| Bytes | Lang | Time | Link |
|---|---|---|---|
| 146 | Clojure | 240919T180451Z | Martin P |
| 017 | Uiua | 240314T004930Z | noodle p |
| 110 | Swift | 240314T003242Z | macOSist |
| 097 | Zsh | 221228T024930Z | roblogic |
| 133 | Haskell | 180319T014842Z | Aearnus |
| 029 | SM83 | 210425T162033Z | NoLonger |
| 071 | Julia 1.0 | 210426T135229Z | MarcMush |
| 009 | Vyxal s | 210423T141624Z | Aaroneou |
| 6015 | MMIX | 210425T165354Z | NoLonger |
| 107 | Julia | 201030T003918Z | binaryca |
| 186 | Gameboy Z80 Assembly | 201029T221536Z | corvus_1 |
| 011 | 05AB1E legacy | 200306T145147Z | Grimmy |
| 256 | Clojure | 200306T143719Z | Attilio |
| 066 | C gcc | 200305T190347Z | S.S. Ann |
| 225 | Forth | 190810T051534Z | nonForgi |
| 082 | Julia 1.0 | 190808T143222Z | Simeon S |
| 110 | Python 3 | 190808T034727Z | Kuldeep |
| 131 | C | 180316T094914Z | ErikF |
| 137 | Lua 5.3 | 181026T154543Z | David |
| nan | Lua | 180726T074335Z | Visckmar |
| 020 | MATL | 180709T233316Z | Sundar R |
| 079 | Javascript ES6 | 180319T061803Z | Yair Ran |
| 082 | JavaScript ES6 | 180314T182945Z | Rick Hit |
| 031 | x8664 | 180409T064528Z | Ian Chew |
| 049 | K4 | 180408T192638Z | mkst |
| 129 | ><> | 180408T120720Z | SE - sto |
| 115 | Excel VBA | 180316T033908Z | Taylor R |
| 022 | Pip | 180320T231549Z | DLosc |
| 094 | Haskell | 180319T143947Z | Pharap |
| 014 | Jelly | 180314T183007Z | Erik the |
| 100 | Python 3 | 180318T183018Z | Dat |
| 029 | Perl 5 p | 180314T190737Z | Ton Hosp |
| 109 | pwsh | 180317T205808Z | lit |
| 098 | Java 8 | 180315T085506Z | Kevin Cr |
| 105 | PowerShell Core | 180317T080121Z | Tessella |
| 012 | Stax | 180314T202458Z | recursiv |
| 307 | Fortran GFortran | 180316T221932Z | rafa1111 |
| 064 | Chip | 180316T193819Z | Phlarx |
| 099 | PHP | 180314T220709Z | Ethan |
| 041 | Ruby | 180315T182531Z | benj2240 |
| 051 | 6502 machine code routine C64 | 180316T142503Z | Felix Pa |
| 092 | SNOBOL4 CSNOBOL4 | 180314T182959Z | Giuseppe |
| 075 | PHP 4 | 180316T103126Z | Christop |
| 121 | Yabasic | 180316T032910Z | Taylor R |
| 070 | Wolfram Language Mathematica | 180315T232833Z | Misha La |
| 092 | R | 180314T211645Z | Vlo |
| 040 | APL Dyalog Classic | 180315T205751Z | Adalynn |
| 016 | Japt v2.0a0 | 180314T220758Z | Shaggy |
| 017 | Retina | 180314T182727Z | mbomb007 |
| 097 | Python 3 | 180314T212455Z | Rick Ron |
| 063 | Python | 180315T131534Z | ManfP |
| 330 | Rust | 180315T114158Z | dragonit |
| 097 | Python 2 | 180315T084113Z | AvahW |
| 007 | AutoHotKey | 180315T080928Z | tsh |
| 011 | Husk | 180314T213808Z | Zgarb |
| 031 | CJam | 180315T052328Z | Marcos |
| 021 | Charcoal | 180315T004753Z | Neil |
| 072 | Python 3 | 180315T000052Z | The Fift |
| 012 | 05AB1E | 180314T210652Z | Emigna |
| 072 | C | 180314T191732Z | Steadybo |
| 016 | Vim | 180314T204506Z | Endenite |
| 015 | Husk | 180314T202405Z | ბიმო |
| 092 | Haskell | 180314T192114Z | Wheat Wi |
| 019 | Pyth | 180314T185118Z | Mr. Xcod |
| 021 | Pyth | 180314T184222Z | user4854 |
