| Bytes | Lang | Time | Link |
|---|---|---|---|
| 019 | Pip P | 210709T043812Z | DLosc |
| 009 | APLDyalog Unicode | 240214T092519Z | Mukundan |
| 005 | flax | 240218T040014Z | zoomlogo |
| nan | Python 3 with numpy | 210706T161900Z | m90 |
| 062 | Pari/GP | 211112T070107Z | alephalp |
| 018 | BQN | 211114T134933Z | frasiyav |
| 066 | Python 3 + numpy | 211113T230151Z | loopy wa |
| 014 | Japt | 210706T170502Z | Shaggy |
| 048 | ARM A32 machine code | 210729T160314Z | m90 |
| 042 | Julia 1.0 | 210713T132401Z | MarcMush |
| 084 | Python 3.8 + numpy | 210708T035454Z | Ryan McC |
| 032 | Wolfram Language Mathematica | 210706T034333Z | att |
| 072 | JavaScript ES6 | 210707T023538Z | tsh |
| 005 | Jelly | 210706T194334Z | lynn |
| 009 | Jelly | 210706T055921Z | hyperneu |
| 061 | Haskell | 210706T191724Z | lynn |
| 009 | Jelly | 210706T000935Z | Jonathan |
| 049 | R | 210706T094021Z | Dominic |
| 055 | R | 210706T084403Z | Kirill L |
| 064 | Ruby | 210706T113849Z | G B |
| 113 | Python 3 + numpy | 210706T132015Z | ovs |
| 088 | Haskell | 210706T121646Z | flawr |
| 2119 | J | 210706T091615Z | xash |
| 067 | Octave/MATLAB | 210706T115256Z | flawr |
| 018 | Charcoal | 210706T004922Z | Neil |
| 079 | JavaScript ES6 | 210705T235200Z | Arnauld |
| 081 | Python 2 | 210706T083953Z | tsh |
| 033 | J | 210706T043344Z | Jonah |
Pip -P, 19 bytes
$+{TBg}FB4*^21MC Ea
Explanation
Inspired by Neil's comment about interleaving bit patterns, we can simply map the x and y coordinates to the right value (example x = 5, y = 9):
5 101 0 1 0 1
9 1001 1 0 0 1 10010011 147
We're not going to use Pip's WV operator to do the interleaving, since it works left-to-right and doesn't fill in with zeros; instead, observe that an equivalent formula is to convert to base 4, multiply the y value by 2, and sum:
5 101 1 0 1 10001 (2) = 101 (4) = 17 (10)
9 1001 1 0 0 1 10000010 (2) = 2002 (4) = 130 (10) 147
So:
$+{TBg}FB4*^21MC Ea
Ea 2^input
MC Map this function to a grid of coordinate pairs of that size:
{TBg} Convert each coordinate to binary
FB4 Treat as base 4 and convert back to decimal
* Multiply by
^21 list containing 2 and 1
(multiplying the row by 2 and the column by 1)
$+ Sum
The -P flag gives the matrix a readable output format; -p or -S would also work.
APL(Dyalog Unicode), 10 9 bytes SBCS
⊢⌸2<,⍳⎕⍴4
⊢⌸2<,⍳⎕⍴4
⎕⍴4 # 4 repeated n times
⍳ # create a n-dimensional array with shape [4, 4, ..., 4] where value equals index
, # flatten
2< # greater than 2 (vectorized)
⊢⌸ # group by value and return indices for each group
💎
Created with the help of Luminespire.
flax, 5 bytes
G>1ṗ4
Port of @lynn's Jelly answer.
Since the lastest version isn't on ATO, here is an image of the program running (in the REPL).
