| Bytes | Lang | Time | Link |
|---|---|---|---|
| 091 | Tcl | 180423T120007Z | sergiol |
| 039 | Perl 6 | 160508T202750Z | Ven |
| nan | 150519T162309Z | Dave | |
| 061 | Python 2 | 140703T223424Z | ToonAlfr |
| 069 | J | 140630T144323Z | jpjacobs |
| nan | 140630T131700Z | Abbas | |
| 084 | PHP | 140129T140914Z | primo |
| nan | 140129T130940Z | jimbobmc | |
| 078 | Smalltalk | 140216T234447Z | blabla99 |
| 042 | shell utils | 140325T194314Z | Geoff Re |
| 056 | Mathematica | 140325T190051Z | Martin E |
| 289 | Java 8 | 140129T113750Z | AJMansfi |
| nan | 140130T210103Z | Ven | |
| nan | 140325T121021Z | ɐɔıʇǝɥʇu | |
| nan | 140325T103513Z | user1921 | |
| 126 | Javascript | 140130T143055Z | Gaurang |
| 164 | Pure Bash no external programs | 140130T172314Z | Digital |
| 042 | grep and coreutils | 140129T083253Z | Thor |
| 057 | Powershell | 140129T213658Z | jimbobmc |
| nan | 140203T221002Z | markw | |
| 050 | q | 140130T182317Z | nightTre |
| nan | 140202T094753Z | Alex Rei | |
| 135 | Javascript | 140201T065208Z | Zachary |
| 069 | GNU awk + coreutils | 140130T140011Z | steeldri |
| 069 | Perl | 140129T085841Z | Dom Hast |
| 035 | J | 140130T203629Z | barbermo |
| 071 | k [71 chars] | 140130T185728Z | nyi |
| nan | 140130T071632Z | learner | |
| nan | 140129T155934Z | George R | |
| 097 | Python | 140129T114110Z | daniero |
| 244 | Python3 | 140130T100301Z | klingt.n |
| nan | 140129T140301Z | Azwr | |
| 169 | F# | 140129T230801Z | mattnewp |
| 049 | perl6 | 140129T184048Z | Ayiko |
| 146 | JavaScript ES5 | 140130T000708Z | C5H8NNaO |
| 332 | C# | 140129T221103Z | Merin Na |
| 040 | PowerShell | 140129T163245Z | microbia |
| 076 | Python 3 | 140129T205814Z | Dave J |
| 137 | Haskell | 140129T214101Z | Landarza |
| 082 | Groovy | 140129T121009Z | Kamil Mi |
| 065 | Ruby | 140129T084948Z | daniero |
| 006 | EcmaScript | 140129T173744Z | Toothbru |
| 087 | EcmaScript 6 | 140129T165457Z | teh_sena |
| 058 | R | 140129T115825Z | plannapu |
| 108 | Python 2.X 108 Characters | 140129T104954Z | Abhijit |
| 057 | APL | 140129T080621Z | marinus |
Tcl, 91 bytes
proc C s {lmap w [regsub -all \[^\\w|\ \] $s {}] {dict inc D $w}
lsort -s 2 -inde 1 -de $D}
Perl 6, 53 39 bytes
{.comb(/<-[_\W]>+/).Bag.sort:{-.value}}
I use .comb to find every word matching the regexp <-[_\W]>+. In Perl 6, character classes are written <[]> instead of [], and negative character classes <-[]> instead of [^].
We then transform the list of words to a Bag (a set that keeps the number of occurences), and we sort said bag by their value.
Clojure
(defn count-words [string]
(as-> string s
(clojure.string/replace s #"[^a-zA-Z0-9 ]" "")
(clojure.string/split s #"\W")
(frequencies s)
(sort-by val s)
(reverse s)))
(clojure.pprint/pprint (count-words "This is a text and a number: 31."))
;; => (["a" 2] ["31" 1] ["number" 1] ["and" 1] ["text" 1] ["is" 1] ["This" 1])
I thought I would beat markw's concision with this approach, but I didn't.