| 009 | V | 180314T182523Z | DJMcMayh |
Clojure, 146 bytes
#(clojure.string/replace % #"(?i)a([^a]*)(a|$)"(fn[[_ m]](apply str(map(fn[c](char(let[i(int c)](+(if(> 123 i 96)-32(if(> 91 i 64)32 0))i))))m))))
With spaces and test cases:
(let [f #(clojure.string/replace % #"(?i)a([^a]*)(a|$)" (fn [[_ m]] (apply str (map (fn [c] (char (let [i (int c)] (+ (if (> 123 i 96) -32 (if (> 91 i 64) 32 0)) i)))) m))))]
(every? true? [(= (f "The quick brown fox jumps over the lazy dog.") "The quick brown fox jumps over the lZY DOG.") (= (f "Compilation finished successfully.") "CompilTION FINISHED SUCCESSFULLY.") (= (f "What happens when the CapsLock key on your keyboard doesn't have a notch in it?") "WhT Hppens when the CPSlOCK KEY ON YOUR KEYBOrd doesn't hVE notch in it?") (= (f "The end of the institution, maintenance, and administration of government, is to secure the existence of the body politic, to protect it, and to furnish the individuals who compose it with the power of enjoying in safety and tranquillity their natural rights, and the blessings of life: and whenever these great objects are not obtained, the people have a right to alter the government, and to take measures necessary for their safety, prosperity and happiness.") "The end of the institution, mINTENnce, ND dministrTION OF GOVERNMENT, IS TO SECURE THE EXISTENCE OF THE BODY POLITIC, TO PROTECT IT, nd to furnish the individuLS WHO COMPOSE IT WITH THE POWER OF ENJOYING IN Sfety ND TRnquillity their nTURl rights, ND THE BLESSINGS OF LIFE: nd whenever these greT OBJECTS re not obtINED, THE PEOPLE Hve RIGHT TO lter the government, ND TO Tke meSURES NECESSry for their sFETY, PROSPERITY nd hPPINESS.") (= (f "aAaaaaAaaaAAaAa") "") (= (f "CapsLock locks cAPSlOCK") "CPSlOCK LOCKS CPSlOCK") (= (f "wHAT IF cAPSlOCK IS ALREADY ON?") "wHt if CPSlOCK IS lreDY ON?")]))
=> true
```
Uiua, 18 17 bytes
/◇⊂⍜▽¯◿2°⊏⊜□≠@A⌵.
/◇⊂⍜▽¯◿2°⊏⊜□≠@A⌵.
⌵. # Push an uppercase copy
≠@A # Mask of those not equal to A
⊜□ # Partition, boxing each string
°⊏ # Copy, push the range 0 to its length
◿2 # Modulo 2 (alternating 0s and 1s)
⍜▽¯ # At positions with 1s, swapcase
/◇⊂ # Reduce by joining each unboxed string
💎
Created with the help of Luminespire.
I don't like formatting Uiua explanations like this since it's hard to explain everything on one line (especially because I like to do pretty in-depth explanations). Particularly for Uiua it can feel awkward reading the code down and to the left while reading the explanation all the way to the right. But, there's a clear tradeoff, doing explanations this way takes much less time, and I don't have that much time right now so this'll do.
Swift, 110 bytes
import Darwin
var x=0,f={for c in($0+"").utf8{c&95==65 ?(x^=1,0).1:putchar(CInt(x>0&&66...90~=c&95 ?c^32:c))}}
f(_:) is the closure you want.
If you're on Linux instead of macOS, you can replace import Darwin with import Glibc to save a byte (and you have to do it anyway if you want it to compile). For platform independence, import Foundation can be used instead.