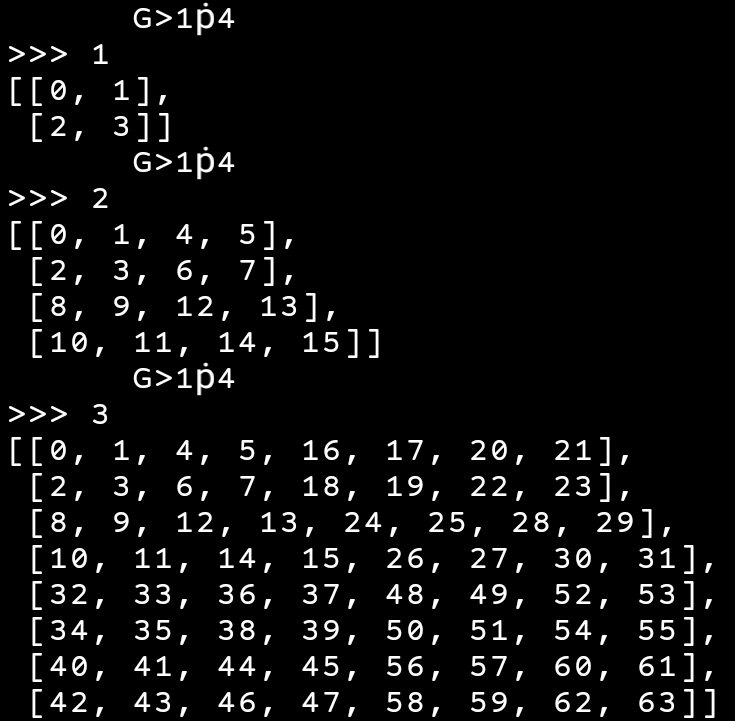
Explanation
It is same as the jelly answer.
G>1ṗ4
G " group by values
>1 " greater than 1
ṗ4 " nth cartesian power of [0,1,2,3]
Python 3 with numpy, 91 87 74 70 69 67 bytes
lambda n:c_[s:=(c_[:1<<n]&(b:=1<<r_[:n]))@b]*2+s from numpy import*
c_[:1<<n] produces an array of the numbers 0 (inclusive) to 2n (exclusive), vertically. r_[:n] produces 0 (inc.) to n (exc.), horizontally, and the left shift makes the corresponding powers of 2, saved in b. The bitwise AND, with broadcasting, produces a table of values, splitting the numbers into their constituent bits. The matrix product (@) is equivalent to taking the dot product of each broken-down number with b; this squares each nonzero bit, changing powers of 2 into powers of 4, and adds them back up, producing a horizontal sequence 0, 1, 4, 5, 16, 17, 20, 21, ..., which is saved in s. c_ makes a vertical version of that sequence, which is doubled and added to the original sequence, which (by broadcasting) produces a table of sums, which is the required result.
Previously:
from numpy import*
lambda n:(s:=vander([4],8)@unpackbits(mat(r_[:1<<n],uint8),0))+s.T*2
r_[:1<<n] produces 0 (inc.) to 2n (exc.). It is passed to mat ("Interpret the input as a matrix"), which in particular makes it 2-dimensional, while also changing its type to uint8, which is necessary for the next function unpackbits, which breaks the numbers down into their binary representations, across the added dimension. vander([4],8) produces an array of powers of 4, which in the @ (matrix multiplication) gets dot-producted with each binary vector, producing a similar s (transposed differently), and the rest is similar.
BQN, 18 bytes
{(⍉∾⍉+·≠⥊)⍟2⍟𝕩≍≍0}
How it works:
{(⍉∾⍉+·≠⥊)⍟2⍟𝕩≍≍0}
≍≍0 # Starting from a rank 2 array containing 0
⍟𝕩 # apply the preceding function 𝕩 times where 𝕩 is the input
⍉∾ # The transposed array joined to
⍉+·≠⥊ # the transposed array plus the number of elements
( )⍟2 # applied twice
Python 3 + numpy, 66 bytes
from numpy import*
f=lambda m:c_[m and(f(m-.5),4**m//2+f(m-.5))].T
Mostly straight-forward recursion. Splits the 2x2 update into 2 1x2 updates with intermittent transpose.
Python 3 + numpy, 68 bytes
from numpy import*
f=lambda m:m and log2(kron(4**f(m-.5),c_[1:3])).T
Just noticed that @Kirill L.'s R answer uses the exact same idea.
By componentwise exponentiating adding in the original problem becomes multiplying so friend Kronecker can do the heavy lifting for us.
Downside: will get numerically inaccurate pretty fast.
ARM A32 machine code, 48 bytes
e3a0c000 e1a0215c e1b03152 112fff1e
e02c3112 ec432b10 f2800e00 f2810590
f2211110 f480180d e28cc001 eafffff4
Following the AAPCS, this takes in r0 the address of an array of arrays of 32-bit integers to be filled with the result, and takes n in r1.
