| Bytes | Lang | Time | Link |
|---|---|---|---|
| 081 | AWK | 250821T153509Z | xrs |
| 042 | Arturo | 230815T032730Z | chunes |
| 010 | Thunno 2 cJ | 230813T110009Z | The Thon |
| 010 | Vyxal s | 220705T231807Z | naffetS |
| 123 | Rust | 220711T085537Z | mousetai |
| 015 | Jelly | 220706T004021Z | naffetS |
| 020 | K ngn/k | 210206T145621Z | coltim |
| 015 | Husk | 210210T004820Z | Leo |
| 020 | APLDyalog Unicode | 210207T075623Z | Razetime |
| 031 | k9 L2021.01.29 | 210204T063224Z | chrispsn |
| 032 | APL Dyalog Unicode | 210203T142924Z | ovs |
| 111 | PHP | 210202T053520Z | emanresu |
| 035 | Husk | 210127T143458Z | Razetime |
| 090 | Java JDK | 210126T193618Z | user |
| 089 | brainfuck | 210121T085137Z | RezNesX |
| 024 | ARM Thumb2 machine code | 210125T044029Z | EasyasPi |
| 057 | PowerShell | 210121T201824Z | Julian |
| 016 | Stax | 210118T111153Z | Razetime |
| 081 | Python 3 | 210118T114554Z | nTerior |
| 169 | Elixir | 210120T102903Z | user9915 |
| 225 | Oracle SQL | 210121T012502Z | MT0 |
| 011 | x8616 machine code | 210119T162250Z | 640KB |
| 046 | C gcc | 210118T215631Z | anotherO |
| 134 | SNOBOL4 CSNOBOL4 | 210119T192931Z | Giuseppe |
| 042 | Wolfram Language Mathematica | 210119T033019Z | att |
| 056 | Python 3.10.0a41 | 210118T191011Z | ovs |
| 5947 | convey | 210118T164454Z | xash |
| 009 | Japt | 210118T173336Z | AZTECCO |
| 031 | Perl 5 plF | 210118T171939Z | Xcali |
| 071 | Red | 210118T171725Z | Galen Iv |
| 044 | C gcc | 210118T131949Z | Noodle9 |
| 098 | R | 210118T123759Z | Dominic |
| 044 | Haskell | 210118T143150Z | user |
| 140 | Racket | 210118T143804Z | Galen Iv |
| 037 | Retina 0.8.2 | 210118T125615Z | Neil |
| 010 | 05AB1E | 210118T113003Z | Kevin Cr |
| 035 | JavaScript ES6 | 210118T114528Z | Arnauld |
| 037 | Ruby pl | 210118T110615Z | Dingus |
| 019 | Charcoal | 210118T115333Z | Neil |
AWK, 81 bytes
{split($NF,a,X)
NF--
l=split($0,b,OFS=X)
for(j=1;i++<l;)$i=a[j]~b[i]?a[j++]:"*"}1
Thunno 2 cJ, 10 bytes
Xıxh=?ẋḣ:0
Uses 0 as the filler character.
Explanation
Xıxh=?ẋḣ:0 # Implicit input
X # Put the first input string in x
ı # Map over the second input string:
xh= # Does it equal the first character of x?
? # If it does:
ẋḣ # Remove the first character of x
# (and the current character remains on top)
: # Otherwise:
0 # Push a 0 instead (as a filler)
# Implicit output, joined into a string
Rust, 123 bytes
|m:&str,v:&str|{m.chars().fold(v.chars().peekable(),|mut a,c|{print!("{}",if a.peek()==Some(&c){a.next();c}else{'*'});a});}
Adapted from my answer to "Backronymiser឵឵"
Jelly, 15 bytes
⁸©µ⁹µ®1ị®Ḣ¤0=?)
Absolutely TERRIBLE.
⁸©µ⁹µ®1ị®Ḣ¤0=?) - Dyadic link f(k, s) where k is the "word" and s is the "sentence"
⁸© - Copy k to the register
µ - Begin a new monadic chain f(s) to prevent k from being implicitly printed
⁹µ ) - Map over s:
®1ị - Get the first character of the register
=? - Is it equal to the current character in s?