This is an almost direct port of @KevinCruijssen's Java answer to Swift, with:
- some things shuffled around,
- a call to
~=(lhs:rhs:)(the pattern matching operator) to condense the range check, - a tuple shenanigan to let us use the ternary conditional operator instead of
if-else, and - a bit of C interop abuse because Swift names are long.
Notes
CIntis atypealiasforInt32, the type expected byputchar(_:)(for reasons beyond my mortal comprehension; C is weird).For reasons slightly closer to a realm I can grasp (i.e. exit codes),
putchar(_:)also returns anInt32, meaning we can't directly put a call to it in a ternary conditional that expectsVoid(an alias for()), which is the result type ofx^=1(because, in Swift, assignment operators rightfully don't return anything).So, instead, I shoved
x^=1into a tuple and added0as the second element, and then accessed it with.1. This still evaluatesx^=1, but returns anInt32(the type the0literal is inferred as) rather than aVoid, which calms down the type checker a bit.The
~=(lhs:rhs:)operator is used internally for custom pattern matching (i.e.switchstatements,if case, and the like). There's an overload defined onClosedRangethat checks ifrhsis contained inlhs. We abuse that here.Because Swift really doesn't want you to do things like this with an ordinary
String, we have to access theutf8property of the input to get a[UInt8]that we can iterate over.We need to concatenate
""with$0(the implicit closure parameter, aka the input) to help the type checker figure out that$0is aString.
Zsh, 97 107 bytes
for c (${(s..)1})case $c {a|A)((j^=1));;[b-z])((j))&&c=$c:u;|[B-Z])((j))&&c=$c:l;|*)s+=$c;}
<<<$s
-10 thanks to @GammaFunction.
Try it Online!
107bytes
Haskell, 199 133 bytes
import Data.Char
l c|isUpper c=toLower c|1<2=toUpper c
f _""=""
f b(c:cs)|toLower c=='a'=f(not b)cs|1<2=(if b then l else id)c:f b cs
Run using f False "<string>"
Ungolfed version:
import Data.Char
flipCase c
| isUpper c = toLower c
| otherwise = toUpper c
f "" _ = ""
f b (c:cs)
| toLower c == 'a' = f cs $ not b
| True = (if b then flipCase else id) c:f b cs
SM83, 29 28 bytes; Z80, 30 29 bytes
- SM83 version
06 00 2A 4F CB AF D6 41
28 0C FE 1A 79 30 01 A8
12 13 B7 20 ED C9 78 EE
20 47 18 E6
- Z80 version (changes in stars)
06 00 *7D 23* 4F CB AF D6 41
28 *0E* FE 1A 79 30 *03* A8
12 13 B7 20 *EE* C9 78 EE
20 47 18 *E7*
Disassembly and explanation
fun:
ld b,0 ; 06 00 we start out in non-swapping state
loop:
#ifdef SM83
ld a,(hl+) ; 2A load character
#else
ld a,(hl) ; 7D
inc hl ; 23 Z80 doesn't have autoinc addressing
#endif
ld c,a ; 4F save copy in c
res 5,a ; CB AF Clear bit 5
sub 65 ; D6 41 subtract 'A'
jr z,is_a ; 28 0C/0E if 0, was 'A' or 'a'; handle that later
cp 26 ; FE 1A compare to 26
ld a,c ; 79 reload from copy
jr nc,put ; 30 01/03 skip next if was letter (<26)
xor b ; A8 xor in caps lock setting
put:
ld (de),a ; 12 store
inc de ; 13 and increment
or a ; B7 check if zero by self-or (cheap trick)
jr nz,loop ; 20 ED/EE loop if wasn't 0
ret ; C9 and return otherwise
is_a:
ld a,b ; 78
xor 32 ; EE 20
ld b,a ; 47 flip caps lock setting
jr loop ; 18 E6/E7 jump back to loop
Heavily based on corvus_192's answer. The differences:
- I counted bytes of machine code, not assembly
- I changed
jp(absolute jump, three bytes) tojr(relative jump, two bytes), saving five bytes - I moved the case-fold (
res 5,a) to before the test for A, saving a compare-to-constant and a jump (four more bytes saved) - This produced the sequence
cp 65; jr z,is_a; sub 65, which can be collapsed tosub 65; jr z,is_a, saving two more bytes. - It's cheaper to test if
ais 0 by executingor a(and aalso works) thancp 0; it doesn't tell you sign, but we didn't need that.