Assembly:
.section .text
.code 32
.global zm
zm:
mov r12, #0 @ Initialise counter to 0
loop:
asr r2, r12, r1 @ Shift counter right by n, to obtain the top half
asrs r3, r2, r1 @ Shift that right by n again, to check for ending (2^2n)
bxne lr @ If so, return
eor r3, r12, r2, lsl r1 @ Exclusive-or cancels out the top half, to obtain the bottom half
vmov d0, r2, r3 @ Place the two halves into a 64-bit SIMD&FP register
vmull.p8 q0, d0, d0 @ Multiply by itself as polynomials over GF(2);
@ because this is a ring of characteristic 2, (a+b)^2 = a^2 + b^2 holds,
@ thus squaring doubles each exponent in the polynomial, spreading out the bits.
@ Results go into Q0, which is also D0 and D1.
vshl.i64 d0, #1 @ Shift the squared top half left by 1 ...
vorr d1, d0 @ ... and combine by OR with the bottom half
vst1.32 {d1[0]}, [r0]! @ Place the result into memory, advancing the pointer
add r12, #1 @ Increment the counter
b loop @ Repeat
(This should work on v7 or later from what I can tell, but in the testing setup I'm using (similar to here), it gives 'instruction not supported' errors on versions lower than v8.4, which doesn't seem right.)
Python 3.8 + numpy, 85 84 bytes
import numpy;z=lambda n:n and numpy.block([[m:=z(n-1),m+(k:=4**~-n)],[m+2*k,m+3*k]])
Not as clever as some of the other python ones, but shorter than the other python 3 ones. Also 0 returns a scalar instead of a list, not sure if that's allowed.
Wolfram Language (Mathematica), 49 32 bytes
PositionIndex@Tuples[0|0|1|1,#]&
Returns an Association where the values correspond with rows of the matrix (associations are ordered). For a traditional list-of-lists output, prepend List@@ (+6 bytes).
Port of Lynn's Jelly solution.
Older solution:
Outer[#+##&,t=#~FromDigits~4&/@{0,1}~Tuples~#,t]&
JavaScript (ES6), 72 bytes
f=(n,a=[0])=>n?f(n-1,a.flatMap(x=>[x*=4,x+1])):a.map(y=>a.map(x=>x+2*y))
Use the idea from Lynn's Haskell answer which saves many bytes on generating the list for iterate. Using base conversion as what my Python answer do will make it much longer (79 bytes).
Jelly, 5 bytes
4ṗ>2Ġ
Try it online! Neil saved a byte. Thanks!
4ṗ n-th Cartesian power of [1,2,3,4]
>2 Replace 1,2,3,4 with 0,0,1,1
Ġ Group indices by values
For n=2, 4ṗ>2 generates a list of 16 pairs:
1: [0, 0]
2: [0, 0]
3: [0, 1]
4: [0, 1]
5: [0, 0]
6: [0, 0]
7: [0, 1]
8: [0, 1]
9: [1, 0]
10: [1, 0]
11: [1, 1]
12: [1, 1]
13: [1, 0]
14: [1, 0]
15: [1, 1]
16: [1, 1]
Then Ġ turns this into a list of lists:
- all indices where the value is
0 0: namely[ 1, 2, 5, 6], - all indices where the value is
0 1: namely[ 3, 4, 7, 8], - all indices where the value is
1 0: namely[ 9, 10, 13, 14], - all indices where the value is
1 1: namely[11, 12, 15, 16].
The result is a Z-matrix.
Why does this work?
Suppose we bump the input up to \$n=3\$. How does our output compare to that for \$n=2\$?
Let's call 4ṗ>2 a function \$f\$. The list of 16 pairs above is the output of \$f(2)\$. By definition of the Cartesian power, \$f(3) = [0,0,1,1] \times f(2)\$ =
[[0] + x for x in f(2)] (indices 1..16)
+ [[0] + x for x in f(2)] (indices 17..32)
+ [[1] + x for x in f(2)] (indices 33..48)
+ [[1] + x for x in f(2)] (indices 49..64)
There are now 8 values for Ġ to group the indices by, ranging from [0,0,0] to [1,1,1].