®Ḣ¤ - If so, then remove the first character from the register and push it
0 - Else, just use 0
K (ngn/k), 24 20 bytes
-4 bytes from using " " as the blank-out character
{y@<>y{y_x,y~:*x}/x}
Shoutout to @chrispsn and @ngn for helping to golf the above!
y{...}/xset up a reduction seeded withy(the characters to search for), run over the characters inx(the full string). confusingly, within the function itself,xandyare flipped. this ends up returning a boolean array with1s in the positions containing the desired matches and0s everywhere elsey~:*xcompare the first character to search for (*x) to the current character being iterated over (y), updatingywith the result of0or1. note that as soon as we have matched all the search characters, no more matches will be identified (since a character will never~(match) a0or1)x,append this result to the list of characters to search for (essentially overloading the reduction to end up returning the desired output)y_if there was a match, drop the first character (if there wasn't a match, this is a no-op). this allows us to search for the next search character in the next iteration of the reductiony@<>do an APL-style expand with y and the generated boolean array (this fills with" "s)
An alternative blank-out value can be implemented by inserting e.g. "*"^y at the beginning of the function.
Husk, 15 bytes
«S↓₁λ?←¹'*₁
€↑1
It took a while, but here's a short(ish) working solution.
Explanation
The second line is a helper function, it shortens the program because we would have to call it twice, and it would need brackets both times if it was inlined.
€↑1 Input: a string and a character, Output: 0 or 1
↑1 Get the first 1 characters of the string
€ Return the index of the character in this substring (0 if missing)
This function tells us if the given character is the same as the character at the beginning of the string. There would be a simpler way of doing this (=←), but ← on an empty string returns a space character, and this would mess up things.
The rest of the program is a call to mapacL («), which scans a list using two functions, one to update the internal accumulator and the other one to generate the output. In practice, we will loop through the sentence character by character, our accumulator will start as the target word, and at each step we will update the accumulator using the current input character and the first function (S↓₁), and we will generate one output character using the accumulator, the current input character, and the second function (λ?←¹'*₁).
Updating the accumulator means discarding the first character from it if it matches the current input character:
S↓₁ Input: accumulator and current character, Output: new accumulator
₁ Call helper function (1 if character matches, 0 if it does not)
↓ Drop that many characters
S from the first input (accumulator)
Generating output characters means returning the character itself if it matches, and returning '*' if it does not:
λ?←¹'*₁ Input: accumulator and current character, Output: character or '*'
₁ Call helper function (1 if character matches, 0 if it does not)
? If 1:
← get the first character from
λ ¹ the accumulator
Else:
'* Return '*'
APL(Dyalog Unicode), 27 25 20 bytes SBCS
({w↓⍨←⍵=⊃w,0}¨⍞)\w←⍞
A tradfn submission which takes the two values from STDIN.
Inspired by coltim's K answer.
Uses space as the blotting character.
-2 and -5 bytes from Adám!
The expand operation \ uses a bitmask to insert spaces between the elements of the input.
1 0 0 1 0 0/'hi' → 'h i '
Explanation
({w↓⍨←⍵=⊃w,0}¨⍞)\w←⍞
w←⍞ store target word in w
\ expand using the following bitmask:
{ }¨⍞ for each character of the source word:
⍵=⊃w,0 is the character equal to the first one in w?
return that
w↓⍨← then drop that many characters from w (0 or 1)
k9 L2021.01.29, 31 bytes
{(y,$0)(-1{*(x<)#y}\(=x)y)?!#x}
(=x)y get indices in sentence for each letter in target
-1{*(x<)#y}\[target indices] get each target letter's first index in the sentence that's greater than the last target index we took (ie always looking ahead)
[first indices]?!#x get position of each sentence index in the 'first target indices' list, defaulting to the list's length if not found
(y,$0)[index list] index into target word with 'blank char' suffix.