In total, these changes (well, not the counting difference) save twelve bytes from the original.
Julia 1.0, 73 71 bytes
f(s,b=0)=[c∈"aA" ? b=32-b : print(c+isletter(c)sign('_'-c)b) for c=s]
Stolen and improved from Simeon Schaub's great answer
-2 bytes thanks to Czylabson Asa
Vyxal s, 12 10 9 bytes
Saved 2 bytes by using ṡ to split the string with a regex.
Saved 1 byte by using ⁽ to define the function.
`a|A`ṡ⁽Nẇ
Explanation:
# Implicit input
`a|A`ṡ # Split string every instance 'a' OR 'A'
⁽N # Define a function that swaps the casing of strings
ẇ # Apply the function to every 2nd string
# 's' flag: concatenate top of the stack and print
MMIX, 60 bytes (15 instrs)
E3020000 83030000 E7000001
CBFF0320 25FFFF41 5AFF0003
C7020220 F1FFFFFA 33FFFF1A
48FF0002 C6030302 A3030100
E7010001 5B03FFF4 F8000000
Disassembly and explanation:
fun SETL $2,0 // E3020000: mask = 0
0H LDBU $3,$0,0 // 83030000: loop: chr = *src (src, dst are both char *)
INCL $0,1 // E7000001: src++
ANDN $255,$3,32 // CBFF0320: tmp = chr & ~32
SUB $255,$255,'A' // 25FFFF41: tmp -= 'A'
PBNZ $255,1F // 5AFF0003: iflikely(!tmp) goto nota
XOR $2,$2,32 // C7020220: mask ^= 32
JMP 0B // F1FFFFFA: goto loop
1H CMPU $255,$255,26 // 33FFFF1A: nota: tmp = tmp <=> 26
BNN $255,1F // 48FF0002: if(tmp > 0) goto notlet
XOR $3,$3,$2 // C6030302: chr ^= mask
1H STBU $3,$1,0 // A3030100: notlet: *dst = chr
INCL $1,1 // E7010001: dst++
PBNZ $3,0B // 5B03FFF4: iflikely(chr) goto loop
POP 0,0 // F8000000: return
This was heavily inspired by corvus_192's answer.
It's essentially the same algorithm, except with multiple simplifications due to MMIX's symmetric register architecture.
Julia, 107 bytes
let b=false;[c in"aA" ? b=!b : print(b&&isletter(c) ? c<'@' ? c+32 : c-32 : c) for c::Char=read(stdin)];end
The let block is unfortunate, but apperently julia's scope is broken and b is undefined otherwise.
Here's the same program but with loops instead of comprehension, and if instead of conditionals.
let b=false # whether to invert charachters
# normally this would be "for c in read(stdin,String)",
# but reading a byte array and converting the bytes to chars saves one (byte).
for c::Char in read(stdin)
if c in "aA"
b = !b
else
print(if b && isletter(c)
if c<'@' # capitalization check
c+32 # ascii code shenanigans to change case
else
c-32
end
else
c # c is not a letter or we aren't swapping
end)
end
end
end
Gameboy Z80 Assembly, 186 bytes
f:
ld b,0
l:
ld a,[hli]
ld c,a
cp 65
jp z,a
cp 97
jp z,a
res 5,a
sub 65
cp 25
ld a,c
jp nc,o
xor b
o:
ld [de],a
inc de
cp 0
jp nz,l
ret
a:
ld a,b
xor 32
ld b,a
jp l
This answer was heavily influenced by Ian Chew's x86 assembly answer.
