| Bytes | Lang | Time | Link |
|---|---|---|---|
| 031 | Uiua | 240821T221549Z | noodle p |
| 304 | Brainf**k | 240821T170156Z | madeforl |
| 060 | YASEPL | 240208T193818Z | madeforl |
| 073 | TypeScript's type system | 240202T232138Z | noodle p |
| 033 | Rattle | 240202T185823Z | Daniel H |
| 035 | Uiua | 240202T173931Z | Joao-3 |
| nan | 240202T145954Z | Larry Ba | |
| 014 | Thunno 2 | 230622T174640Z | The Thon |
| 121 | C++ | 230601T174535Z | Wallace |
| 065 | Rockstar | 200928T152028Z | Shaggy |
| 043 | Julia 0.6 | 230519T135158Z | MarcMush |
| 8375 | Vyxal j | 230519T130428Z | emirps |
| 078 | Rust | 211118T160715Z | Mayube |
| 043 | ErrLess | 211118T082422Z | Ruan |
| 054 | AWK | 211118T050440Z | Pedro Ma |
| nan | C gcc 99 bytes | 210428T171712Z | user1033 |
| 047 | Vim | 210427T150603Z | Aaroneou |
| 069 | AWK | 210425T200607Z | cnamejj |
| 016 | Vyxal | 210424T174020Z | Wasif |
| 038 | K | 201005T224734Z | J. Sendr |
| 020 | Husk | 201006T033616Z | Razetime |
| 052 | Python 3 | 200903T050018Z | aidan062 |
| 027 | Pip | 200903T060350Z | Razetime |
| 100 | Whispers v2 | 200908T143408Z | caird co |
| 053 | Java 8 | 200903T074551Z | Kevin Cr |
| 080 | C gcc | 200905T105605Z | willmcph |
| 063 | Io | 200905T103614Z | user9649 |
| 125 | GFA Basic Atari ST | 200905T153416Z | Xvolks |
| 083 | Dart | 200904T174648Z | jmizv |
| 065 | C gcc | 200903T104632Z | AZTECCO |
| 051 | Javascript ES6 | 200904T232332Z | Qwertiy |
| 052 | flex | 200903T193813Z | Noodle9 |
| 056 | Befunge93 | 200904T172602Z | Abigail |
| 030 | Perl 5 + 0pF | 200903T055939Z | Dom Hast |
| 066 | Forth gforth | 200904T152907Z | reffu |
| 4140 | x8616 machine code | 200903T140245Z | 640KB |
| 072 | PHP | 200904T100847Z | RFSnake |
| nan | Lenguage | 200903T044821Z | Jo King |
| 033 | Ruby 0p | 200903T034519Z | Dingus |
| 044 | PowerShell | 200903T200300Z | Veskah |
| 057 | Wolfram Language Mathematica | 200903T194053Z | ZaMoC |
| 066 | JavaScript | 200903T080737Z | NoOorZ24 |
| 017 | Jelly | 200903T161036Z | Jonathan |
| 080 | Lua | 200903T164545Z | val - di |
| 049 | JavaScript | 200903T145928Z | Shaggy |
| 044 | ><> | 200903T135132Z | SE - sto |
| 031 | Haskell Hugs 2006 | 200903T155613Z | Michael |
| 9263 | SimpleTemplate 0.84 | 200903T120450Z | Ismael M |
| 094 | SNOBOL4 CSNOBOL4 | 200903T141410Z | Giuseppe |
| 076 | R | 200903T121751Z | Cong Che |
| 063 | Excel | 200903T123502Z | Engineer |
| 024 | Arn | 200903T121626Z | ZippyMag |
| 065 | Red | 200903T102915Z | Galen Iv |
| 021 | Charcoal | 200903T093130Z | Neil |
| 064 | Batch | 200903T092017Z | Neil |
| 084 | R | 200903T085903Z | Dominic |
| 020 | MathGolf | 200903T084719Z | Kevin Cr |
| 017 | 05AB1E | 200903T052956Z | lyxal |
| 019 | Japt | 200903T062041Z | Mukundan |
| 025 | Pyth | 200903T060508Z | Mukundan |
| 032 | APL Dyalog Unicode | 200903T054156Z | Adá |
| 049 | Python 3 | 200903T051951Z | xnor |
| 023 | Gema | 200903T043235Z | manatwor |
| 058 | Python 3 | 200903T041558Z | Manish K |
| 052 | Python 3 | 200903T041713Z | Mukundan |
Uiua, 31 bytes
&p♭↯⊙"Hello World"⍤"err"≍"h"◴⟜⧻
Try it online: Uiua pad
Assert that the string matches "h" when deduplicated, throwing an error with the message "err" if not, and print "Hello World" as many times as the string's length.