EDIT: assuming we want * as fill, we can use coltim's awesome ngn/k answer to get to 24 bytes:
{`c"*"|x*y{y_x,y~:*x}/x}
APL (Dyalog Unicode), 38 32 bytes
-6 bytes by using a space instead of * as a blank out character.
A port of my Python answer. Assumes ⎕IO←0.
{×≢⍵:(⊃x↑⍺),(⍺↓⍨x←⊃=⌿↑⍺⍵)∇1↓⍵⋄⍵}
Commented:
{ ... } ⍝ A dfn taking two arguments:
⍝ - the target word as the left argument ⍺
⍝ - and the sentence as the right argument ⍵
×≢⍵: ⍝ if the length of ⍵ is positive:
↑⍺⍵ ⍝ mix ⍺ and ⍵ into a character matrix, padding the shorter with spaces
=⌿ ⍝ for each row, check if the two characters are equal
⊃ ⍝ take the first result
⍝ this is now ⍺[0] = ⍵[0], but this is 1 if ⍺ is empty and ' ' = ⍵[0]
x← ⍝ and store it in x
⍺↓⍨x ⍝ drop x (0 or 1) characters from ⍺
∇ ⍝ and call the dfn recursively with this value
1↓⍵ ⍝ and with ⍵ without he first character
( ), ⍝ prepend to the result of the recursive call
⊃ ⍝ the first character of
x↑⍺ ⍝ take the first x characters of ⍺
⍝ if one of these strings is empty, ⊃ and ↑ use a space as a default value
⋄⍵ ⍝ if the length of ⍵ is not positive, return ⍵
PHP, 111 bytes
$i=0;$c='';foreach(str_split($argv[2])as$k){if($k==str_split($argv[1])[$i]){$c.=$k;$i++;}else{$c.='*';}}echo$c;
Explanation:
$i=0;$c=''; //init vars (index, tracker)
foreach(str_split($argv[2])as$k){ //for each char in string 2
if($k==str_split($argv[1])[$i]){ // if char in string 2 matches char searched for
$c.=$k;$i++; //add char to tracker + increment index
}else{$c.='*';} // else add * to tracker
}echo$c; //output tracker
Input as args - arg 1 is string to find, arg 2 is string to look in.
Husk, 35 bytes
ṁ←tU¡λ?:;←!2¹mtt¹ė" "t!2¹!3¹Ë←t)ė"
A very clunky infinite list based solution, but so far the only one that works correctly, so I decided to post it.
Java (JDK), 91 90 bytes
Saved 1 byte thanks to ceilingcat
s->t->{var r="";for(int a=0,b=0;a<s.length&b<t.length;)r+=s[a++]==t[b]?t[b++]:2;return r;}
Takes input as char[]s, uses an unprintable character (2) to blank letters out (+1 bytes to use a printable character).
brainfuck, 131 106 96 89 bytes
>>,----------[++++++++++>,----------]<[<],>[<[<+>>-<-]->[[-]<.+>]<[<.[-],>+]<[>>+<<-]>>>]
Input is taken as sentence\ntarget where \n is a newline
-25 bytes (thanks to @cairdcoinheringaahing)
ARM Thumb-2 machine code, 24 bytes
Machine code
f811 2b01 7803 4293 bf18 232a f800 3b01
d1f8 2a00 d1f4 4770
Commented assembly:
.syntax unified
.arch armv6t2
.thumb
.globl lobstah
.thumb_func
// C callable.
// void lobstah(char *sentence, const char *target);
// Input:
// sentence (null terminated string): r0
// target (null terminated string): r1
// Output:
// sentence is modified in place
//
// This is nothing but the obvious approach: a linear
// search loop. Sometimes, that's best. ¯\_(ツ)_/¯
lobstah:
.Lnext_target:
// Load next byte from target, increment (wide insn)
ldrb r2, [r1], #1
// Search
.Lsearch_loop:
// Load byte from sentence
ldrb r3, [r0]
// Is it our target?
cmp r3, r2
// If it wasn't, replace with a '*'
it ne
movne r3, #'*'
// Store back and increment (wide insn)
strb r3, [r0], #1
// Loop while we don't have a match
// (the flags were not modified since the cmp)
bne .Lsearch_loop
.Lsearch_loop.end:
// Loop unless we reached the null terminator.
cmp r2, #0
bne .Lnext_target
.Lend:
// Return
bx lr
It is nothing but the obvious approach, a linear search loop. You really can't make anything smaller than that. 🤷♂️
PowerShell, 63 57 bytes
$t,$s=$args
-join($s|%{"*$_"[($c=$_-ceq$t[+$i])];$i+=$c})
-6 bytes thanks to mazzy!