Commented version
; input in hl
; output in de
; b is used for the caps lock state, 00000000 = no capslock, 00100000 = capslock
; a and c are used for the character
f:
ld b,0
loop:
; load a character from the input and advance the source pointer
ld a,[hli]
;save character in c
ld c,a
; check if character is 'a' or 'A'
cp 65
jp z,is_a
cp 97
jp z,is_a
; check if character is a letter by setting the 5th bit to zero and checking for the range 25..65
res 5,a
sub 65
cp 25
; load the character back from c
ld a,c
; if it is not a letter, simply output it
jp nc,output
; if it is a letter, apply the current case swap
xor b
; output the character and advance the destination pointer
output:
ld [de],a
inc de
; end of input?
cp 0
jp nz,loop
; return
ret
is_a:
; change the case swap mask by xoring with 32
ld a,b
xor 32
ld b,a
; continue the loop
jp loop
Clojure, 256 bytes
Golfed
(require[clojure.string :refer :all])(def u upper-case)(defn f[x](if(=(u x)x)(lower-case x)(u x)))(defn i[a](="A"(u a)))(defn g[x](let[v(vec(map str x))](join""(filter(complement i)(reduce-kv(fn[c k e](if(i e)(concat(take k c)(map f(drop k c)))c))v v)))))
Ungolfed
(ns acapslock.core
(:require [clojure.string :as str]))
(defn flip
[x]
(if (= (str/upper-case x) x) (str/lower-case x) (str/upper-case x)))
(defn isa
[a]
(or (= "a" a) (= "A" a)))
(defn foo
[x]
(str/join "" (filter (complement isa) (reduce-kv (fn [coll idx elem] (if (isa elem)(concat (take idx coll) (map flip (drop idx coll))) coll)) (vec (map str x)) (vec (map str x))))))
Explanation
The solution works in two steps:
First, we go through the input character by character. If we find an
aor anA, we flip the case of the rest of the string.Then we filter out all
a's andA's.
Tests
(ns acapslock.core-test
(:require [clojure.test :refer :all]
[acapslock.core :refer :all]))
(deftest a-test
(testing "test cases"
(is (= "" (foo "")))
(is (= "The quick brown fox jumps over the lZY DOG." (foo "The quick brown fox jumps over the lazy dog.")))
(is (= "CompilTION FINISHED SUCCESSFULLY." (foo "Compilation finished successfully.")))
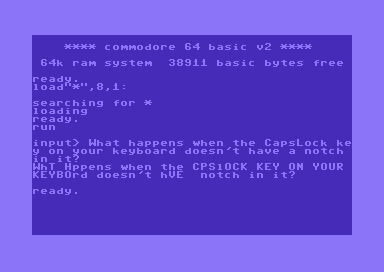
(is (= "WhT Hppens when the CPSlOCK KEY ON YOUR KEYBOrd doesn't hVE notch in it?" (foo "What happens when the CapsLock key on your keyboard doesn't have a notch in it?")))
(is (= "The end of the institution, mINTENnce, ND dministrTION OF GOVERNMENT, IS TO SECURE THE EXISTENCE OF THE BODY POLITIC, TO PROTECT IT, nd to furnish the individuLS WHO COMPOSE IT WITH THE POWER OF ENJOYING IN Sfety ND TRnquillity their nTURl rights, ND THE BLESSINGS OF LIFE: nd whenever these greT OBJECTS re not obtINED, THE PEOPLE Hve RIGHT TO lter the government, ND TO Tke meSURES NECESSry for their sFETY, PROSPERITY nd hPPINESS." (foo "The end of the institution, maintenance, and administration of government, is to secure the existence of the body politic, to protect it, and to furnish the individuals who compose it with the power of enjoying in safety and tranquillity their natural rights, and the blessings of life: and whenever these great objects are not obtained, the people have a right to alter the government, and to take measures necessary for their safety, prosperity and happiness.")))
(is (= "" (foo "aAaaaaAaaaAAaAa")))
(is (= "CPSlOCK LOCKS CPSlOCK" (foo "CapsLock locks cAPSlOCK")))
(is (= "wHt if CPSlOCK IS lreDY ON?" (foo "wHAT IF cAPSlOCK IS ALREADY ON?")))
))
C (gcc), 66 bytes
u;f(char*s){for(u=0;*s;s++)u^=6305%*s?!putchar(*s&64?*s^u:*s):32;}
Similar to another solution but doesn't use ctype functions.
-1 byte thanks to [ceilingcat]!