Brainf**k, 306 304 bytes
>+[[-]>>,[<+<+>>-]++++++++[<---->-]<]<[-]<[<]>[<+++++++[>---------------<-]>+[[[-]>]++++++++++[>++++++++++<-]>+.+++++++++++++..[-]<+>][<->+]+<[>-<[-]]>[[-]<++++++++[>+++++++++<-]>.<+++++++[>++++<-]>+.+++++++..+++.[-]<++++++++[>++++<-]>.<+++++++++++[>+++++<-]>.<++++++[>++++<-]>.+++.------.--------.[-]]>]
I'm still very new at brainf**k and this was very fun to make!
it requires a space at the end to know when to start
my best explanation
in comments i use a semicolon instead of a comma because... yknow
>+ we keep ptr(0) at 0 to make it easier to go back to the beginning of the tape
[
uses 3 cells for each character
with 2 being temporary and for building other numbers
1: where the character is stored
2: duplicate character to make sure the character isn't a space
3: original character location; but gets reused as the builder for checking if character isnt a space after it gets moved
[-] clears the duplicate character to make room for next character
>>, get input and set it to location 3
[<+<+>>-] move the input to location 1 and 2; removing it from 3
++++++++[<---->-]< subtract location 2 by 32 (space character)
] if location 2 is zero; that means a space was entered and the program may start
<[-] clear the final character (the space)
<[<]> go back go ptr(0)
[ main program loop
<+++++++[>---------------<-]>+ subtract the character by 104 to see if it is 0
[[[-]>]++++++++++[>++++++++++<-]>+.+++++++++++++..[-]<+>] if it isn't; remove everything; print "err" and quit
[<->+]+< move character 1 cell to the left to initalize the NOT algorithm
[>-<[-]]> NOT algorithm (if the character is 0 then)
[ If the character IS 0 (aka the NOT algorithm passed); then print Hello World
[-]
<++++++++[>+++++++++<-]>. H
<+++++++[>++++<-]>+. e
+++++++. l
. l
+++. o
[-]<++++++++[>++++<-]>.
<+++++++++++[>+++++<-]>. W
<++++++[>++++<-]>. o
+++. r
------. l
--------. d
[-] Erase the text
Go back one to end the loop
]
> Go up 2 to continue the loop until there's no more data
]
```
YASEPL, 60 bytes
=b=1'=c®1`1!d¥b,1}7,"h",8!+}2,c;"Hello World",c<|9`8>"err"`9
explanation
=b=1'=c®1`1!d¥b,1}7,"h",8!+}2,c;"Hello World",c<|9`8>"err"`9 packed
=b declare increment variable "b"
=1' get user input and set it to variable "1"
=c®1 get length of variable 1 and set it to "c"
`1 }2,c while b < c...
!d¥b,1 get a character from variable 1 at index b and set it to "d"
}7,"h",8 `8 if d is equal to "h"...
!+ add one to b.
>"err" ...else, escape loop, error and quit
;"Hello World",c< repeat "Hello World" c times once done checking if everything is "h" and print it
|9 go to the end of the program
`9 end of the program
(im trying my best to format the explanation like how other people are. if it doesnt make sense tell me)
TypeScript's type system, 73 bytes
type F<S>=S extends`h${infer S}`?`Hello World${F<S>}`:S extends""?S:"err"
TypeScript's type system is well suited for tasks like this.
This version hits the recursion limit for strings longer than 50 characters. Here's an alternate version, using tail-recursion to increase the limit from 50 to 999:
TypeScript's type system, 93 bytes
//@ts-ignore
type F<S,O="">=S extends`h${infer S}`?F<S,`${O}Hello World`>:S extends""?O:"err"
Rattle, 33 bytes
|II^P[gn[^104/0]b"Hello World">]`
Explanation:
| take input
I split input to characters and store characters in consecutive memory slots
I^ get length of input (put on top of the stack)
P set pointer to 0
[...]` repeat n times, where n is the top of the stack
g get the value at the pointer
n get the ASCII int value of the character
[^104 ] if not 104 (the ASCII value for 'h')
/0 divide by 0 (shortest way to throw an error)
b"Hello World" add "Hello World" to print buffer
> move pointer right
Uiua, 35 bytes
&p("err"|▽:"Hello World")≍⊙:↯:@h.⧻.
Outputs to stdout for compliance with the challenge.
Here are some different approaches I tried.
Python 3.8 (pre-release), 57 bytes
lambda s:"Hello World"*(x:=s.count("h"))+"err"*(len(s)-x)
Python 3.8 (pre-release), 60 bytes
lambda s:"err"if(x:=s.count("h"))!=len(s)else"Hello World"*x
Python 3.8 (pre-release), 63 bytes
lambda s:"Hello World"*x if len(s)-(x:=s.count("h"))<1else"err"
Python 3.8 (pre-release), 66 bytes
lambda s:eval("'err''Hello World'*x"[(x:=len(s)-s.count("h"))+5:])
(Disclaimer: Does not work.)