Python 2 - 61
Assuming the input is in variable s, which is more realistic in real programming than user input anyway.
import re,collections as c
print c.Counter(re.split('\W+',s))
output
Counter({'a': 2, 'and': 1, '': 1, 'This': 1, 'text': 1, 'is': 1, 'number': 1, '31': 1})
This isn't really good output me thinks. It has an empty word and isn't readable. Here's a version with neat output (90):
Python 2 (neat) - 90
import re,collections as c
d=c.Counter(re.split('\W+',s))
for w in d:
if w:print w+':'+`d[w]`
output
a:2
and:1
This:1
text:1
is:1
number:1
31:1
J 69
Should handle corner-cases like ' - etc, at the huge cost of including all alphanumeric characters (u:62$,65 97 48+/i.26):
(>@~.,.':',.":@#/.~)(#~*@#&>)(<;._1~-.@e.&(u:62$,65 97 48+/i.26))'.',
Usage: just append whatever string to be counted bewteen single quotes (mind that you need to double single quotes in the string).
Example:
(>@~.,.':',.":@#/.~)(#~*@#&>)(<;._1~-.@e.&(u:62$,65 97 48+/i.26))'.','This is a text and a number: 31. More-tests wouldn''t be bad'
This :1
is :1
a :2
text :1
and :1
number:1
31 :1
More :1
tests :1
wouldn:1
t :1
be :1
bad :1
Will never win but wanted to try anyway...
C# (118)
var i = "This is a text and a number: 31.";
//The above line is not counted
Regex.Split(i,@"[\W_]").Where(w=>w!="").GroupBy(g=>g).OrderBy(o=>-o.Count()).Select(s=>new{s.Key,V=s.Count()}).Dump();
Ungolfed:
Regex.Split(i, @"[\W_]") //split by special chars
.Where(w => w != "") //remove empty
.GroupBy(g => g) //group by word
.OrderBy(o => -o.Count()) //order by reversed count
.Select( s => new { s.Key, V = s.Count() }) //select value and count
.Dump(); //write to screen (LinQPad)
PHP - 84 bytes
<?$a=array_count_values(preg_split('/[_\W]+/',$argv[1],0,1));arsort($a);print_r($a);
Input is accepted as a command line argument, e.g.:
$ php count-words.php "This is a text and a number: 31."
Output for the sample string:
Array
(
[a] => 2
[number] => 1
[31] => 1
[and] => 1
[text] => 1
[is] => 1
[This] => 1
)
C#: 153c 144c 142c 111c 115c 118c 114c 113c
(via LINQPad in "C# Statements" mode, not including input string)
Version 1: 142c
var s = "This is a text and a number: 31."; // <- line not included in count
s.Split(s.Where(c=>!Char.IsLetterOrDigit(c)).ToArray(),(StringSplitOptions)1).GroupBy(x=>x,(k,e)=>new{s,c=e.Count()}).OrderBy(x=>-x.c).Dump();
Ungolfed:
var s = "This is a text and a number: 31.";
s.Split( // split string on multiple separators
s.Where(c => !Char.IsLetterOrDigit(c)) // get list of non-alphanumeric characters in string
.ToArray(), // (would love to get rid of this but needed to match the correct Split signature)
(StringSplitOptions)1 // integer equivalent of StringSplitOptions.RemoveEmptyEntries
).GroupBy(x => x, (k, e) => new{ s = k, c = e.Count() }) // count by word
.OrderBy(x => -x.c) // order ascending by negative count (i.e. OrderByDescending)
.Dump(); // output to LINQPad results panel
Results:
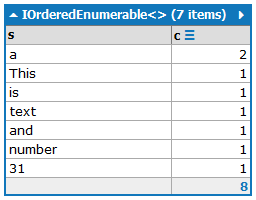
Version 2: 114c
([\w] includes _, which is incorrect!; [A-z] includes [ \ ] ^ _ `; settling on [^_\W]+)
var s = "This is a text and a number: 31."; // <- line not included in count
Regex.Matches(s, @"[^_\W]+").Cast<Match>().GroupBy(m=>m.Value,(m,e)=>new{m,c=e.Count()}).OrderBy(g=>-g.c).Dump();
Ungolfed:
Regex.Matches(s, @"[^_\W]+") // get all matches for one-or-more alphanumeric characters
.Cast<Match>() // why weren't .NET 1 collections retrofitted with IEnumerable<T>??
