| Bytes | Lang | Time | Link |
|---|---|---|---|
| 023 | Uiua | 241210T055553Z | Adelie |
| 048 | Zsh | 241212T093915Z | roblogic |
| 013 | Japt m | 180327T111349Z | Shaggy |
| 012 | Jelly | 180327T175301Z | Erik the |
| 027 | K4 | 180328T214727Z | mkst |
| 060 | JavaScript Node.js | 180327T142721Z | DanielIn |
| 012 | APL Dyalog | 180327T115853Z | Uriel |
| 124 | Google Sheets | 180327T221536Z | Engineer |
| 027 | J | 180327T180826Z | Galen Iv |
| 094 | C gcc | 180328T095543Z | gastropn |
| 042 | Ruby | 180327T122900Z | Kirill L |
| 020 | CJam | 180328T055758Z | Marcos |
| 013 | MATL | 180327T123336Z | Luis Men |
| 047 | Haskell | 180327T225314Z | xnor |
| 085 | ShellUtils | 180327T203628Z | CSM |
| 094 | Red | 180327T173651Z | Galen Iv |
| 030 | Perl 5 n | 180327T170824Z | Ton Hosp |
| 026 | Retina | 180327T162515Z | Neil |
| 008 | Stax | 180327T161148Z | recursiv |
| 058 | JavaScript | 180327T154419Z | Shaggy |
| 014 | Pyth | 180327T150956Z | user4854 |
| 085 | SNOBOL4 CSNOBOL4 | 180327T143901Z | Giuseppe |
| 033 | Perl 5 pl | 180327T142229Z | Xcali |
| 095 | Javascript | 180327T141757Z | Luis fel |
| 013 | SOGL V0.12 | 180327T133634Z | dzaima |
| 075 | R | 180327T115424Z | Giuseppe |
| 051 | Haskell | 180327T105738Z | totallyh |
| 064 | Python 3 | 180327T115449Z | Jo King |
| 049 | Haskell | 180327T125402Z | Laikoni |
| 159 | C gcc | 180327T124747Z | Jonathan |
| 053 | Java 8 | 180327T120024Z | Kevin Cr |
| 013 | 05AB1E | 180327T105856Z | Adnan |
| 035 | Perl 6 | 180327T114833Z | nwellnho |
| 033 | APL+WIN | 180327T114029Z | Graham |
| 013 | 05AB1E | 180327T110051Z | Emigna |
Uiua, 24 23 bytesSBCS
⍚(↘1⊏×°⊏⊸∊:⊂" -"+@0⇡10)
Input and output are a box array of strings. Try it online!
Explanation
⍚(↘1⊏×°⊏⊸∈:⊂" -"+@0⇡10) # Main bind
⍚( ) # For each boxed string, unbox it and do the following, reboxing it after:
⊂" -"+@0⇡10 # Build the string " -0123456789", call it D
⊸∈: # Check which chars in D appear in the input string,
# keeping D below the resulting array on the stack;
# chars in both are denoted with 1, and those that are not with 0
°⊏ # Push an array of 0-based indices of the array in ascending order
× # Multiply both arrays
⊏ # Select chars in D with the array; 0 becomes " ", 1 becomes "-", etc.
↘1 # Drop the leading space
Zsh, 50 48 bytes
for i;{for j (- {0..9})printf ${j/[^$i]/ };echo}
For each argument i we loop j over [-0123456789] and if j has a match in i, we printf $j. Or, replace a non-matched character with a space.
Japt -m, 16 13 bytes
I/O as an array of strings.
Ao ¬i- ËoU ú1
Ao ¬i- ËoU ú1 :Implicit map of each U in input array
A :10
o :Range [0,A)
¬ :Join
i- :Prepend "-"
Ë :Map
oU : Remove characters not contained in U
ú1 : Right pad with spaces to length 1
Jelly, 12 bytes
ØD”-;¹⁶e?€Ʋ€
-2 thanks to Jonathan Allan reading a rule I didn't.
Note that the I/O format used in the TIO link is not the actual one, which is input as a list of string representations and output as a list of lines.
