| Bytes | Lang | Time | Link |
|---|---|---|---|
| 012 | Dyalog APL | 250818T202446Z | Aaron |
| 008 | Pip | 211216T204132Z | DLosc |
| 055 | Vyxal | 211215T030924Z | lyxal |
| 006 | Thunno 2 J | 230816T122132Z | The Thon |
| 023 | K ngn/k | 220408T125800Z | coltim |
| 047 | Julia 1.7 | 220408T121754Z | MarcMush |
| 068 | PHP5.1 | 220408T033200Z | user1117 |
| 072 | Python 3.8 | 211216T191351Z | spyr03 |
| 076 | Python 3.8 | 211215T031630Z | Ajax1234 |
| 046 | PowerShell 6+ | 211217T125536Z | mazzy |
| 087 | Python3 | 211228T233817Z | Richard |
| 064 | Scala | 211222T201345Z | cubic le |
| nan | C | 211215T045553Z | Lucas Em |
| 007 | 05AB1E | 211215T043834Z | wasif |
| 084 | Lua | 211219T025943Z | Visckmar |
| 6444 | bash | 211216T200607Z | bas |
| 073 | Haskell | 211215T085244Z | Madison |
| 008 | Husk | 211215T122805Z | Dominic |
| 050 | PowerShell | 211215T135446Z | user3141 |
| 023 | Perl 5 + p | 211215T092012Z | Dom Hast |
| 052 | Wolfram Language Mathematica | 211215T055048Z | att |
| 063 | JavaScript ES6 | 211215T085518Z | Arnauld |
| 168 | TSQL | 211215T134353Z | t-clause |
| 118 | Java 8 | 211215T143708Z | Kevin Cr |
| 024 | Retina 0.8.2 | 211215T140734Z | Neil |
| 072 | R | 211215T130537Z | Giuseppe |
| 069 | R | 211215T053003Z | pajonk |
| 028 | BQN | 211215T111310Z | ovs |
| 044 | APL+WIN | 211215T104720Z | Graham |
| 010 | Charcoal | 211215T095943Z | Neil |
| 064 | JavaScript Node.js | 211215T092107Z | emanresu |
| 066 | PHP | 211215T083736Z | Kaddath |
| 056 | Factor + spelling | 211215T055848Z | chunes |
| 048 | Ruby | 211215T045451Z | G B |
| 064 | Python 2 | 211215T034858Z | dingledo |
| 008 | Jelly | 211215T034241Z | Unrelate |
Dyalog APL, 12 chars
{∊⍕¨≢⍤⊢⌸⎕C⍵}
⎕C # Lowercase
⌸ # Key (group by equivalent major cells)
≢⍤⊢ # returning the count of the right argument (the indices where this major cell -- the letter -- appears)
⍕¨ # Format each
∊ # Enlist to flatten
Pip, 8 bytes
FI^zNLCa
Explanation
FI^zNLCa
z Lowercase alphabet
^ Split into a list of characters
N For each character, count number of occurrences in
LCa First command-line arg, lowercased
FI Filter (removing zeros)
The resulting list of numbers is concatenated together and autoprinted
Vyxal, 44 bitsv2, 5.5 bytes
Ǎ⇩sĠ@ṅ
Explained
Ǎ⇩sĊvtṅ
Ǎ # keep only letters of the alphabet
⇩ # and convert to lowercase
sĊ # sort that and get the counts of each letter - this returns [[letter, count of letter] for each letter
vtṅ # join the counts of letters on ""
Thunno 2 J, 6 bytes
LỊDḳ€c
Explanation
LỊDḳ€c # Implicit input
L # Lowercase the input
Ị # Only keep alphabetic characters
D # Duplicate this string
ḳ # Sort and uniquify it
€c # Count of each character
# Implicit output
K (ngn/k), 23 bytes
{,/$#'=x@<x:("a{"')__x}
_xlowercase the input("a{"')_drop all non-letter charactersx@<x:sort the characters#'=build a dictionary mapping the distinct characters to the number of times they appear,/$convert the counts to strings, then join them (and implicitly return)
Julia 1.7, 47 bytes
!x=join((c=count.('a':'z',lowercase(x)))[c.>0])Julia 1.0, 49 bytes
r='a':'z'
!x=join((c=@.sum(in((r-32)r),x))[c.>0])
PHP5.1 (68 chars)
Given $argv[1] as a command line argument, it's using 2 error control operator to silence warning :
foreach(range(@A,@Z)as$a)str_ireplace($a,1,$argv[1],$n)+$n&&print$n;
Try it Online - 63 chars
Python 3.8, 72 bytes:
lambda x:'%.*s'*26%(*(x.lower().count(chr(a//2+97))for a in range(52)),)
Started with another Python 3 solution and ported the string truncation from this Python 2 solution.