.GroupBy(m => m.Value, (m,e) => new{ m, c = e.Count() }) // count by word
.OrderBy(g => -g.c) // order ascending by negative count (i.e. OrderByDescending)
.Dump(); // output to LINQPad results panel
Results: (as Version 1)
Smalltalk, 91 78
input in s
(s allRegexMatches:'\w+')asBag valuesAndCountsDo:[:c :n|(c,$:)print.n printNL]
input:
pick-me-up This is a text and a number: 31.
output:
31:1
pick:1
text:1
me:1
number:1
up:1
is:1
a:2
and:1
This:1
shell utils, also 42 characters
tr -sc [:alnum:] \\n|sort|uniq -c|sort -rn
Another approach that equals Thor's answer.
Mathematica, 56 bytes
What, no Mathematica answer yet? This one is not quite a winner, but it's both concise and quite expressive:
f=SortBy[Tally@StringCases[#,WordCharacter..],-Last@#&]&
Calling f["This is a text and a number: 31."] yields
{
{"a", 2},
{"31", 1},
{"and", 1},
{"is", 1},
{"number", 1},
{"text", 1},
{"This", 1}
}
Java 8: 289
Which is pretty good, since java is a very non-golfy language.
import java.util.stream.*;class C{static void main(String[]a){Stream.of(a).flatMap(s->of(s.split("[\\W_]+"))).collect(Collectors.groupingBy(x->x,Collectors.counting())).entrySet().stream().sorted(x,y->x.getValue()-y.getValue()).forEach(e->System.out.println(e.getKey()+":"+e.getValue()));}
Ungolfed:
import java.util.stream.*;
class C {
static void main(String [] args){
Stream.of(args).flatMap(arg->Stream.of(arg.split("[\\W_]+")))
.collect(Collectors.groupingBy(word->word,Collectors.counting()))
.entrySet().stream().sorted(x,y->x.getValue()-y.getValue())
.forEach(entry->System.out.println(entry.getKey()+":"+entry.getValue()));
}
}
Run from the command line:
java -jar wordCounter.jar This is a text and a number: 31.
LiveScript - 74 (translation of ECMA one)
s.match(/[^_\W]+/g,a={})map (->-~=a[it]),keys(a)map(->[it,a[it]])sort (.1-&1.1)
Python (95):
a=sorted(raw_input().split(__import__("string").punctuation))
for i in set(a):print i,a.count(i)
Pretty straightforward, I'd say.
AWK
awk -vRS='[^A-Za-z0-9]' '$0{c[$0]++}END{for(i in c)print c[i]"\t"i": "c[i]|"sort -nr|cut -f2-"}'
Does the job without gawkish extensions:
$ echo 'This is a text and a number: 31.' | awk -vRS='[^A-Za-z0-9]' '$0{c[$0]++}END{for(i in c)print c[i]"\t"i": "c[i]|"sort -nr|cut -f2-"}'
a: 2
This: 1
text: 1
number: 1
is: 1
and: 1
31: 1
If printing "count: word" instead, it would be a bit shorter but I wanted to mimic the given example output...
Javascript - 132 126 chars !
(Shortest JS code)
o={},a=[]
for(i in s=s.split(/[\W_]+/))o[z=s[i]]=o[z]+1||1
for(j in o)a.push([j,o[j]])
a.sort(function(b,c){return c[1]-b[1]})
Improved the regex and some edits.
Ungolfed
s = s.split(/[\W_]+/), o={}, a=[]; // split along non-char letters, declare object and array
for (i in s) { n = s[i]; o[n] = o[n] + 1 || 1 } // go through each char and store it's occurence
for (j in o) a.push( [j, o[j]] ); // store in array for sorting
a.sort(function (b, c){ return c[1] - b[1]; }); // sort !
<= // make s = "How shiny is this day is isn't is"
=> [ [ 'is', 3 ],
[ 'How', 1 ],
[ 'shiny', 1 ],
[ 'this', 1 ],
[ 'day', 1 ],
[ 'isn', 1 ],
[ 't', 1 ] ]
Old - 156 143 141 140 132 chars
s=s.split(/[^\w]+/g),o={}
for(i in s){n=s[i];o[n]=o[n]+1||1}a=[]
for(j in o)a.push([j,o[j]])
a.sort(function(b,c){return c[1]-b[1]})
Gave a first try at golfing. Feedback appreciated.