K4, 30 27 bytes
Solution:
{?[a in$x;a:"-",.Q.n;" "]}'
Example:
q)k){?[a in$x;a:"-",.Q.n;" "]}'1 729 4728510 -3832 748129321 89842 -938744 0 11111
" 1 "
" 2 7 9"
" 012 45 78 "
"- 23 8 "
" 1234 789"
" 2 4 89"
"- 34 789"
" 0 "
" 1 "
Explanation:
Return "-0123..." or " " based on the input. Interpreted right-to-left. No competition for the APL answer :(
{?[a in$x;a:"-",.Q.n;" "]}' / the solution
{ }' / lambda for each
?[ ; ; ] / if[cond;true;false]
.Q.n / string "0123456789"
"-", / join with "-"
a: / save as a
$x / convert input to string
a in / return boolean list where each a in x
" " / whitespace (return when false)
JavaScript (Node.js), 60 bytes
- Thank to @Andrew Taylor for reducing the join (8 chars)
- Thank to @Yair Rand for X.match (8 chars)
a=>a.map(X=>"-0123456789".replace(/./g,x=>X.match(x)?x:" "))
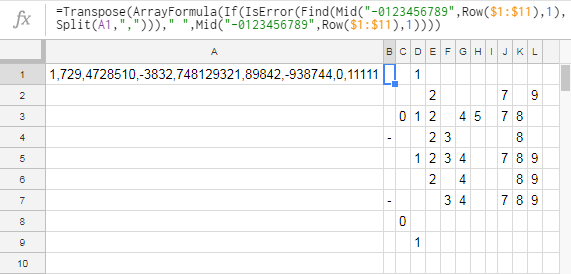
Google Sheets, 124 bytes
=Transpose(ArrayFormula(If(IsError(Find(Mid("-0123456789",Row($1:$11),1),Split(A1,",")))," ",Mid("-0123456789",Row($1:$11),1
Input is a comma-separated list in cell A1. Output is in the range B1:L? where ? is however many entries were input. (You can put the formula wherever you want, I just chose B1 for convenience.) Note that Sheets will automatically add four closing parentheses to the end of the formula, saving us those four bytes.
Another test case and another test case
{kind=link}
{kind=link}
Explanation:
Mid("-0123456789",Row($1:$11),1)picks out each of the 11 characters in turn.Find(Mid(~),Split(A1,","))looks for those characters in each of the input elements. This either returns a numeric value or, if it's not found, an error.If(IsError(Find(~)," ",Mid(~))will return a space if the character wasn't found or the character if it was. (I wish there was a way to avoid duplicating theMid(~)portion but I don't know of one.)ArrayFormula(If(~))is what makes the multi-cell references inMid(~)andFind(~)work. It's also what makes a formula in one cell return values in multiple cells.Transpose(ArrayFormula(~))transpose the returned array because it starts off sideways.
J, 32 27 bytes
-5 bytes thanks to FrownyFrog!
10|.":(10<."."0@[)}11$' '"0
Original solution:
J, 32 bytes
(('_0123456789'i.[)}11$' '"0)@":
Explanation:
@": convert to characters and
}11$' '"0 change the content of an array of 11 spaces to these characters
'_0123456789'i.[ at the places, indicated by the indices of the characters in this list
C (gcc), 95 94 bytes
c,d;f(l,n)char**l;{for(;n--;l++)for(c=0;c<12;)putchar(strchr(*l,d=c++?c+46:45)?d:d^58?32:10);}
Input in the form of a list of strings. Output to STDOUT.
Ruby, 42 bytes
Anonymous lambda processing the array of numbers:
->a{a.map{|n|"-0123456789".tr"^#{n}",?\s}}
Alternatively, a completely Perl-like full program is much shorter. I'd say -pl switches look quite funny in this context:
Ruby -pl, 29 bytes
$_="-0123456789".tr"^#$_"," "
Finally, the following is possible if it is acceptable for the output strings to be quoted:
Ruby -n, 27 bytes
p"-0123456789".tr ?^+$_,?\s
CJam, 20 bytes
qS%{'-10,+s_@-SerN}/
Accepts input as space separated list of integers. Pretty much the same approach as @adnans answer.
MATL, 13 bytes
"45KY2ht@gm*c
Input is a cell array of strings. Try it online! Or verify all test cases.
