)
As a named function (52):
(defn f[i](let[s(str i)](=(count s)(count(set s)))))
As an anonymous function (42):
#(let[s(str %)](=(count s)(count(set s))))
VB.NET - 189 184
Function U(I As Integer) As Boolean
U = True
Dim D(9)
Dim S = I.ToString
For Each E As Char In S
If IsNumeric(E) Then If D(Val(E)) + 1 > 1 Then U = False Else D(Val(E)) += 1
Next
End Function
First code-golf attempt. I'm aware it's an unsuitable language and poor result, but I wanted to try.
PHP 74 Chars
<?php $a=str_split($argv[1]);var_dump(count($a)==count(array_unique($a)));
Mathematica, 35 25 characters
(27 if the function needs a name.)
Unequal@@IntegerDigits@#&
EDIT: Saved 8 characters thanks to belisarius!
R (70, 60, 53, 52)
Thank you all for the useful comments! Your comments are incorporated in the answer.
### Version 70 chars
f=function(x)!any(duplicated(strsplit(as.character(x),split="")[[1]]))
### Version 60 chars
f=function(x)all(table(strsplit(as.character(x),"")[[1]])<2)
### Version 53 chars
f=function(x)all(table(strsplit(paste(x),"")[[1]])<2)
### Version 52 chars
f=function(x)all(table(strsplit(c(x,""),"")[[1]])<2)
f(48778584)
f(17308459)
C# 73 60 59
First golfing for me ...
Write a function that takes a nonnegative integer as input
bool f(int i){return(i+"").Distinct().SequenceEqual(i+"");}
Could strip another character by converting
Here we go ...uint to int, but I rather take the task too literally than the other way around.
C (87)
Since I can't win, I'll go for efficiency.
Function code:
int u(uint32_t d){short s=0,f;while(d){f=1<<d%10;if(s&f)return 0;s|=f;d/=10;}return 1;}
VBA (145)
Function jkl(f As String) As Boolean
For i = 1 To Len(f)
jkl = InStr(1, f, Left(Mid(f, i), 1)) <> i
If jkl = True Then Exit Function
Next
End Function
Calling the function and output with opposite of the result:
Sub jj()
Dim f As String
f = "1234256789"
MsgBox Not (jkl(f))
End Sub
Extended BrainFuck: 100
not included the unnecessary linefeed.
{a>[>>]}>>,10-[38-[-&a+[<<]>]&a>[[-]3<[-<<]<+2>&a>]
+3<[-<<]>,10-]<+<([-]>-|"false"[-])>(-|"true"[-])
Usage:
%> beef ebf.bf < unqiue.ebf > unqiue.bf
%> echo 48778584 | beef unique.bf
-> false
%> echo 17308459 | beef unique.bf
-> true
C# (44 - 64)
Func
As a lambda (44):
y=>!(y+"").GroupBy(x=>x).Any(x=>x.Count()>1)
alt lambda (also 44):
y=>(y+"").GroupBy(x=>x).All(x=>x.Count()==1)
As a Func (63):
Func<int, bool> f=y=>(y+"").GroupBy(x=>x).All(x=>x.Count()==1);
As a method (64):
bool f(int y){return (y+"").GroupBy(x=>x).All(x=>x.Count()==1);}
Haskell:
import Data.List
all ((== 1) . length) . group . sort . show
Ruby(47 characters)
->(x){x.to_s.chars.sort.uniq.size==x.to_s.size}
Example usage
->(x){x.to_s.chars.sort.uniq.size==x.to_s.size}[10]
=> true
C, 76
This is no where near winning, but I'll post it anyway just to show an alternative approach.
c;i;a[99];main(){while(~(c=getchar()))a[c]++;for(;i<99;)a[i++]>1&&puts("");}
Prints a new line if false, prints nothing if true.
Perl 6 (19 bytes)
{.comb.uniq==.comb}
.comb splits a string into characters (for example, 42.comb gives "4", "2"). .uniq removes all non-unique characters. .comb characters in string (originally I used .chars, but .comb is shorter). == converts lists into number of elements in it, and compares the numbers. When . is used without object before, $_ which is default function parameter is assumed. {} are function literals.