Forth, 225 bytes
: d DUP ; : x SWAP ; : w WITHIN ; : a d d 65 = x 97 = OR ; : y d d 65 91 w x 97 123 w OR ; : ~ INVERT ; x VALUE s 0 VALUE f : l 0 DO I s + C@ a IF f ~ TO f THEN y IF f IF 32 XOR d THEN a ~ IF EMIT THEN ELSE EMIT THEN LOOP ; l
What happening:
: d DUP ; \ shortcut for duplicating value on stack
: a d d 'A' = SWAP 'a' = OR ; \ testing, if char is 'a' or 'A'
: y d d 'A' '[' WITHIN SWAP 'a' '{' WITHIN OR ; \ testing, if char is within letters
: ~ INVERT ; \ shortcut for negation
SWAP \ swap addr and len of the string after s" command
VALUE s \ pop addr to s
0 VALUE f \ write 0 to f(lag)
: l 0 DO \ declaration of loop named 'l' from 0 to len (len is laying on top of the stack, remember)
I s + C@ \ push iteration number on stack and load char from s + iteration
\ this IF is searching for 'a' or 'A'
a IF
f ~ TO f \ if we found 'a' or 'A', then flip the f(lag)
THEN
y IF \ if char is letter
f IF \ and f is set
32 XOR d THEN \ change case of symbol
a ~ IF \ if it's not 'a' or 'A' then print char
EMIT
THEN
ELSE
EMIT \ print char
THEN
LOOP ;
l
Actually code in tio is 285 bytes, but this is because Footer didn't work for defining string, so i had to include string definition in actual code.
Julia 1.0, 82 bytes
s->foldl((b,c)->c∈"aA" ? !b : (print(c+32isletter(c)sign('_'-c)b);b),s,init=1<0)
Explanation
De-golfed:
function f(s::String)::Bool
foldl(s, init=false) do b, c
if c ∈ "aA"
return !b
else
print(c + 32 * (isletter(c) & b) * sign('_'-c))
return b
end
end
end
foldl(f, s, init=false): takes a function f that maps a state and a Char c to a new state. Applys f repeatedly over each Char of the string s, always passing the state previously returned by f back to f. init is the initial state. Here the state represents whether caps-lock is on.
if c in "aA": If c is an upper- or lowercase 'a', just return the opposite state.
isletter(c) & b: Bool, returns true iff c is a letter and b indicates, that caps-lock is on.
sign('_'-c): -1 if c is lowercase, 1 if c is uppercase.
print(c + 32 * (isletter(c) & b) * sign('_'-c)): Bools act like 0/1 under simple arithmetic operations, so if caps-lock should have an effect, this either adds or substracts 32 from c, returning a Char with opposite case. Then just print that.
Python 3, 110 bytes
code_golf=lambda s:"".join([j.swapcase()if i&1else j for i,j in enumerate(__import__('re').split(r"a|A",s))])
C, 167 168 158 131 bytes
Thanks for @Martin Ender for the code review: I've switched the stream processing for string processing to help with reusability. Also many thanks to @RiaD and @ceilingcat for their suggestions.
c,d;(*t[][2])()={{isupper,tolower},{islower,toupper}};f(char*s){for(d=1;c=*s++;)t[0][1](c)==97?d=!d:putchar(t[!t[d][0](c)][1](c));}
How does it work?
/* int c is the input character,
int d is the Caps Lock flag (1=off, 0=on) starting as "Off". */
int c, d;
/* array of comparison functions and transformation functions for each state */
(*t[][2])() = {{isupper, tolower}, {islower, toupper}};
f(char *s) {
/* Loop if we haven't hit the terminator */
for(d = 1; c = *s++;)
t[0][1](c) == 97 ?
/* If tolower(c)=='a' then flip the Caps Lock state */
d=!d:
/* Otherwise, convert character according to the following table:
Character case
Caps Lock UPPER LOWER
ON tolower() toupper()
OFF toupper() tolower()
*/
putchar(t[!t[d][0](c)][1](c));
}
}
Notes
s[][]is where the magic happens:[][0]is the comparison function and[][1]is the related transformation function for each state.!is applied to the comparison function to force it into the range [0,1].