I'm not sure if 1/0 is okay (it outputs a ZeroDivisionError) but if it is of course that would be bytes saved.
Thunno 2, 14 bytes
U'h=?{kh£}:`~Ɱ
Explanation
U'h=?{kh£}:`~Ɱ '# Implicit input
U # Uniquify the input
'h=? '# If it equals "h":
{ } # Length of input times:
kh£ # Print "Hello World"
# No implicit output
: # Otherwise:
`~Ɱ # Push compressed string "Error"
# Implicit output
C++, 192 121 bytes
#include <iostream>
int main() {
char a;
while (true) {
std::cout << ">> ";
std::cin >> a;
if (a != 'h') {
std::cout << "err";
}
else {
std::cout << "hello world\n";
}
}
}
Edit: Shrunken to 121 bytes
#include <iostream>
int main(){char a;while(1){std::cin>>a;if(a!='h'){std::cout<<"err";}else{std::cout<<"hello world";}}}
Rockstar, 84 65 bytes
listen to S
cut S
while S
say roll S's "h" and "Hello World" or e
Try it here (Code will need to be pasted in)
Vyxal j, 67 bitsv1, 8.375 bytes
ƛ\h=[kH|«½F
ƛ # map the following over the input
\h=[ # if it is equal to `h`
kH # push `Hello World`
| # else
«½F # push the compressed string `err`
Rust, 85 78 bytes
|n:&str|for c in n.chars(){if c=='h'{print!("Hello World")}else{todo!("err")}}
I tried to get clever with rust iterators and map_while, but it ended up being much more golfy to just do a boring for loop :(
Even pattern matching is longer...
todo!(err) is a macro that always panics with the message not yet implemented: err, the key difference being that todo! is 1 byte shorter than panic!, the standard panic macro.
ErrLess, 43 bytes
SSQl0=2+].0g'h=1-[{SHello WorldS?c]}SerrS?.
SSQ { Get one line of input }
l0= { Is the program empty? }
2+]. { If so, halt (-1 -- True -> 1, move IP to `.`; 0 -- False -> 2, move IP past `.`) }
0g { Pop first element from program, pushing to the stack }
'h= { Is equal to 'h'? }
1-[{ ... } { If so, }
SHello, WorldS? { Print "Hello World" }
c] { Skip 12 chars forward (loops back to start of program, skipping `SSQ`) }
{ Else }
SerrS? { Print "err" }
. { Halt }
AWK, 54 bytes
BEGIN{RS="^$"}/[^h]/{$0="err"}1gsub(/h/,"Hello World")
BEGIN{RS="^$"}
We begin setting the Record Separator as "^$", which makes AWK read the input as a whole.
/[^h]/{$0="err"}
If there is anything different from h, the whole input is substituted by the "err" string.
1gsub(/h/,"Hello World")
This is the number 1 and the result of gsub(/h/,"Hello World") concatenated, which will be evaluated as an AWK pattern. gsub tries to find every h, and substitutes each one for a Hello World. If $0 was changed for err, gsub returns 0, hence the concatenation. Thus, It will always result true, printing $0 (simply err or a bunch of Hello World).
C (gcc) - 99 bytes, input using stdin
i;main(){char x[99];gets(x);for(;x[i];++i){if(x[i]-'h'){puts("err");break;}puts("Hello World");}}
(Like I said in my last answer to some other question) This program can only handle 99 characters, and uses the unsafe gets() function.
An alternative, also 99 bytes:
i;main(){char x[99];gets(x);for(;x[i];++i){if(x[i]-104){puts("err");break;}puts("Hello World");}}
Vim, 48 47 bytes
Thanks to @DLosc for -1 bytes
:g/\_$\_^\|[^h]/norm HcGerr
:s/h/Hello World/g
The :g command is a bit convoluted, but there's a reason for that. The [^h] part will match all non-h characters, but it won't match newlines. $ or \n will match end-of-line, which means they will match a single line without a newline. To make it match only when there are multiple lines, I used \_$\_^. This will only match newlines (\_$) that are followed by another line (\_^).
For some reason, this doesn't work properly in TIO, so programs where the only non-h characters are newlines won't error. However, this does work properly in Vim.