Pure Bash (no external programs), 164
This is longer than I'd hoped, but I wanted to see if the necessary counting and sorting (in the right direction) could be done purely with bash arrays (associative and non-associative):
declare -A c
for w in ${@//[[:punct:]]/ };{ ((c[$w]++));}
for w in ${!c[@]};{ i=${c[$w]};((m=i>m?i:m));s[$i]+=$w:;}
for((i=m;i>0;i--));{ printf "${s[i]//:/:$i
}";}
Save as a script file, chmod +x, and run:
$ ./countoccur This is a text and a number: 31. a:2 and:1 number:1 text:1 31:1 is:1 This:1 $
grep and coreutils 44 42
grep -io '[a-z0-9]*'|sort|uniq -c|sort -nr
Test:
printf "This is a text and a number: 31." |
grep -io '[a-z0-9]*'|sort|uniq -c|sort -nr
Results in:
2 a
1 This
1 text
1 number
1 is
1 and
1 31
Update
- Use case-insensitive option and shorter regex. Thanks Tomas.
Powershell: 57 55 53 62 57
(not including input string)
$s = "This is a text and a number: 31." # <-- not counting this line...
[Regex]::Matches($s,"[^_\W]+")|group -ca|sort{-$_.Count}
returns:
Count Name Group
----- ---- -----
2 a {a, a}
1 and {and}
1 31 {31}
1 number {number}
1 This {This}
1 is {is}
1 text {text}
(with props to @microbian for group -ca)
Clojure
(defn wc [s]
(let [mc #(assoc % %2 (inc (get % %2 0)))]
(sort-by #(- (val %))
(reduce mc {} (re-seq #"\w+" (.toLowerCase s))))))
example:
(wc "hi mom hi dad hello peter hello dad hi")
;; (["hi" 3] ["hello" 2] ["dad" 2] ["peter" 1] ["mom" 1])
q (50)
desc count each group" "vs ssr[;"[^0-9A-Za-z]";" "]
- ssr replaces non alphanumeric
- " "vs splits the result into a symbol list
- count each group counts creates a dict matching distinct elements of the list with the number of occurances
- desc sorts the dict by descending values
edit: fixed accidentally matching ascii 58-64 and 91-96
Haskell (153 = 104 code + 49 import)
Pretty straight-forward, totally composed function... no argument even necessary! This is my first golf, so go easy, maybe? :)
import Data.Char
import Data.List
import Data.Ord
so=reverse.(sortBy$comparing snd).(map(\t@(x:_)->(x,length t))).group.sort.(map$filter isAlphaNum).words
Output:
*Main> so "This is a text and a number: 31."
[("a",2),("text",1),("number",1),("is",1),("and",1),("This",1),("31",1)]
Javascript (135)
u=/\w+/g
for(i=s.length;i--;)for(w in a=s.match(u))u[w=a[w]]=u[w]||a.reduce(function(p,c){return p+=w==c},0)==i&&!console.log(w+":"+i)
Unminified:
u=/\w+/g;for (i=s.length;i--;)
for(w in a=s.match(u))
u[w=a[w]] = u[w] ||
a.reduce(function(p,c){return p+=w==c},0)==i && !console.log(w+":"+i)
Loops over every possible number of matches in descending order, and outputs words with that number of occurrences. Just to be horrible.
Notes: Alert would have reduced the length some. Strictly speaking alphanumeric should be [^\W_]
GNU awk + coreutils: 71 69
gawk 'BEGIN{RS="\\W+"}{c[$0]++}END{for(w in c)print c[w],w}'|sort -nr
Although gawk asort works on associative arrays, it apparently does not preserve the index values, necessitating the external sort
printf "This is a text and a number: 31." |
gawk 'BEGIN{RS="\\W+"}{c[$0]++}END{for(w in c)print c[w],w}'|sort -nr
2 a
1 This
1 text
1 number
1 is
1 and
1 31
GNU awk 4.x: 100 93
A slightly larger but pure gawk solution using PROCINFO to set the default sort order for the associative array (appears to require a relatively recent gawk - > 4.x?)
BEGIN{RS="\\W+";PROCINFO["sorted_in"]="@val_num_desc"}
{c[$0]++}
END{for(w in c)print c[w],w}
Perl 69
$h{$_}++for<>=~/\w+/g;print"$_: $h{$_}
"for sort{$h{$b}-$h{$a}}keys%h
Added recommendations from @primo and @protist
J, 35+?
(~.(([\:]);]\:]),.@(+/"1@=))@(>@;:)
Doesn't fully work though. Problem is that the splitting into words ';:' monad doesn't handle non-alplanumeric characters in quite the right way. Any suggestions?
Here's how you use it:
(~.(([\:]);]\:]),.@(+/"1@=))@(>@;:) 'This is a text and a number: 31.'