Lua 5.3, 137 bytes
a=0s=""io.read():gsub(".",function(c)if c:find"[aA]"then a=not a else l=c:lower()s=s..(a and c or l==c and c:upper()or l)end end)print(s)
Notes:
My result was very similar to @Visckmart above. But I included the print(s) in my byte count. Also the try it online test uses Lua 5.1, where my final result is in Lua 5.3. To make my final answer run on the website linked above I had to add a single space in between defining a and s: a=0 s="" which make it 138 bytes when using Lua 5.1
Lua, 152 151 bytes
p=io.read()a=0s=""for c in p:gmatch"."do l=c:lower()if c:find"[aA]"then a=(a+1)%2 else s=s..((c:find"%A"or a==0)and c or l==c and c:upper()or l)end end
Explanation
p = io.read() -- reads the input
a = 0
s = ""
for c in p:gmatch"." do -- loops through the string 'p' (the input) calling each character 'c'
l = c:lower() -- stores the lowercase version of 'c'
if c:find("[aA]") then -- if 'c' is a lowercase or uppercase 'A'
a = (a+1)%2 -- flip the value of 'a' between 0 and 1, from what I've seen it uses less space
else
s = s..((c:find("%A") or a==0) and c or l==c and c:upper() or l)
s = s.. -- append to the string 's'
(c:find("%A") or a==0) -- if this is not a letter or the "reversion" is off
and c or -- then append 'c' else
l==c and c:upper() or l -- if 'c' is lowercase then append it as uppercase else append it as lowercase
end
end
If you have any questions, feel free to ask and i'll try to answer.
MATL, 23 20 bytes
'a A'Yb&Ybt2L)Yo2L(g
Explanation:
'a A'Yb % form a cell array containing {'a', 'A'}
&Yb % split input into substrings, with either of those ('a' or 'A') as delimiters
t2L) % extract out the even positioned cells from that result
Yo % switch the case of those substrings
2L( % place the result back in even positioned cells of the original cell array
g % convert cell array to matrix, concatenating all substrings in the process
% implicit output
Older answer (23 bytes):
Other methods I tried:
0w"@t'aA'm?x~}y?Yo]w]]xv!
t'aA'mXHYsot&y*XzcYowf([]H(
t'aA'mXHYsoy3Y2m*32*Z~c[]H(
Javascript (ES6), 80 79 bytes
(Partly based off of this answer by Rick Hitchcock. Posting as a separate answer because I don't have sufficient reputation to comment.)
(Saved 1 byte thanks to @l4m2's post here.)
a=>a.replace(j=/a()|./gi,(c,o=c[`to${j^c>{}?'Low':'Upp'}erCase`]())=>(j^=!o,o))
JavaScript (ES6), 93 88 84 82 bytes
(saved 5 bytes thanks to @Shaggy, 4 bytes thanks to @user81655, and 2 bytes thanks to @l4m2.)
a=>a.replace(A=/./g,c=>c in{a,A}?(A=!A,''):A?c:c[`to${c<{}?'Low':'Upp'}erCase`]())
Test cases:
let f=
a=>a.replace(A=/./g,c=>c in{a,A}?(A=!A,''):A?c:c[`to${c<{}?'Low':'Upp'}erCase`]())
console.log(f("The quick brown fox jumps over the lazy dog."));
console.log(f("Compilation finished successfully."));
console.log(f("What happens when the CapsLock key on your keyboard doesn't have a notch in it?"));
console.log(f("The end of the institution, maintenance, and administration of government, is to secure the existence of the body politic, to protect it, and to furnish the individuals who compose it with the power of enjoying in safety and tranquillity their natural rights, and the blessings of life: and whenever these great objects are not obtained, the people have a right to alter the government, and to take measures necessary for their safety, prosperity and happiness."));
console.log(f("aAaaaaAaaaAAaAa"));
console.log(f("CapsLock locks cAPSlOCK"));
console.log(f("wHAT IF cAPSlOCK IS ALREADY ON?"));x86-64, 31 bytes
Conforms to the System-V calling convention, tested in Ubuntu 16.04. Takes input from a pointer to a null-terminated in rsi, and outputs the result as a null-terminated string in rdi. rdi is expected to pointer to a buffer that's already been allocated with sufficient size.