Stax, 24 18 17 16 bytes
ù←⌐0ø\d▀→"ε╞☺Γ|▓
-6 bytes, following Dingus's idea.
-1 byte from recursive. (h= → h)
-1 byte, using \0 as a filler character.
Python 3, 90 80 81 bytes
-10 bytes (thanks to @Danis)
-Fixed error when trying to access first character (thanks for @xnor for reporting)
+1 byte: Fixing return error
def f(t,g,i=0):
l=['*']*len(t)
for c in g:i=t.find(c,i);l[i]=c*(i>=0)
return l
Elixir, 184 169 bytes
defmodule A do
def f x,y do
cond do
x==""->x
q(x)==q(y)->q(y)<>f p(x),p y
1->"*"<>f p(x),y
end
end
def p(x)do
String.slice(x,1..-1)
end
def q(x)do
String.at(x,0)
end
end
Oracle SQL, 225 bytes
Its not a golfing language, but ...
WITH r(s,w,a,b,c,l)AS(SELECT s,w,1,1,'',LENGTH(s) FROM t UNION ALL SELECT s,w,a+1,DECODE(SUBSTR(s,a,1),SUBSTR(w,b,1),b+1,b),c||DECODE(SUBSTR(s,a,1),SUBSTR(w,b,1),SUBSTR(w,b,1),0),l FROM r WHERE a<=l)SELECT c FROM r WHERE a>l
Which assumes a table t with columns s (sentence) and w (word) and uses 0 as the masking character.
A neatly formatted version (which also outputs the sentence and word) is:
WITH r(sentence,word,sentence_pos,word_pos,output,len)AS(
SELECT s,
w,
1,
1,
'',
LENGTH(s)
FROM t
UNION ALL
SELECT sentence,
word,
sentence_pos+1,
DECODE(
SUBSTR(sentence,sentence_pos,1),
SUBSTR(word,word_pos,1),
word_pos+1,
word_pos
),
output||DECODE(
SUBSTR(sentence,sentence_pos,1),
SUBSTR(word,word_pos,1),
SUBSTR(word,word_pos,1),
0
),
len
FROM r
WHERE sentence_pos<=len
)
SELECT sentence,
word,
output
FROM r
WHERE sentence_pos>len
Which, for the sample data:
CREATE TABLE t(s,w) AS
SELECT 'I do not control the speed at which lobsters die', 'code' FROM DUAL UNION ALL
SELECT 'testcase string', 'tas' FROM DUAL UNION ALL
SELECT 'uglhwagp qvyntzmf','ulhwagpqvyntzmf' FROM DUAL UNION ALL
SELECT 'qrkacxx wwfja jsyjdffa vwfgxf','qcfvf' FROM DUAL UNION ALL
SELECT 'z wzsgovhh jopw igcx muxj xmmisxdn t lmb','gcujxlb' FROM DUAL UNION ALL
SELECT 'kxf jgmzejypb ya','e' FROM DUAL UNION ALL
SELECT 'fe oxyk y','ex' FROM DUAL UNION ALL
SELECT 'o wr fmik','owrfmik' FROM DUAL UNION ALL
SELECT 'pgezt yozcyqq drxt gcvaj hx l ix xemimmox','e' FROM DUAL UNION ALL
SELECT 'kqclk b hkgtrh','k' FROM DUAL UNION ALL
SELECT 'sia prcrdfckg otqwvdv wzdqxvqb h xclxmaj xjdwt lzfw','crwqqhxl' FROM DUAL UNION ALL