Explanation
% Implicit input: cell array of strings, for example {'1','729',...,'11111'}
" % For each cell
45 % Push 45 (ASCII code of '-')
KY2 % Push predefined literal '0123456789'
h % Concatenate horizontally: gives '-0123456789'
t % Duplicate
@ % Push current cell, for example {'729'}
g % Convert cell to matrix. This effectively gives the cell's contents, '729'
m % Ismember: gives an array of zeros and ones indicating membership of each
% char from '-0123456789' in '729'. The result in the example is
% [0 0 0 1 0 0 0 0 1 0 1]
* % Multiply, element-wise. Chars are implicity converted to ASCII
% Gives the array [0 0 0 50 0 0 0 0 55 0 57]
c % Convert ASCII codes to chars. 0 is displayed as space. Gives the string
% ' 2 7 9'
% Implicit end
% Implicilly display each string on a different line
Haskell, 47 bytes
map(\s->do d<-"-0123456789";max" "[d|elem d s])
Uses max to insert a space where no element exist, since a space is smaller than any digit or minus sign.
If an ungodly number of trailing spaces is OK, two bytes can be saved:
45 bytes
map(\s->do d<-'-':['0'..];max" "[d|elem d s])
ShellUtils, 85 bytes
There must be a better way of escaping the {} rather than using a double echo and piping through bash
xargs -i echo echo \\-0123456789 \|tr \$\(echo .0123456789- \|tr -d -- {} \) \' \'|sh
This takes the strings, one per line, from stdlin The inner tr takes -0123456789 and removes what's not in the input line. The {} represents this.
The second tr takes that output, and converts -0123456789 by replacing the input characters with spaces.
Red, 94 bytes
func[b][foreach a b[s: copy" "foreach c a[s/(index? find"-0123456789"c): c]print s]]
Takes input as a block of strings
Perl 5 -n, 30 bytes
Wouldn't work if - could appear anywhere else than in the first position
#!/usr/bin/perl -n
say"-0123456789"=~s/[^$_]/ /gr
Retina, 26 bytes
%"-0123456789"~`.+
[^$&]¶
Try it online! Note: Trailing space. Explanation: % executes its child stage ~ once for each line of input. ~ first executes its child stage, which wraps the line in [^ and ]<CR><SP>, producing a program that replaces characters not in the line with spaces. The "-0123456789" specifies that the input to that program is the given string ($ substitutions are allowed but I don't need them).
Stax, 8 bytes
║V≡u╝─é╢
It takes one number per line on standard input. It works by finding the target index of each character and assigning it into that index of the result. If the index is out of bounds, the array is expanded with zeroes until it fits. During output, 0 becomes a space. The rest are character codes.
Unpacked, ungolfed, and commented, this is what it looks like.
m for each line of input, execute the rest of the program and print the result
zs put an empty array under the line of input
F for each character code in the line of input, run the rest of the program
Vd "0123456789"
I^ get the index of the character in this string and increment
_& assign this character to that index in the original string
JavaScript, 59 58 bytes
Input & output as an array of strings.
a=>a.map(x=>`-0123456789`.replace(eval(`/[^${x}]/g`),` `))
Try it
o.innerText=(g=s=>(f=
a=>a.map(x=>`-0123456789`.replace(eval(`/[^${x}]/g`),` `))
)(s.split`,`).join`\n`)(i.value="1,729,4728510,-3832,748129321,89842,-938744,0,11111");oninput=_=>o.innerText=g(i.value)input{width:100%;}<input id=i><pre id=o></pre>Original
Takes input as an array of strings and outputs an array of character arrays
a=>a.map(x=>[...`-0123456789`].map(y=>-~x.search(y)?y:` `))
o.innerText=(g=s=>(f=
a=>a.map(x=>[...`-0123456789`].map(y=>-~x.search(y)?y:` `))
)(s.split`,`).map(x=>x.join``).join`\n`)(i.value="1,729,4728510,-3832,748129321,89842,-938744,0,11111");oninput=_=>o.innerText=g(i.value)input{width:100%;}<input id=i><pre id=o></pre>Pyth, 14 bytes
VQm*d}dNs+\-UT
Takes input as list of strings and outputs a list of strings for each line.
Try it here
Explanation
VQm*d}dNs+\-UT
VQ For each string in the input...
m s+\-UT ... and each character in "-0123456789"...
}dN ... check if the character is in the string...
*d ... and get that character or an empty string.