Explanation:
:g/ (x) / (y) # If x exists, execute y:
\_$\_^ # x -> An end-of-line followed by a start-of-line;
\|[^h] # OR any character that isn't 'h'
norm HcGerr # y -> Delete all lines, then print 'err'
:s/h/Hello World/g # Replace every 'h' with 'Hello World'
AWK, 69 bytes
a=b=length($0){for(;b--;)x=x"Hello World"}$0=NR*gsub("h",c)-a?"err":x
The command to get a string length is pretty long in AWK, so this
a=b=length($0)
saves the values in two variables for use later. Since we're guaranteed some input, the test is always truthy and the code will execute.
{for(;b--;)x=x"Hello World"}
The body just appends copies of Hello World to x, one for each letter in the input.
$0=NR*gsub("h",c)-a?"err":x
Sets the default output $0 to err or the string of concatenated Hello World strings. The gsub("h",c)-a is truthy if number of h characters in the input matches the length of the string. The NR* multiple will sabotage the comparison if this isn't the first input line.
Well then... After reading some other entries, and specifically the one from jmizv I realized a simpler (and shorter) approach like this works.
NR*length($0)!=gsub("h","Hello World"){$0="err"}1
But that's a completely different program, so I'm going to leave the original one in place.
Vyxal, 16 bytes, Courtesy of Lyxal
\hJ≈[\h↔Lkh*|«∧↳
Vyxal, 32 bytes
\hṡ¤=≈['\h=;L`Hello World`*|`err
K, 38 bytes
{$[&/"h"=x;,/{"Hello World"}'x;"err"]}
{..x..}defines a function with implicit arg x.$[cond; a; b]corresponds to a "if (cond) {a} else {b}" sentence- The condition
&/"h"=xcan be read as "((string x).map(char is "h").reduce(and))" ,/{..}'xdefines a function that applies to each char of x, and catenates results.{"Hello World"}is a function without args that returns string "Hello World" `
Examples
{$[&/"h"=x;,/{"Hello World"}'x;"err"]}"hhhh"
"Hello WorldHello WorldHello WorldHello World
{$[&/"h"=x;,/{"Hello World"}'x;"err"]}"hhxh"
"err"
Pip, 28 27 bytes
aRM'h?"err""Hello World"X#a
-1 byte from DLosc.
If the string without h's is empty, print "Hello World" required number of times.
Otherwise, error.
This program errors on empty input as well.
Whispers v2, 100 bytes
> InputAll
> "Hello World"
> "h"
> "err"
>> 1∖3
>> Output 4
>> #1
>> 2⋅7
>> Output 8
>> If 5 6 9
Java 8, 65 53 bytes
s->s.matches("h+")?s.replace("h","Hello World"):"err"
-12 bytes thanks to @corvus_192.
Explanation:
s-> // Method with String as both parameter and return-type
s.matches("h+")? // If the input consists solely of 1 or more "h":
s.replace("h", // Replace all "h" in the input
"Hello World") // with "Hello World"
: // Else:
"err" // Return "err" instead
C (gcc), 84 80 bytes
-4 bytes thanks to ceilingcat. It's beautiful!
main(c,v)char**v;{*v[1]++-'h'?*--v[1]&&puts("err"):main(puts("Hello World"),v);}
Not so fancy, but I like that it's a complete program :)
"Normal" version:
#include <stdio.h>
int main(int argc, char** argv)
{
if (*argv[1]++ - 'h')
return *--argv[1] && puts("err");
else
return main(puts("Hello World"), argv);
}
Io, 63 bytes
method(:,:foreach(X,if(X!=104,"err"print-,"Hello World"print)))
Explanation
method(i, // Take input
i foreach(X, // For every item:
if(X!=104, // If the codepoint isn't 104:
"err"print // print "err" (w/o nl)
- // Subtract "err" by the "Object" class (causes error)
,"Hello World"print // Otherwise, print "Hello World" (w/o nl)
)))
GFA Basic (Atari ST), 125 bytes
INPUT a$
FOR i=1 TO LEN(a$)
b$=MID$(a$,i,1)
IF b$="h"
PRINT "Hello World"
ELSE
PRINT "err"
EXIT IF 1
ENDIF
NEXT I
Dart, 83 bytes
void h(p)=>print(p.contains(RegExp("[^h]"))?"err":p.replaceAll("h","Hello World"));
My first try on Dart although I'm not completely familiar with it. Maybe the call of the method can be shortend.
Explanation: simply check with a Regular Expression if there is something else than h in the input. If so print err, else replace all the h with Hello World.
C (gcc), 71 65 bytes
f(char*p){p=*p-'h'?*p&&puts("err"):f(p+1)||!puts("Hello World");}
- Thanks to @rtpax for saving 6!
f(char*p){p= - function tacking a program and returning with the eax trick, reusing p.
Calls itself recursively.
Recursion happens before program execution so if all steps are correct a false value is returned and the program is executed.