Used '%.*s' to convert a number to a string, and truncate it. By passing in the character count twice, it will either produce an empty string or the count as a string.
'%.*s % (0,0)' -> ''
'%.*s % (1,1)' -> '1'
'%.*s % (27,27)' -> '27'
This string formatting needs a tuple, so to produce a doubled up tuple ((10, 20, 30) -> (10, 10, 20, 20, 30, 30)) I doubled the range of numbers and then mapped them back down to the original values.
(97, 97, 98, 98, ..., 122, 123) == (a//2 for a in range(97*2, 123*2))
(a//2 for a in range(97*2, 123*2)) == (a//2 for a in range(194, 246))
Then make the range start from 0 to save some characters
(a//2 for a in range(194,246)) == (a//2+97 for a in range(0,52))
(a//2+97 for a in range(52)) == (a//2+97 for a in range(0,52))
Python 3.8, 76 bytes:
lambda x:''.join(str(i)for a in range(97,123)if(i:=x.lower().count(chr(a))))
Python3, 72 70 67 87 bytes
lambda x:''.join(map(str,map((x:=x.lower()).count,sorted(filter(str.isalpha,set(x))))))
C, 137, 124, 90, 88 bytes
Thank you @AnttiP and @tsh for suggestions!
s[99];main(c){while(c-10)s[(c=getchar())&~32]++;for(c=64;c-90;)s[++c]&&printf("%d",s[c]);}
less golfed version:
s[99];
int main(c){
while(c-10)
s[(c=getchar())&~32]++;
for(c=64;c-90;)
s[++c]&&printf("%d",s[c]);
}
Lua, 94 91 84 bytes
for i=65,90 do _,c=(...):upper():gsub(string.char(i),"")io.write(c~=0 and c or"")end
bash, 64 44 bytes
Original Solution (64 Bytes)
Fairly simple tr-based solution - bash probably isn't a good way to make a competitive answer, but I had fun doing it!
tr [A-Z] [a-z]|tr -dc [a-z]|grep -o .|sort|uniq -c|tr -dc [0-9]
Depending on how you want to count characters, it could be more than 64 when including the input to this. A very simple case would be:
echo my-input-string|tr [A-Z] [a-z]|tr -dc [a-z]|grep -o .|sort|uniq -c|tr -dc [0-9]
which really only adds six characters at best and eight if you have to single-quote the input string.
Explanation:
tr [A-Z] [a-z] # Convert all capitals to lowercase in the input stream
tr -dc [a-z] # Delete everything that isn't a lowercase letter
grep -o . # Output every character on its own line
sort | uniq -c # Get a two-column output of all unique characters and their frequencies
tr -dc [0-9] # Delete everything that isn't a digit
44 Byte Solution (by @Digital Trauma)
grep -io [a-z]|sort -i|uniq -ci|tr -dc [0-9]
Among other improvements, this bash solution utilizes some case-insensitive options for utilities such as sort and uniq.
Here's @Digital Trauma's Try It Online
Haskell, 120 84 73 bytes
f x=do(v,u)<-zip['a'..'z']['A'..];1:r<-[[1|k<-x,v==k||u==k]];show$sum$1:r
-36 bytes thanks to Unrelated String
-11 bytes thanks to Wheat Wizard
Husk, 11 9 8 bytes
Edit: -2 bytes but +1 (bug fix) for a net -1 byte, all thanks to Razetime
ṁosLk_f√
Digits are in alphabetical order of each letter.
f√ # filter for only letters,
k_ # and group letters by lowercase value;
ṁo # now map to each group & combine the results:
L # get the length
s # and convert to a string
PowerShell, 56 50 bytes
%{-join($_|% T*y|% *g|sort|group|? N* -m \w|% C*)}
Input comes from the pipeline.