SELECT 'teatsase','tas' FROM DUAL;
Outputs:
SENTENCE | WORD | OUTPUT :-------------------------------------------------- | :-------------- | :-------------------------------------------------- teatsase | tas | t0a0s000 fe oxyk y | ex | 0e00x0000 o wr fmik | owrfmik | o0wr0fmik kqclk b hkgtrh | k | k0000000000000 testcase string | tas | t0000as00000000 kxf jgmzejypb ya | e | 00000000e0000000 uglhwagp qvyntzmf | ulhwagpqvyntzmf | u0lhwagp0qvyntzmf qrkacxx wwfja jsyjdffa vwfgxf | qcfvf | q000c00000f000000000000v0f000 z wzsgovhh jopw igcx muxj xmmisxdn t lmb | gcujxlb | 00000g000000000000c000u0j0x0000000000l0b pgezt yozcyqq drxt gcvaj hx l ix xemimmox | e | 00e00000000000000000000000000000000000000 I do not control the speed at which lobsters die | code | 000000000co00000000000000d000000000000000e000000 sia prcrdfckg otqwvdv wzdqxvqb h xclxmaj xjdwt lzfw | crwqqhxl | 000000cr000000000w0000000q00q00h0x0l000000000000000
db<>fiddle here
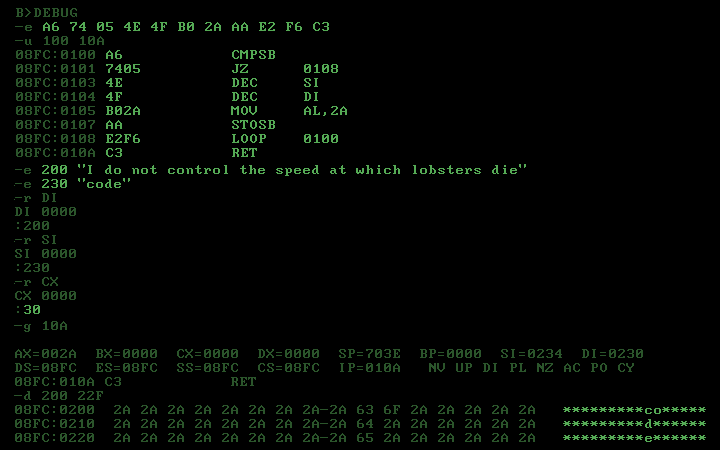
x86-16 machine code, 11 bytes
Binary:
00000000: a674 054e 4fb0 2aaa e2f6 c3 .t.NO.*....
Listing:
CHAR_LOOP:
A6 CMPSB ; compare [DI] and [SI], advance both
74 05 JZ MATCH ; if same char, do nothing
4E DEC SI ; back up target word to previous char
4F DEC DI ; back up sentence to previous char
B0 2A MOV AL, '*' ; load overstrike char
AA STOSB ; overwrite char with *, advance DI
MATCH:
E2 F6 LOOP CHAR_LOOP ; loop until end of sentence
C3 RET ; return to caller
Callable function, input sentence string at [DI], length in CX, target word string at [SI]. Output is modified string at original [DI].
Test using DOS DEBUG:
Alternate version, 11 bytes
B0 2A MOV AL, '*' ; load overstrike char
CHAR_LOOP:
F3 A6 REPZ CMPSB ; compare [DI++] and [SI++], repeat if same; CX--
4E DEC SI ; back up target word to previous char; DI--
4F DEC DI ; back up sentence to previous char; DI--
AA STOSB ; overwrite char with *; DI++
41 INC CX ; offset CX decrement from LOOP; CX++
E2 F8 LOOP CHAR_LOOP ; loop until end of sentence
C3 RET ; return to caller
Saves 1 byte using REPZ instead of JZ, however it's lost because the loop needs to end when CX is 0 and unfortunately there's no JCXNZ instruction to do exactly that. Bummer.