If there's an error a truthy value is returned and program is not executed at all, an error message is displayed.
*p-'h'? `...` :f(p+1)||!puts("Hello World");
- check each character in program : if h continue recursion and
if result is false program do its job.
p is true if there was an error, false instead.
- if not h stop recursion and :
*p - if end of program
p is false
&&puts("err") - if not end of program display error
p is true.
61 58 bytes alternative less interesting solution which runs the program and stops when an error happens
f(char*p){*p&&puts(*p-'h'?"err":"Hello World")>4&&f(p+1);}
- Saved 3 thanks to @rtpax !
Javascript ES6, 51 chars
s=>s.replace(/h|.+/g,m=>m=='h'?"Hello World":"err")
Runnable example:
f=s=>s.replace(/(h)|.+/g,(m,h)=>h?"Hello World":"err") // 52 chars
f=s=>s.replace(/h|.+/g,m=>m=='h'?"Hello World":"err") // 51 chars
inp.addEventListener('input',e=>out.textContent=f(inp.value))input { width: 100%; box-sizing: border-box; }<input id=inp autofocus>
<output id=out></output>flex, 76 \$\cdots\$ 55 52 bytes
%%
h puts("Hello World");
[^h] puts("err");exit(1);
Put the above code in a file called hello.l and make the interpreter with:
flex hello.l && gcc lex.yy.c -o hello -lfl
Trying it on my terminal:
> echo -n hhh|./hello.exe
Hello World
Hello World
Hello World
With newline:
> echo hhh|./hello.exe
Hello World
Hello World
Hello World
err
notice the err because of the trailing newline echo normally sends.
With non-h character:
> echo -n hhhehhh|./hello.exe
Hello World
Hello World
Hello World
err
Befunge-93, 58 56 bytes
~:1+!#v_"h"-#v_"dlroW olleH",,,,,,,,,,,
@,,,@#"err"<
How does it work?
~ # Read a character.
:1+! # Check whether we read -1 (end of input);
# this leaves 1 on the stack if we are at
# the end of the input, else 0.
#v_ # Exit the program if we're at the end
@ # end of the input.
"h"- # Compare the read character with the
# character "h", if equal, we leave 0 on
# the stack, otherwise, non-zero.
#v_ # If we read anything but "h", print "err"
@,,,@#"err"< # and exit the program.
"dlroW olleH",,,,,,,,,,, # Print "Hello World"
Perl 5 + -0pF, 30 bytes
Thanks to Abigail for helping let me know about a bug and providing a solution.
$_=/[^h]/?err:"Hello World"x@F
Forth (gforth), 66 bytes
: f bounds do i c@ 'h - if ." err"leave then ." Hello World"loop ;
Code Explanation
: f \ start a new word definition
bounds \ get starting and ending address for string
do \ loop from starting char address to ending char address
i c@ \ get character at current address
'h - \ check if not equal to "h" (save a byte by using - instead of <>)
if \ if character is not h
." err"leave \ print "err" and exit the loop
then \ end if
." Hello World" \ print "Hello World"
loop \ end the loop
; \ end the word definition
x86-16 machine code, IBM PC DOS, 41 40 bytes
Binary:
00000000: be82 00ba 1801 b409 ac3c 0d74 0a3c 6874 .........<.t.<ht
00000010: 02b2 24cd 2174 f1c3 4865 6c6c 6f20 576f ..$.!t..Hello Wo
00000020: 726c 6424 6572 7224 rld$err$
Listing:
BE 0082 MOV SI, 82H ; SI to DOS PSP
BA 0118 MOV DX, OFFSET HW ; point to 'Hello World' string
B4 09 MOV AH, 9 ; DOS write string function
CHAR_LOOP:
AC LODSB ; AL = next input byte
3C 0D CMP AL, 0DH ; is a CR (end of input string)?
74 0A JZ DONE ; if so, end
3C 68 CMP AL, 'h' ; is an 'h'?
74 02 JZ WRITE_STR ; if so, write Hello(s)
B2 24 MOV DL, LOW OFFSET ER ; otherwise, point to 'err' string
WRITE_STR:
CD 21 INT 21H ; write string to stdout
74 F1 JZ CHAR_LOOP ; if 'h', keep looping
DONE:
C3 RET ; return to DOS
HW DB 'Hello World$'
ER DB 'err$'
Standalone PC DOS executable COM program. Input via command line. This version prints Hello Worlderr if an error is in the input code.