All indices in 1..32 end up in the first four groups, and because we repeated [[0] + x for x in f(2)] twice, a[i+16] is always in the same group as a[i]. Then, all indices in 33..64 end up in the last four groups, and their relative order is the same as the first half of the list (the only difference is they have 1 instead of 0 in front). Within each quadrant, the order is the same as it was in f(2). So we get:
[0, 0, 0]: 1 2 5 6 17 18 21 22
[0, 0, 1]: 3 4 7 8 19 20 23 24
[0, 1, 0]: 9 10 13 14 25 26 29 30
[0, 1, 1]: 11 12 15 16 27 28 31 32
[1, 0, 0]: 33 34 37 38 49 50 53 54
[1, 0, 1]: 35 36 39 40 51 52 55 56
[1, 1, 0]: 41 42 45 46 57 58 61 62
[1, 1, 1]: 43 44 47 48 59 60 63 64
Jelly, 9 bytes
4*Ḷb4:2ḄĠ
Pretty much a port of Neil's Charcoal answer, so go upvote them too.
4*Ḷb4:2ḄĠ Main Link; take x
4* 4 ** x
Ḷ [0, 1, 2, ..., 4 ** x - 1]
b4 Convert to base 4
:2 Floor-divide by 2
Ḅ Convert from binary
Ġ Group the indices by their corresponding values
This answer can be ported directly into yuno.
yuno, 9 bytes
4*ʀb4:2ɮG
This approach is probably what Bubbler's 6-byter is going for, but a) I need to find how to get 0,0,1,1 in 3 bytes, and b) I need to figure out how to make the format valid without the s2*$ being that long:
Jelly, 11 bytes
Ø.x2¤ṗỤs2*$
Jelly, 16 bytes
,Uz0$FU
2*ḶBçþ`Ḅ
Haskell, 61 bytes
f n|r<-iterate(>>= \x->[4*x,4*x+1])[0]!!n=[[x+2*y|x<-r]|y<-r]
Same idea as tsh's Python, but the list r (e.g. [0,1,4,5,16,17,20,21]) is created in a Haskell-y way.
Jelly, 14 12 9 bytes
9 byter
Ø.ṗḅ4+þḤ$
How?
Makes a table under \$x+2y\$ where both \$x\$ and \$y\$ are a prefix of the Moser–De Bruijn sequence.
Ø.ṗḅ4+þḤ$ - Link: n
Ø. - bits -> [0,1]
ṗ - Cartesian power (n) -> binary representations of [0..2^n-1]
ḅ4 - convert from base four -> first 2^n terms of the Moser–De Bruijn sequence
$ - last two links as a monad, f(S):
Ḥ - double -> D=[2x for x in S]
þ - (s in S) table with (d in D):
+ - (s) add (d)
(Still no clue for the 6 byte code though!)
12 Byter
-1 thanks to caird coinheringaahing (we can use 1-based values)
Ġ;"FL+ƊZƊ⁸¡⁺
A monadic Link that accepts a non-negative integer and yields the matrix (using the 1-based values option).
Try it online! (Footer formats as a Python list for clarity.)
How?
Starts with [[1]] and repeatedly applies a function that creates the required new entries to the right (and then below, via the transposed matrix) by adding the number of current elements to each element.
Ġ;"FL+ƊZƊ⁸¡⁺ - Link: non-negative integer, n
Ġ - group indices (of implicit [n]) by value -> [[1]] (our initial M)
¡ - repeat...
⁸ - ...number of times: chain's left argument -> n
Ɗ - ...what: last three links as a monad, f(M):
Ɗ - last three links as a monad, g(M):
F - flatten
L - length
+ - add to elements of M
" - zip (rows of M) with (rows of that) and apply:
; - concatenation
Z - transpose
⁺ - repeat last link (i.e. repeat f() n more times)
R, 57 52 49 bytes
Edit: -8 bytes by changing to iterative approach with scan() for input (instead of recursive function)
for(i in seq(l=2*scan())-1)F=t(cbind(F,F+2^i));+F
Explanation
Recursive function that Each loop icreates two side-by-side copies of the columns of a matrix, adding the maximum value of the first +1 2^i to the second copy, and then transposes it all.