C (gcc), 49 46 bytes
-3 thanks to @ceilingcat
f(s,w)char*s,*w;{for(;*s;s++)*s-*w?*s=42:w++;}
Just noticed that there's another C answer that is even shorter. Nevermind, I leave mine here.
SNOBOL4 (CSNOBOL4), 134 bytes
S =INPUT
W =INPUT
N W LEN(1) . M REM . W :F(O)
S ARB . L M REM . S
O =O DUPL('*',SIZE(L)) M :(N)
O OUTPUT =O DUPL('*',SIZE(S))
END
Wolfram Language (Mathematica), 42 bytes
c_~f[a:c_:"*",b___]~d___=a<>f[b]@d
_f[]=""
Input two characters sequences as f[word][sentence].
Python 3.10.0a41, 56 bytes
f=lambda s,t:s and('*'+s)[x:=s[0]==t[:1]]+f(s[1:],t[x:])
Python 3.10 allows unparenthesized assignment expressions in indexes, which saves 2 bytes over 3.8 here, which is the newest version on TIO.
1This is the version I tested locally, this will probably work in future versions as well.
convey, 59 47 bytes
{
?;\,&:1<
v^<^ ,<$1
"=>^}"@"}
>">>#="
'*'>:<=0
Try it online!
Run with tas and tsase (output is t*as*):
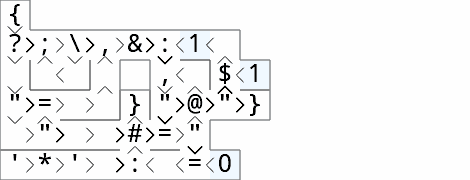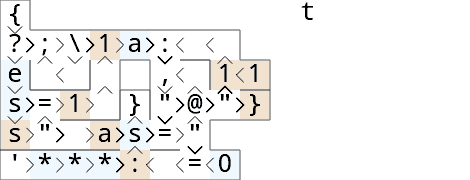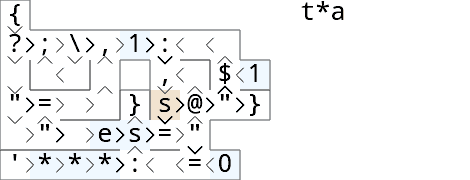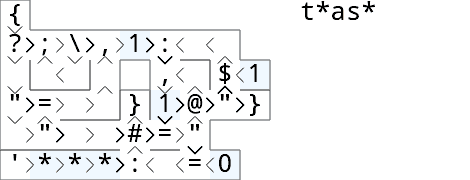
Split the input into two streams ?;\… ^<, then always take one letter :1, compare it with the head =, and either @ put the letter back into the queue , and output a '*'$…}, or output the letter } and take the next letter $1.
After the queue is empty, to output the rest of the string, we push some dummy 1 values into the queue (by comparing the input with itself).
Japt, 9 bytes
®¥VÎ?Vj:Q
input:
> sentence as a string
> target as a char array
output blanked out with "
® - for each char in sentence:
¥VÎ? - == to first element in target?
Vj - returns first element and remove it from array
:Q - character "
Perl 5 -plF, 31 bytes
$_=<>;s/./$&ne$F[0]||shift@F/ge
Input is on two lines. The first line is the target word. The second line is the sentence. Uses 1 as the blanking character.
Red, 71 bytes
func[s t][c: take t parse s[any[change[not c skip]"*"| c(c: take t)]]s]
C (gcc), 52 44 bytes
Saved 8 bytes thanks to the man himself Arnauld!!!
f(s,t)char*s,*t;{for(;*s++=*s-*t?42:*t++;);}
Function takes two input strings and return the meme-formatted string in the first parameter.
Explanation
f(s,t)char*s,*t;{ // function inputs two strings
for(; // loop
*s // until end of string s
++ // bumping s each loop
= // set character in s to...