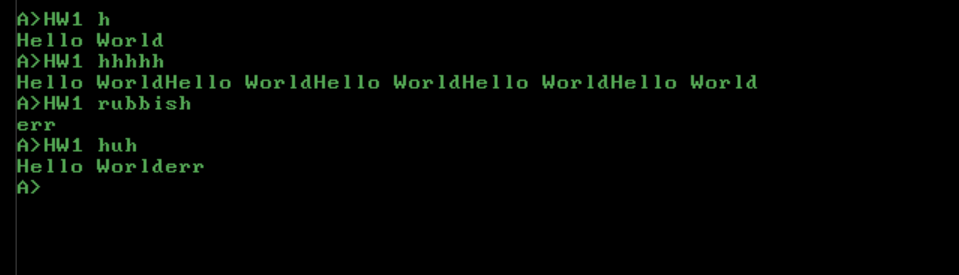
And for fun (and since I did it first), this version will only print err if an error is in the code.
x86-16 machine code, IBM PC DOS, 47 45 44 bytes
Binary:
00000000: bf80 00ba 1c01 8a0d 4951 abb8 6809 f3ae ........IQ..h...
00000010: 5974 04b2 28b1 01cd 21e2 fcc3 4865 6c6c Yt..(...!...Hell
00000020: 6f20 576f 726c 6424 6572 7224 o World$err$
Listing:
BF 0080 MOV DI, 80H ; DI to DOS PSP
BA 011C MOV DX, OFFSET HW ; point to 'Hello World' string
8A 0D MOV CL, BYTE PTR[DI] ; CL = input length
49 DEC CX ; remove leading space from length
51 PUSH CX ; save length for later
AB STOSW ; DI to start of command line input
B8 0968 MOV AX, 0968H ; AL = 'h', AH = 9
F3/ AE REPZ SCASB ; search input for 'h': ZF if Hello, NZ if error
59 POP CX ; restore input length
74 04 JZ HELLO_LOOP ; if no error, write Hello(s)
B2 28 MOV DL, LOW OFFSET ER ; otherwise, point to 'err' string
B1 01 MOV CL, 1 ; only show 'err' once
WRITE_LOOP:
CD 21 INT 21H ; write string to stdout
E2 FC LOOP WRITE_LOOP ; loop until done
C3 RET ; return to DOS
HW DB 'Hello World$'
ER DB 'err$'
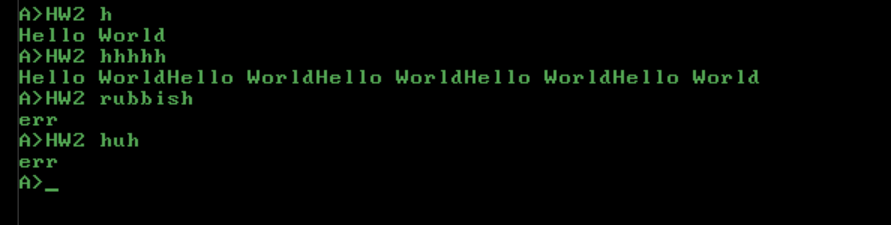
Props:
- -1 byte for both thanks to @MatteoItalia for suggestion to change only the low byte on the error string pointer.
PHP, 72 bytes
<?=trim($a=$argv[1],'h')!=''?'err':str_repeat('Hello World',strlen($a));
Lenguage, \$1.42 \times 10^{122}\$ bytes
minus a lot of bytes thanks to Kevin Cruijssen and Bubbler
hhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhh...
This is 142099843608359281286315447494338058415442968773543757980908246691462388164856076679905341690709953072132211450166077106439 hs, which also makes it a valid Hello program, though not one you'd want to run. The original brainfuck code is 140 135 bytes:
,[>-[<-->-----]+<--[>]>[[-->-[>>+>-----<<]<--<---]>-.>>>+.>>..+++.>>.>.<<<.+++.------.<<-.[>]>>>>,>]<]<[[>++<+++++]>-.+++++++++++++..>]
This prints Hello World every time it sees a h through a modification of the shortest known Hello, World! program, stopping the loop and printing err if it sees anything other than a h.
Ruby -0p, 42...35 33 bytes
The idea to use the -0p flags (instead of -n like I originally had) came from @DomHastings's Perl answer, saving 4 bytes.
$_=/[^h]/?:err:'Hello World'*~/$/
Reads the program from STDIN. A regex is used to check whether the program contains any character other than h. If so, print err; otherwise, print Hello World as many times as the number of characters in the program (given by ~/$/).
Using a bare regex literal as a boolean is a deprecated Perlism that (since Ruby 1.9) only works with the -n or -p flags.
Wolfram Language (Mathematica), 57 bytes
""<>If[Union@#=={"h"},"Hello World"~Table~Tr[1^#],"err"]&
JavaScript 72 66 bytes
-6 bytes thanks to @Ismael Miguel
alert(/^h*$/.test(a=prompt())?a.replace(/h/g,'Hello World'):'err')
Jelly, 17 bytes
14 if we can print Err as a substring of the output (e.g. “½,⁾ẇṭ»€!fƑ?”h TIO).