SNOBOL4 (CSNOBOL4), 85 bytes
I X =INPUT :F(END)
S ='-0123456789'
R S NOTANY(X ' ') =' ' :S(R)
OUTPUT =S :(I)
END
I X =INPUT :F(END) ;* read input, if none, goto end
S ='-0123456789' ;* set the string
R S NOTANY(X ' ') =' ' :S(R) ;* replace characters of S not in X + space with space
OUTPUT =S :(I) ;* print S, goto I
END
Javascript 95 bytes
(a,t='-0123456789')=>a.map(a=>a+'').map(_=>[...t].map(b=>_.search(b)>=0?b:' ').join``).join`\n`
f=(a,t='-0123456789')=>a.map(a=>a+'').map(_=>[...t].map(b=>_.search(b)>=0?b:' ').join``).join`\n`
console.log(f([1,729,4728510,-3832,748129321,89842,-938744,0,11111]))
console.log(f([4,534,4,4,53,26,71,835044,-3559534,-1027849356,-9,-99,-3459,-3459,-94593,-10234567859]))SOGL V0.12, 14 13 bytes
{ø,{²²⁴WI1ž}P
Explanation:
{ø,{²²⁴WI1ž}P
{ repeat input times
ø, push an empty string and the next input above that
{ } for each character in the input
²² push "0123456789"
⁴ copy the character on top
W and get it's index in that string (1-indexed, 0 for the non-existent "-")
I increment that (SOGL is 1-indexed, so this is required)
1ž at coordinates (index; 1) in the string pushed earlier, insert that original copy of the character
P print the current line
R, 96 75 bytes
for(i in scan())cat(paste(gsub(paste0("[^",i,"]")," ","-0123456789"),"\n"))
Thanks to Kevin Cruijssen for suggesting this regex approach!
Takes input from stdin as whitespace separated integers, and prints the ascii-art to stdout.
Haskell, 51 bytes
-1 byte thanks to Laikoni.
f l=[[last$' ':[n|n`elem`i]|n<-"-0123456789"]|i<-l]
This challenge is digitist. D:
Python 3, 77 64 bytes
-12 bytes thanks to @Rod
lambda x:[[[" ",z][z in str(y)]for z in"-0123456789"]for y in x]
My first proper attempt at golfing in Python. Advice welcome!
Returns a 2D array of characters.
Haskell, 49 bytes
map$(<$>"-0123456789").(%)
i%n|elem n i=n|1<3=' '
The first line defines an anonymous function which takes a list of strings and returns a list of strings. Try it online!
C (gcc), 159 bytes
f(A,l,j,k,b)long*A,k;{char*s,S[99];for(j=~0;++j<l;puts(""))for(sprintf(S,"%ld",k=A[j]),putchar(k<0?45:32),k=47;++k<58;putchar(b?32:k))for(b=s=S;*s;b*=*s++-k);}
Java 8, 53 bytes
a->a.map(i->"-0123456789".replaceAll("[^"+i+"]"," "))
My own challenge is easier than I thought it would be when I made it..
Input and output both as a java.util.stream.Stream<String>.
Explanation:
a-> // Method with String-Stream as both input and return-type
a.map(i-> // For every String in the input:
"-0123456789" // Replace it with "-0123456789",
.replaceAll("[^"+i+"]"," ")) // with every character not in `i` replaced with a space
05AB1E, 13 bytes
Code:
v'-žh«DyмSð:,
Uses the 05AB1E encoding. Try it online!
Explanation:
v # For each element in the input..
'-žh« # Push -0123456789
D # Duplicate this string
yм # String subtraction with the current element
e.g. "-0123456789" "456" м → "-0123789"
Sð: # Replace all remaining elements with spaces
e.g. "-0123456789" "-0123789" Sð: → " 456 "
, # Pop and print with a newline
Perl 6, 35 bytes
{.map:{map {m/$^a/||' '},'-',|^10}}
Output is a character matrix containing either regex matches or space characters.
APL+WIN, 33 bytes
Prompts for screen input as a string
n←11⍴' '⋄n['-0123456789'⍳s]←s←⎕⋄n
05AB1E, 17 13 bytes
Saved 4 bytes thanks to Adnan
vðTúyvyÐd+ǝ},
Explanation
v # loop over elements y in input
ðTú # push a space prepended by 10 spaces
yv # for each element y in the outer y
y # push y
Ðd+ # push y+isdigit(y)
ǝ # insert y at this position in the space-string
} # end inner loop
, # print