This creates the top left & top right copies of the last matrix (F), transposed: so, every second loop creates a full 'Z' of four copies of the last matrix, untransposed.
So we need to loop twice the value of n times.
R, 65 63 59 57 55 bytes
for(i in seq(l=scan()))T=T^4%x%2^rbind(0:1,2:3);log2(T)
Relies on the observation that each next iteration N relates to the previous iteration P by Kronecker product-like operation with the matrix M for n=1, but using summation instead of multiplication:
N = kronecker(4*P, M, FUN = "+")
Here, we transform the values with powers and logarithms in order to make use of the actual Kronecker product function, which is conveniently abbreviated as %x% operator.
Ruby, 90... 64 bytes
->n{(k=0...2**n).map{|y|k.map{|x|k.sum{|z|[x,y][z%2][z/2]<<z}}}}
Quick explanation:
Every number can be expressed by interleaving the binary digits of the number of row and column.
Python 3 + numpy, 113 bytes
A very literal (and long) implementation of the spec.
lambda n:sum(tile(R(R(c_[:2,2:4].T,1<<i,0),1<<i,1)<<2*i,(1<<n+~i,)*2)for i in r_[:n])
from numpy import*
R=repeat
Haskell, 88 bytes
f 0=[[1]]
f n=let(#)=zipWith(++);m=n-1;a=f m;[b,c,d]=map(map(+4^m))<$>[a,b,c]in a#b++c#d
J, 21 19 bytes
Found Bubbler's solution. :-)
2(*+/])4#.2#:@i.@^]
The first row is A000695, the first column is the same but times two. In the comments Marc LeBrun notes that this is rebasing n from base 2 into base 4. So that's helpful with J:
2(*+/])4#.2#:@i.@^]
2 i.@^] 0 1 … 2^n
#: digits in base 2
0 0 0
0 0 1
…
1 1 0
1 1 1
4#. interpret as digits in base 4
0 1 4 5 16 17 20 21
2(*+/]) addition table of list*2 with list
Octave/MATLAB, 67 bytes
function x=f(n);x=1;for i=1:n;k=4^i/4;x=[x,k+x;2*k+x,3*k+x];end;end
Charcoal, 27 23 18 bytes
≔EX²N↨⁴↨ι²υIE⊗υ⁺ιυ
Try it online! Link is to verbose version of code. Explanation: Now a port of @tsh's Python answer.
≔EX²N↨⁴↨ι²υ
Map the numbers up to 2ⁿ by converting them to base 2 and then interpreting the result as base 4.
IE⊗υ⁺ιυ
Vectorised add the doubled array to itself as a matrix.
Previous 27 23 byte answer uses a different approach that is interesting in its own right because some golfing languages have built-ins for things like group index by value or sort array by key.
≔EX⁴N↨²÷↨ι⁴¦²υIE⊕⌈υ⌕Aυι
Try it online! Link is to verbose version of code. Explanation:
≔EX⁴N↨²÷↨ι⁴¦²υ
For each element in the final diagram, convert it to base 4, halve the digits, then convert from base 2. This gives the row number for that element.
IE⊕⌈υ⌕Aυι
For each row list the elements assigned to that row.
JavaScript (ES6), 89 86 79 bytes
Saved 7 bytes thanks to @tsh
n=>[...Array(1<<n)].map((_,y,a)=>a.map(g=(k=1,x)=>k>>n?0:x&k|(y&k|g(k*2,x))*2))
Python 2, 81 bytes
R=[int(bin(x)[2:],4)for x in range(2**input())]
for y in R:print[x+y*2for x in R]
J, 33 bytes
,~@^~&2$4(/:[:<.@-:4#.inv])@i.@^]
The true insight of this idea is due to Neil's excellent answer.
I'll mention a couple of other insights I had which didn't help with bytes but might be useful to others:
- The deltas along each row follow a repeating pattern whose unique elements are http://oeis.org/A007583: 1, 3, 11, 43, 171...
- Similarly the deltas going down each column follow http://oeis.org/A047849: 1, 2, 6, 22, 86, 342...
how
4...@i.@^]Produces0, 1, ... 4^n, where n is the input./:[:<.@-:4#.inv]Sort those according to row number, which we get by converting to base 4, halving, and flooring.,~@^~&2$Now shape that into a square matrix of side length2^n.