“½,⁾ẇṭ»€“¹ṫ»fƑ?”h
How?
“½,⁾ẇṭ»€“¹ṫ»fƑ?”h - Main Link: program
”h - set right argument to 'h'
? - if...
Ƒ - ...condition: is (program) invariant under?:
f - keep only ('h's)
€ - ...then: for each (c in program):
“½,⁾ẇṭ» - "Hello World"
“¹ṫ» - ...else: "error"
- implicit, smashing print
Lua, 80 bytes
(...):gsub('.',load'print(...=="h"and"Hello World"or print("err")or os.exit())')
Not really fun...
Or, if 'err' can be a part of error message, like python example from question:
Lua, 67 bytes
(...):gsub('.',load'print(...~="h"and ("err")() or "Hello World")')
By calling "err", it will appear in error message.
JavaScript, 49 bytes
-4 bytes if we can throw an error instead of outputting a string.
f=([c,...a])=>c?c==`h`?`Hello World`+f(a):`err`:a
><>, 44 bytes
i:0(?;"dlroW olleH"oooooooo!;ooo"errh"{=?!|]
Always fun when one can golf by reusing some of the code by running it backwards.
i:0(?;"rre'oodlroW olleH"o83*0l9)?.{"h"=?!']
Alternatively, for the same byte count, one can exploit the fact that "dlroW", "World" backwards, can be used to print an additional character and terminate.
Haskell (Hugs 2006), 31 bytes
mapM(\'h'->putStr"Hello World")
Pending a question to the OP r.e. "error" in a larger error message.
The spec says "it must print err or error", which it does on Hugs 2006, specifically the Raskell 1.0.13 interpreter based on Hugs 2006:
> mapM(\'h'->putStr"Hello World") "huh"
Hello World
Program error: pattern match
failure: ww_v4136 'u'
SimpleTemplate 0.84, 92 63 bytes
This challenge was simple, yet fun!
Simply checks if the input is just "hhh...." and outputs the text, or outputs "err" to STDOUT:
{@ifargv.0 matches"@^h+$@"M}{@eachM.0}Hello World{@/}{@else}err
The big byte saving was due to the-cobalt's comment:
Outputting to STDOUT is fine, so you could use your 63 byte version.
Ungolfed:
Below is a more readable version of the code:
{@if argv.0 matches "@^h+$@"}
{@each argv.0 as h}
{@echo "Hello World"}
{@/}
{@else}
{@echo "err"}
{@/}
You can try this on: http://sandbox.onlinephpfunctions.com/code/e35a07dfbf6b3b56c2608aa86028b395ef457129
SNOBOL4 (CSNOBOL4), 94 bytes
I =INPUT
I NOTANY('h') :S(E)
OUTPUT =DUPL('Hello World',SIZE(I)) :(END)
E OUTPUT ='err'
END
I =INPUT ;* Read input
I NOTANY('h') :S(E) ;* If there is a character that's not 'h' in the input, goto E
OUTPUT =DUPL('Hello World',SIZE(I)) :(END) ;* else print "Hello World" repeatedly and goto END
E OUTPUT ='err' ;* print 'err'
END
R, 76 bytes
function(p,n=nchar(p))ifelse(p==strrep('h',n),strrep("Hello World",n),'err')
Should be a comment on https://codegolf.stackexchange.com/a/210520/98085 - I didn't realise you could do functions like that! Slight change to be more robust when n = 0 and to use direct comparison rather than regex. -1 byte thanks to https://codegolf.stackexchange.com/users/90265/zippymagician.
Bonus version with side-effects (like redefining subtraction) thanks to https://codegolf.stackexchange.com/users/92901/dingus.
R, 71 bytes
{`-`=strrep;function(p,n=nchar(p))`if`(p=='h'-n,'Hello world'-n,'err')}
Excel, 63 bytes
=IF(SUBSTITUTE(A1,"h","")="",REPT("Hello World",LEN(A1)),"err")
SUBSTITUTE(A1,"h","")="" returns TRUE iff A1 contains nothing but h.
REPT("Hello World",LEN(A1)) repeats the string for however many characters are in A1.
=If(Substitute(~)="",REPT(~),"err") returns the repeated string if A1 contains only h and err if it contains anything else.
Arn, 24 bytes
ùÝ└ån<⁼aLw$■v&Z(#▄╗└·I╔║
Explained
Unpacked: (${="h"})#=#&&'yt bs'^#||"err
And this is why I need to add an if else...