PowerShell - 26
!($args|sls '(.)(?=.*\1)')
Groovy (36 chars)
f={s="$it" as List;s==s.unique(!1)}
Tested it using:
println f(args[0].toInteger())
C# 72 69 67 characters (no libraries needed)
for(;d>0;d/=10)for(int f=d/10;f>0;f/=10)if(d%10==f%10) return true;
Ungolfed:
for (; d > 0; d /= 10)
for (int f = d / 10; f > 0; f /= 10)
if (d % 10 == f % 10)
return true;
I'm just using simple maths here.(i.e. number 1231):
- Take the last digit (1)
- Iterate through the quotient (123)
- If the number is equal to our digit (1), then return true
- 3 == 1, 2 == 1, 1 == 1 - found it!
Perl, 63ish
$ echo 48778584| perl -F// -alpe '$"="";$_= 0<"@{[map {$a{$_}++} @F]}"?"false":"true"'
false
$ echo 17308459| perl -F// -alpe '$"="";$_= 0<"@{[map {$a{$_}++} @F]}"?"false":"true"'
true
Cobra - 109
def f(n) as bool
l=0
m=n.toString
for i in m,for j in m,if i==j,l+=1
return if(l>m.length,false,true)
Makes me wish that LINQ would work properly in Cobra.
Ruby (24 bytes)
Use a regular expression to match "some character, followed by zero or more characters, then the same character".
->(s){!!(s !~/(.).*\1/)}
If truthy or falsy values are accepted, rather than literal true or false, then we get 20 characters:
->(s){s !~/(.).*\1/}
Perl, 19 characters
print<>!~/(\d).*\1/
Befunge 98, 17 bytes
This is a non-competing answer because Befunge does not have functions.
~:1g1`j@1\1p3j@.1
Prints a 1 if the number's digits are all unique; otherwise, it just ends.
This works by accessing a cell in the Funge space whose x coordinate is the ASCII value of the character inputted (takes input character by character) and whose y coordinate is 1. If the digit has not been seen before, the value of the cell is 32 (space character). If that is so, I set the value to 1.
As a bonus, this works for non-numbers as well.
JavaScript - 23 Characters
As a function (ECMAScript 6):
f=x=>!/(.).*\1/.test(x)
Or taking input from a prompt (25 characters)
!/(.).*\1/.test(prompt())
Javascript 73 chars
function f(n){return !~(n+'').split('').sort().join('').search(/(\d)\1/)}
Julia, 44
f(n)=(d=digits(n);length(Set(d))==length(d))
C# 72 characters
var a=i.ToString().ToCharArray();
return a.Distinct().Count()==a.Count();
APL (6)
≡∘∪⍨∘⍕
One of the few times where tacit style is shorter in APL too.
It's 8 characters to give it a name,
f←≡∘∪⍨∘⍕
but that's not necessary to use it:
≡∘∪⍨∘⍕ 199
0
≡∘∪⍨∘⍕ 198
1
f←≡∘∪⍨∘⍕
f¨ 198 199 200 201
1 0 0 1
≡∘∪⍨∘⍕¨ 198 199 200 201
1 0 0 1
Golfscript, 8 7 characters:
{`..&=}
`- stringify the argument..- clone twice&- intersect with itself (remove duplicates)=- check for equality.
if the function needs to be named (10 9 characters):
{`..&=}:a
if a program suffices (5 4 characters):
..&=
J (9)
Assumes the value to be tested is in variable b (I know this can be made into a function, but don't have a clue on how. J is confusing. Any help on this is appreciated) Thanks Marinus!
(-:~.)@":
Checks if the lenght of the string rep of the number with all the duplicates removed is the same as the lenght of the regular string rep.
C 151
Bytes = 181 or 151 without newline chars. Program keeps a tally of digits and exits if greater than 1.
#include <stdio.h>
int i,j[10],r;
int main()
{
scanf("%d",&i);
do{
r=i%10;
j[r]++;
if(j[r]>1){printf("false");return 0;}
i/=10;
}while(i);
printf("true");
return 0;
}
C99, 59 chars
a(x){int r=1,f[10]={};for(;x;x/=10)r&=!f[x%10]++;return r;}