┌───────┬─┐
│a │2│
│This │1│
│is │1│
│text │1│
│and │1│
│number:│1│
│31. │1│
└───────┴─┘
k [71 chars]
f:{s:" ",x;`_k!m@k:|(!m)@<.:m:#:'=`$1_'(&~((),/:s)like"[a-zA-Z0-9]")_s}
Any other character except alphanumeric chars will be considered as delimiter.
example
f "This is a text and a number: 31."
a | 2
31 | 1
number| 1
and | 1
text | 1
is | 1
This | 1
example
f "won't won won-won"
won| 4
t | 1
JAVA CODE
String s="This is a text and a number: 31";
String[] stringArray = s.split(" ");
final Map<String, Integer> counter = new HashMap<String, Integer>();
for (String str : stringArray)
counter.put(str, 1 + (counter.containsKey(str)counter.get(str): 0));
List<String> list = new ArrayList<String>(counter.keySet());
Collections.sort(list, new Comparator<String>() {
@Override
public int compare(String x, String y) {
return counter.get(y) - counter.get(x);
}
});
list.toArray(new String[list.size()]);
for (String str : list) {
int frequency = counter.get(str);
System.out.println(str + ":" + frequency);
}
OUTPUT
a:2
text:1
is:1
31:1
number::1
This:1
and:1
JavaScript 160 144 (Edited: to meet requirements)
f=Function;o={};s.replace(/\w+/g,f('a','o[a]=++o[a]||1'));Object.keys(o).sort(f('b,c','return o[c]-o[b]')).map(f('k','console.log(k+" "+o[k])'))
Unminified:
f=Function;
o = {};
s.replace(/\w+/g, f('a','o[a]=++o[a]||1'));
Object.keys(o).sort(f('b,c', 'return o[c]-o[b]')).map(f('k','console.log(k+" "+o[k])'))
Logs each word to console in order, passing the following string:
s="This is sam}}ple text 31to test the effectiveness of this code, you can clearly see that this is working-as-intended, but you didn't doubt it did you?.";
Outputs:
you 3
this 2
is 2
can 1
text 1
31to 1
test 1
the 1
effectiveness 1
of 1
This 1
code 1
sam 1
ple 1
clearly 1
see 1
that 1
working 1
as 1
intended 1
but 1
didn 1
t 1
doubt 1
it 1
did 1
I don't have the heart to use alert().
Python 101 97
import re
a=re.split('[_\W]+',input())
f=a.count
for w in sorted(set(a),key=f)[::-1]:print w,f(w)
Now works with newline:
$ python countword.py <<< '"This is a text and a number: 31, and a\nnewline"'
a 3
and 2
31 1
number 1
newline 1
is 1
text 1
This 1
Python3 (244 bytes)
import re, collections as c, sys
t=''
with open(sys.argv[1]) as f:
t+=f.read()
d=c.Counter([s for s in (re.sub('[\s\W]','\n',t).split('\n')) if s])
for x in sorted(d.items(), key=lambda x: x[1])[::-1]:
print('{}:{}'.format(x[0],x[1]))
Works also with newlines, tabs etc. in the sample text.
Output
> $ python3 wc.py test.txt
a:2
text:1
is:1
This:1
and:1
number:1
31:1
Python - 95 ( now 87 thanks to @primo)
d=__import__('re').findall(r'\w+',raw_input())
print sorted(map(lambda y:(y,d.count(y)),d))
Sample input :
'This is a text and a number: 31'
Sample output :
[('This', 1),('is', 1), ('a', 2),('text', 1),('and', 1),('a', 2),('number', 1),('31', 1)]
Any improvement sugestion would be appreciated
F# - 169
let f s=(s+"").Split(set s-set(['a'..'z']@['A'..'Z']@['0'..'9'])|>Set.toArray)|>Seq.where((<>)"")|>Seq.countBy id|>Seq.sortBy((~-)<<snd)|>Seq.iter((<||)(printfn"%s:%d"))
Degolfed:
let count (s : string) =
s.Split (set s - set (['a'..'z']@['A'..'Z']@['0'..'9']) |> Set.toArray)
|> Seq.where ((<>) "")
|> Seq.countBy id
|> Seq.sortBy ((~-) << snd)
|> Seq.iter ((<||) (printfn "%s:%d"))
Output when called from fsi:
> "This is a text and a number: 31." |> f
a:2
This:1
is:1
text:1
and:1
number:1
31:1
val it : unit = ()
Update: Some explanation as requested in the comments.