( Begin expression
$ Filter
{ Block with index of _
_ Implicit
= Equals
"h" String
} End block
_ Variable initialized to STDIN; implied
) End expression
# Length
= Equals
_ Implied
#
&& Boolean AND
'yt bs' Compressed string equal to "Hello World"
^ Repeated
_ Implied
#
|| Boolean OR
"err
Charcoal, 21 bytes
¿⁻θh¦err⭆θHello World
Try it online! Link is to verbose version of code. Explanation:
¿⁻θh
Delete all hs from the implicit input.
err
If the result is empty then output err.
Fθ
Otherwise the input only contains hs. Loop over each h.
Hello World
Output Hello World for each one.
Other options for the same byte count:
¿⁻θh¦err⭆θHello World
Replaces each h with Hello World and prints the result.
¿⁻θh¦errEθHello World
Prints each Hello World on its own line.
Batch, 64 bytes
@set/ps=
@if "%s:h=%"=="" (echo %s:h=Hello World%)else echo err
Takes input on STDIN. If replacing the hs in the input results in an empty string, output the result of replacing the hs with Hello World otherwise output err.
R, 84 bytes
function(p,n=nchar(p))`if`(n-lengths(gregexpr("h",p)),"err",strrep("Hello World",n))
As R is the Language of the month for September 2020, let's get the ball rolling with an R answer to this challenge.
However, this is still not the shortest-possible answer in R, so I'd like to encourage other not-normally-R-golfers to have a go, too...
MathGolf, 23 20 bytes
'h-╛æ╖•p0{δ╕○ô 'W╕7ÿ
Explanation:
'h- '# Remove all "h" from the (implicit) input-string
╛ # Pop, and if it's now truthy (thus non-empty):
æ # Use the following four characters as single code-block:
╖•p # Push compressed string "err"
0 # And push a 0
{ # Either loop 0 times,
# or loop over each character of the (implicit) input-string:
δ # Titlecase the implicitly pushed current character ("h"→"H")
╕○ô # Push compressed string "ello"
# Push " "
'W '# Push "W"
╕7ÿ # Push compressed string "orld"
# (implicitly output the entire stack joined together as result)
05AB1E, 17 bytes
'hÃQig”Ÿ™‚ï”×ë'‰ë
Big thanks to @Kevin for your dictionary compression tool!
And once again, Kevin has struck and managed to shave 3 bytes from my answer! So the aforementioned thanks is to be multiplied by a massive magnitude.
Explained (old)
Ð'hÃQig”Ÿ™‚ï”и»ë"err
Ð # Triplicate the input. STACK = [input, input, input]
'h # Push the letter 'h'. STACK = [input, input, input, 'h']
à # Keep _only_ the letter h in the input. STACK = [input, input, input.keep('h')]
Q # Compare this with the original input. STACK = [input, 1 OR 0]
i # If the comparison is truthy (i.e. it's only h's):
g # Push the length of the input. STACK = [len(input)]
”Ÿ™‚ï” # Push the compressed string "Hello World". STACK = [len(input), "Hello World"]
и» # Repeat that string length of input times and join upon newlines. STACK = ["\n".join("Hello World" * len(input))]
ë # Else:
"err # Push the string "err" to the stack. STACK = [input, "err"]
# Implicitly output the top of the stack
Japt, 23 19 bytes
-4 bytes thanks to @Shaggy
rh ?`r`:¡`HÁM Wld
Explanation
rh ?`...`:¡`...
? // if
rh // input with 'h' removed
`...` // then "err"
: // else
¡ // each char in input
`... // replaced with "Hello World"
Pyth, 25 bytes
?-Q\h"err"*"Hello World"l
Explanation
?-Q\h"err"*"Hello World"l
? // if
-Q\h // input with 'h' removed
"err" // then "err"
*"Hello World"l // else "Hello World" repeated len(input) times
APL (Dyalog Unicode), 32 bytes (SBCS)
Anonymous tacit prefix function.
{'h'=⍵:'Hello World'⋄-⎕←'err'}⍤0
{…}⍤0 replace each character (⍵) with the result of applying the following lambda to it:
'h'=⍵: if the character is h:
'Hello World' return the required phrase
⋄ else:
⎕←'err' print err
- negate it (causing an error and terminating)
Python 3, 49 bytes
lambda s:{*s}-{'h'}and'err'or'Hello World'*len(s)
Python 2, 51 bytes
lambda s:s.strip('h')and'err'or'Hello World'*len(s)
Python 2, 51 bytes
lambda s:['err','Hello World'*len(s)]['h'+s==s+'h']
Gema, 23 characters
h=Hello World
?=err@end
Sample run:
bash-5.0$ echo -n 'hohoho' | gema 'h=Hello World;?=err@end'
Hello Worlderr
Gema (old version with err on empty code), 32 characters
\A\Z=err
h=Hello World
?=err@end