*s-*t? // depending on whether it equals character in t
42: // a '* if not equal
*t++ // or character in t and bump t if equal
;);
}
R, 102 98 bytes
function(s,w,`[`=substring){for(i in 1:nchar(s))`if`(s[i,i]!=w[1,1],substr(s,i,i)<-"*",w<-w[2]);s}
function(s,w, # s=sentence, w=word
`[`=substring) # `[` = alias to substring function
{for(i in 1:nchar(s)) # loop over all the indexes of characters in s
`if`(s[i,i]!=w[1,1], # if it isn't the same as the first character in w
substr(s,i,i)<-"*", # change it to a '*'
w<-w[2]); # otherwise leave it and remove the first character in w
s # finally, return whatever's left in s
Or, with vectors of characters (instead of strings) as input & output (thanks to user for the suggestion):
R, 75 bytes
function(s,w)sapply(s,function(l)`if`(length(w)&l==w[1],{w<<-w[-1];l},'*'))
Haskell, 61 59 44 bytes
Saved 1 16 bytes thanks to @ovs!
(a:b)%(c:d)|a==c=a:b%d
(_:b)%c='*':b%c
e%_=e
Racket, 140 bytes
(define(f s t[a'()])(if(null? s)(reverse a)(if(char=?(car s)(if(null? t)#\*(car t)))(f(cdr s)(cdr t)(cons(car s)a))(f(cdr s)t(cons #\*a)))))
I know, this is super long and silly.
Retina 0.8.2, 37 bytes
.
_$&
+`.(.)((_.)*¶)_\1
$1_$2
(.).
$1
Try it online! Uses _ as the filler. Explanation:
.
_$&
Prepend a _ to every character (both of the string and the target).
+`.(.)((_.)*¶)_\1
$1_$2
Find a character which is not before a character that has already been swapped that matches the first character of the original target, and swap it with its preceding _, removing it from the target, and repeat until the target is empty.
(.).
$1
Remove alternate characters, i.e. keeping the _s unless the target character was swapped.
05AB1E, 12 11 10 bytes
v¬yQić?ë0?
-1 byte by using 0 as filler character instead of *.
Try it online or verify all test cases.
Explanation:
v # Loop over the characters `y` of the (implicit) input-sentence:
¬ # Get the first character without popping the string
# (which uses the implicit input-target the first iteration)
yQi # If this first character is equal to the current character `y`:
ć # Extract the head of the target-string; pop and push the remainder-string and
# first character separated to the stack
? # Pop and print this first character
ë # Else:
0? # Print 0 instead
JavaScript (ES6), 35 bytes
Expects (haystack)(needle), where haystack is a list of characters and needle is either a list of characters or a string. Returns a list of characters. The blank-out character is 0.
s=>w=>s.map(c=>c==w[s|=0]?++s&&c:0)
Commented
s => // s[] = sentence as an array of characters
w => // w = word
s.map(c => // for each character c in s[]:
c == w[s |= 0] // we re-use s[] as a pointer into w; it's safe to
// coerce it to a number with a bitwise OR because
// s[] is guaranteed to contain only spaces and letters
? // if c is equal to w[s]:
++s && c // increment s and yield c
: // else:
0 // yield the blank-out character "0"
) // end of map()
Ruby -pl, 38 37 bytes
->t{gsub(/./){$&==t[0]?$&+t[0]*=0:0}}
Takes the sentence from STDIN and the target word as the lambda argument. Uses 0 as the blank-out character, an idea borrowed from @Arnauld's JavaScript answer, which saves a byte over using *.
For each character in the sentence:
If it is the same as the first character of the target word, retain it. Then remove the first character of the target word (
t[0]*=0is a slightly obfuscated equivalent tot[0]='').Otherwise, replace it with
0.
Charcoal, 19 bytes
≔⪪⮌⁺S¶¹θ⭆S∧⁼ι§θ±¹⊟θ
Try it online! Link is to verbose version of code. Takes input in the order target, string. Output uses 0 as filler (+1 byte to use an arbitrary filler character). Explanation:
≔⪪⮌⁺S¶¹θ
Append a newline to the input target, reverse it, and split it into characters.
⭆S∧⁼ι§θ±¹⊟θ
Loop over the input string, replacing each character with 0, unless the character matches the last element of the above list, in which case pop that element instead.