Uses set functions to generate an array of non alphanumeric characters in the input to pass to String.Split, then uses sequence functions to filter out empty strings, generate word counts and print the result.
Some golfing tricks: Adds an empty string to the function argument s to force type inference of the argument as a string rather than explicitly declaring the type. Uses Seq.where rather than Seq.filter to save a few characters (they are synonyms). Mixes forward pipe and ordinary function application in an attempt to minimize characters. Uses currying and (op) syntax to treat <> ~- and <|| operators as regular functions to avoid declaring lambdas to filter empty strings, sort by descending count and print tuples.
perl6: 49 characters
.say for get.comb(/\w+/).Bag.pairs.sort(-*.value)
Comb input for stuff matching \w+, put resulting list of words in a Bag, ask for their pairs and sort them by negative value. (The * is a Whatever star, it's not multiplication here)
output:
"a" => 2
"This" => 1
"is" => 1
"text" => 1
"and" => 1
"number" => 1
"31" => 1
JavaScript (ES5), 146
F=Function;a={};r="return ";b="b";x=prompt().match(/\w+/g);alert(""+x.filter(F(b,r+"!~(a[b]=~-a[b])")).map(F(b,r+"-a[b]+':'+b")).sort().reverse())
=>| This is a text and a number: 31.
<=| 2:a,1:text,1:number,1:is,1:and,1:This,1:31
C# (332)
This is my original program after excluding white spaces. Please pardon me if I did mistake in counting
using System;
using System.Collections.Generic;
using System.Linq;
class P
{
static void Main(String[] A)
{
Dictionary<string,int> D=new Dictionary<string,int>();
foreach(string s in A)
{
if(!D.ContainsKey(s))
D.Add(s,1);
else D[s]+= 1;
}
foreach(KeyValuePair<string,int> i in D.OrderByDescending(k=>k.Value))
Console.WriteLine(i.Key+":" + i.Value);
}
}
This is program with lots of character saving after suggestions from my dear friend jimbobmcgee
using System;
using System.Collections.Generic;
using System.Linq;
class P
{
static void Main(string[] A)
{
var D = new Dictionary<string, int>();
foreach (var v in A)
{
if (!D.ContainsKey(v))
D[v] = 1;
else D[v] += 1;
}
foreach (var v in D.OrderBy(k=>-k.Value))
{
Console.WriteLine(v.Key+": "+v.Value);
}
}
}
Output

PowerShell (40)
$s -split"\W+"|group -ca|sort count -des
$s is a variable that contains the input string.
Python 3 - 76
The requirement of splitting on non-alphanumeric chars unfortunately extends the code by 19 chars. The output of the following is shown correctly. If you are not sure, add a .most_common() after the .Counter(...).
i=__import__
print(i('collections').Counter(i('re').findall('\w+',input())))
In/Output
Given the input of This is a text and a number: 31. you get following output:
Counter({'a': 2, 'is': 1, 'This': 1, 'and': 1, '31': 1, 'number': 1, 'text': 1})
I tried it with other values like
1 2 3 4 5 6 7 8 2 1 5 3 4 6 8 1 3 2 4 6 1 2 8 4 3 1 3 2 5 6 5 4 2 2 4 2 1 3 6
to ensure, the output-order does not rely on the key's value/hash. This example produces:
Counter({'2': 8, '3': 6, '1': 6, '4': 6, '6': 5, '5': 4, '8': 3, '7': 1})
But as I said, print(i('collections').Counter(i('re').findall('\w+',input())).most_common()) would return the results as an definitly ordered list of tuples.
Python 3 - 57 (if a space would be enough for splitting :P)
print(__import__('collections').Counter(input().split()))
Haskell - 137
import Data.List
count text=let textS=(words(text\\".-\':")) in (sortBy (\(_,n) (_,m) -> compare m n)).nub$map(\t->(t,(length.(filter(==t)))textS)) textS
Groovy 77 82
changed regex from [^\w]+ to [^\d\p{L}]+ in order to solve problem with underscore
String s = 'This is a text and a number: 31'
def a=s.split(/[^\d\p{L}]+/)
a.collectEntries{[it, a.count(it)]}.sort{-it.value}
without first line, 82 characters
output:
[a:2, This:1, is:1, text:1, and:1, number:1, 31:1]
Ruby 58 82 65
h=Hash.new 0
gets.scan(/[\d\w]+/){h[$&]+=1}
p *h.sort_by{|k,v|-v}
Test run:
$ ruby counttext.rb <<< "This is a text and a number: 31."