Try it in a PS console:
$strings = 'acfzzA', 'Hello World!', '---!&*#$', '---!&*#$a', 'aaaaaaaaaaaaaaaaaaaaaaaaaaad', 'aaaaaaaaaad', 'cccbba', 'abbccc'
$result = $strings |
%{-join($_|% T*y|% *g|sort|group|? N* -m \w|% C*)}
1..($strings.Length-1)|%{"'$($strings[$_])' --> '$($result[$_])'"}
-5 by rearranging the first version %{-join($_|% T*y|% *g|?{$_-match'\w'}|sort|group|% C*t)}; moving the "match" filter after the "group" allows the use of the "<Property> <Operator> <Value>" syntax of Where-Object instead of using a FilterScript.
-1 by removing the unnecessary "t" from "% C*t"
Explanation
%{...} "%" is an alias for the cmdlet "ForEach-Object", which accepts input from the pipeline and processes each incoming object inside the ScriptBlock {...}
-join(...) Unary operator which will join the all the character counts returned inside the expression
% T*y takes the input string and calls its method "ToCharArray()", turning the string into an array of single characters.
% *g takes the array of characters and turns them back to single-character strings by invoking ToString() (the only method matching "*g"), because Group-Object is case sensitive for characters, but not for strings.
sort is an alias for Sort-Object, which will sort the characters.
group is an alias for Group-Object, which will group the characters, and return objects with a Count property for each character; returns GroupInfo objects.
? N* -m \w "?" is an alias for "Where-Object", the rest expands to "-Property 'Name' -match '\w'" - this lets only objects pass where the Name property (which contains the grouped character) consists only of word (\w) characters. PS allows for partial named parameters, so -m will be identified as -match.
% C* gets the property "Count" (the only one starting with C) of the GroupInfo objects.
All the counts will now be collected and joined to a single string; output is implicit.
Ungolfed
ForEach-Object -Process {
-join ( # Will join the counts of all characters produced inside the brackets into a single string
$_ | # Input string
ForEach-Object -MemberName ToCharArray | # input string to single chars
ForEach-Object -MemberName ToString | # input chars to single-char strings
Sort-Object |
Group-Object | # group same characters
Where-Object -Property 'Name' -match '\w' | # let only word characters pass ("Name" contains the string/character used to group)
ForEach-Object -MemberName Count # get only the count of the grouped objects
)
}
Wolfram Language (Mathematica), 54 52 bytes
""&@@@Array[ToString/@Counts@LetterNumber@#,26]<>""&
LetterNumber@# a->1,...,z->26, others->0
Counts@ letter counts
Array[ ,26] for a,...,z
""&@@@ (don't include missing letters)
ToString/@ <>"" concatenate
JavaScript (ES6), 63 bytes
Expects an array of characters.
a=>a.map(c=>o[i=parseInt(c,36)]=-~o[i],o=[])|o.slice(10).join``
Commented
a => // a[] = input array
a.map(c => // for each character c in a[]:
o[ // update o[]:
i = // let i be the result of
parseInt(c, 36) // c parsed in base-36
// which gives 0 to 9 for [0-9],
// 10 to 35 for [a-z] and [A-Z]
// and NaN for anything else
// (o[NaN] is not an entry of the array but
// an object property which will be ignored
] = // by join())
-~o[i], // increment it / set it to 1 if it's undefined
o = [] // initialize o[] to an empty array
) | // end of map()
o.slice(10) // ignore the first 10 entries
.join`` // join the remaining ones; undefined values are
// coerced to empty strings
T-SQL, 168 bytes
SELECT STRING_AGG(c,'')WITHIN GROUP(ORDER BY
x)FROM(SELECT x,sum(1)c
FROM(SELECT substring(@,number,1)x FROM spt_values WHERE'P'=type)x
GROUP BY x)x WHERE x like'[a-z]'
This will work for input fewer than 2048 characters. The output is ordered according to the position of the letter in the alphabet
Java 8, 121 118 bytes
s->{var C=new int[91];s.chars().filter(c->(c&95)%91>64).forEach(c->C[c&95]++);for(int c:C)if(c>0)System.out.print(c);}
Input as a Stream of character codepoints. Assumes the input only contains printable ASCII.