["a", 2]
["text", 1]
["This", 1]
["is", 1]
["and", 1]
["number", 1]
["31", 1]
Edit 58->80: Ok, I was way off. I forgot to sort the words by occurrences. Also, Array#uniq is not an enumerator, but uses a given block to compare elements, so passing puts to it didn't filter out duplicates (not that it says that we should).
EcmaScript 6
Version 1 (108 characters)
s.split(_=/[^a-z\d]/i).map(x=>_[x]=-~_[x]);keys(_).sort((a,b)=>_[a]<_[b]).map(x=>x&&console.log(x+':'+_[x]))
Version 2 (102 characters)
s.split(_=/[^a-z\d]/i).map(x=>_[x]=-~_[x]);keys(_).sort((a,b)=>_[a]<_[b]).map(x=>x&&alert(x+':'+_[x]))
Version 3 (105 characters)
s.match(_=/\w+/g).map(x=>_[x]=-~_[x]);alert(keys(_).sort((a,b)=>_[a]<_[b]).map(x=>x+':'+_[x]).join('\n'))
Version 4 (94 characters)
s.match(_=/\w+/g).map(x=>_[x]=-~_[x]);keys(_).sort((a,b)=>_[a]<_[b]).map(x=>alert(x+':'+_[x]))
Version 5 (without alert; 87 characters)
s.match(_=/\w+/g).map(x=>_[x]=-~_[x]);keys(_).sort((a,b)=>_[a]<_[b]).map(x=>x+':'+_[x])
Version 6 (100 characters)
keys(_,s.match(_=/\w+/g).map(x=>_[x]=-~_[x])).sort((a,b)=>_[a]<_[b]).map(x=>console.log(x+':'+_[x]))
Output:
a:2
31:1
This:1
is:1
text:1
and:1
number:1
EcmaScript 6, 115 100 87 (without prompt&alert)
Thanks to @eithedog:
s.match(/\w+/g,a={}).map(w=>a[w]=-~a[w]),keys(a).map(w=>[w,a[w]]).sort((a,b)=>b[1]-a[1])
With prompt and alert (100):
prompt(a={}).match(/\w+/g).map(w=>a[w]=-~a[w]);alert(keys(a).map(w=>[w,a[w]]).sort((a,b)=>b[1]-a[1]))
Run it in Firefox.
R, 58 char
sort(table(unlist(strsplit(scan(,""),"[[:punct:]]"))),d=T)
Usage:
sort(table(unlist(strsplit(scan(,""),"[[:punct:]]"))),d=T)
1: This is a text and a number: 31.
9:
Read 8 items
a 31 and is number text This
2 1 1 1 1 1 1
Python 2.X (108 - Characters)
print'\n'.join('{}:{}'.format(a,b)for a,b in __import__("collections").Counter(raw_input().split()).items())
Python 3.X (106 - Characters)
print('\n'.join('{}:{}'.format(a,b)for a,b in __import__("collections").Counter(input().split()).items())
APL (57)
⎕ML←3⋄G[⍒,1↓⍉G←⊃∪↓Z,⍪+⌿∘.≡⍨Z←I⊂⍨(I←⍞)∊⎕D,⎕A,⎕UCS 96+⍳26;]
e.g.
⎕ML←3⋄G[⍒,1↓⍉G←⊃∪↓Z,⍪+⌿∘.≡⍨Z←I⊂⍨(I←⍞)∊⎕D,⎕A,⎕UCS 96+⍳26;]
This is a text and a number: 31.
a 2
This 1
is 1
text 1
and 1
number 1
31 1
Explanation:
⎕D,⎕A,⎕UCS 96+⍳26: numbers, uppercase letters, lowercase letters(I←⍞)∊: read input, store inI, see which ones are alphanumericZ←I⊂⍨: splitIin groups of alphanumeric characters, store inZ+⌿∘.≡⍨Z: for each element inZ, see how often it occursZ,⍪: match each element inZpairwise with how many times it occursG←⊃∪↓: select only the unique pairs, store inG⍒,1↓⍉G: get sorted indices for the occurrencesG[...;]: reorder the lines ofGby the given indices