Explanation:
s->{ // Method with IntStream parameter and no return-type
var C=new int[91]; // Counters-array, starting all at 0
s.filter(c->(c&95)%91>64) // Filter the input to only keep letters
.forEach(c-> // Loop over each letter-codepoint:
C[c&95 // Convert the codepoint of the char to uppercase
]++); // And increase the counter of that letter by 1
for(int c:C) // Loop over the counts:
if(c>0) // If the count is not 0:
System.out.print(c);} // Print that count
Retina 0.8.2, 24 bytes
T`Llp`LL_
O`.
(.)\1*
$.&
Try it online! Link includes test cases. Explanation:
T`Llp`LL_
Uppercase all letters and delete all other printable ASCII.
O`.
Sort the letters together.
(.)\1*
$.&
Get the lengths of all the runs.
R, 75 72 bytes
function(s,x=tabulate((y=utf8ToInt(s))%%32*(y>64),26))cat(x[!!x],sep="")
Prints the result. For invalid input, prints nothing.
-3 bytes thanks to Dominic van Essen.
Test harness taken from pajonk's answer.
R, 78 69 bytes
Or R>=4.1, 62 bytes by replacing the word function with \.
Edit: -9 bytes inspired by @Giuseppe's answer.
function(s)cat(table(utf8ToInt(gsub("[^a-z]","",tolower(s)))),sep="")
Prints the resulting number like in @Giuseppe's answer.
BQN, 30 28 bytesSBCS
{∾•Fmt¨×⊸/+˝(⥊𝕩-⌜"aA")=⌜↕26}
↕26 Range from 0 to 25.
⥊𝕩-⌜"aA" Differences between each of the characters in the input and a or A.
=⌜ Equality table between those two vectors.
+˝ Sum the columns.
×⊸/ Keep the values with sign 1 (or: remove the zeros)
∾•Fmt¨ Convert each value to a string and join.
A slightly different approach using Bins Down at 29 bytes:
{∾•Fmt¨×⊸/»1↓/⁼27↕⊸⍋⥊𝕩-⌜"aA"}
APL+WIN, 48 44 bytes
Prompts for string
10⊥((+/(48+m)∘.=n)++/(m←17+⍳26)∘.=n←⎕av⍳⎕)~0
Charcoal, 10 bytes
⭆α⪫↨№↥θιχω
Try it online! Link is to verbose version of code. Explanation:
α Predefined variable uppercase alphabet
⭆ Map over letters and join
№ Count of
ι Current letter in
↥ Uppercased
θ Input string
↨ χ Convert to base 10
⪫ ω Join digits together
Charcoal's arbitrary base conversion returns an empty list for an input of zero, which is the easiest way to map zero to an empty string.
JavaScript (Node.js), 64 bytes
s=>s.sort().join(o='').replace(/([a-z])\1*/gi,c=>o+=c.length)&&o
Based off Arnauld's answer. Takes input as a character array.
Sort, join, match runs of one character and append that to o, and yield that at the end.
PHP, 66 bytes
<?=join(count_chars(preg_replace('~\W~','',strtolower($argn)),1));
A rarely useful builtin function, but it turns out satisfying when it does
Factor + spelling, 56 bytes
[ >lower ALPHABET counts values [ present ] map-concat ]
The counts word postdates Factor build 1525, the one TIO uses, so here's a screenshot of running the above code in build 2101's listener:
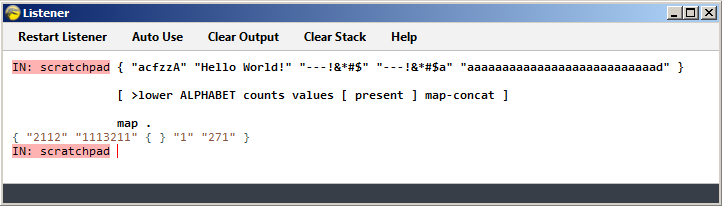
Explanation
! "acfzzA"
>lower ! "acfzza"
ALPHABET ! "acfzza" "abcdefghijklmnopqrstuvwxyz"
counts ! { { 97 2 } { 99 1 } { 102 1 } { 122 2 } }
values ! { 2 1 1 2 }
[ present ] map-concat ! "2112"
Jelly, 8 bytes
ŒufØAṢŒɠ
Jelly, 8 bytes
ŒuċⱮØA¹Ƈ
Both as full programs, taking advantage of Jelly's automatic smash-printing behavior.