Disassembly for byte count:
0: 31 d2 xor edx,edx
2: ac lods al,BYTE PTR ds:[rsi]
3: 88 c1 mov cl,al
5: 24 df and al,0xdf
7: 3c 41 cmp al,0x41
9: 75 05 jne 10 <not_A>
b: 80 f2 20 xor dl,0x20
e: eb f2 jmp 2 <loop>
10: 2c 41 sub al,0x41
12: 3c 19 cmp al,0x19
14: 77 02 ja 18 <not_ascii>
16: 30 d1 xor cl,dl
18: 91 xchg ecx,eax
19: aa stos BYTE PTR es:[rdi],al
1a: 84 c0 test al,al
1c: 75 e4 jne 2 <loop>
1e: c3 ret
Commented Assembly (GAS):
.intel_syntax noprefix
.text
// rsi has the input char*, rdi has the output char*.
// Input char* is \0-terminated.
.global caps
caps:
// Use this for xor mask.
xor edx, edx
// Loop is set up as a do-while loop.
loop:
// al = *rdi++
lodsb
// Save the character we read into cl.
// We use al because the instructions are shorter.
mov cl, al
// Make upper case
and al, 0b11011111
// 65 = 'A'
cmp al, 65
jne not_A
is_A:
// Invert capitialization mask
xor dl,0x20
// Continue
jmp loop
not_A:
// Now we check if input character is ascii.
// Basically, if (al-'A' > 'Z'-'A'), it's not ascii
sub al, 65
cmp al, 25
ja not_ascii
ascii:
// Flip capitilization if necessary.
xor cl, dl
not_ascii:
// Restore saved character that we read.
// xchg is 1 byte, as opposed to mov, which is 2.
xchg ecx, eax
// Write out the character to the output buffer.
stosb
endloop:
// If al == 0, break
test al, al
jnz loop
end:
// Just return, we've already written out the null
// character to the output string.
ret
Testing code in C, takes the input string via the first command line argument, prints out the result string:
#include <stdio.h> //puts
#include <stdlib.h> //malloc, free
#include <string.h> //strlen
void caps(char* output, char* input);
int main(int argc, char** argv) {
char* instr = argv[1];
char* buf = malloc(strlen(instr) + 1);
caps(buf, instr);
// Print converted string.
puts(buf);
free(buf);
}
K4, 49 bytes
Solution:
{@[x;&.q.mod[;2]@&-':w;.q.upper]_/|w:&"a"=_x,"a"}
Examples:
q)k){@[x;&.q.mod[;2]@&-':w;.q.upper]_/|w:&"a"=_x,"a"}"The quick brown fox jumps over the lazy dog."
"The quick brown fox jumps over the lZY DOG."
q)k){@[x;&.q.mod[;2]@&-':w;.q.upper]_/|w:&"a"=_x,"a"}"Compilation finished successfully."
"CompilTION FINISHED SUCCESSFULLY."
q)k){@[x;&.q.mod[;2]@&-':w;.q.upper]_/|w:&"a"=_x,"a"}"What happens when the CapsLock key on your keyboard doesn't have a notch in it?"
"WhT Hppens when the CPSLOCK KEY ON YOUR KEYBOrd doesn't hVE notch in it?"
q)k){@[x;&.q.mod[;2]@&-':w;.q.upper]_/|w:&"a"=_x,"a"}"aAaaaaAaaaAAaAa"
""
Explanation:
Fairly heavy, will look at other answers to see if I can golf this down:
{@[x;&.q.mod[;2]@&-':w;.q.upper]_/|w:&"a"=_x,"a"} / the solution
{ } / lambda with implicit input x
x,"a" / append "a" to input
_ / lowercase
"a"= / boolean list where input is "a"
& / indices where true
w: / save as w
| / reverse
_/ / drop over (remove these indices from...)
@[ ; ; ] / apply [var;indices;function]
.q.upper / uppercase
-':w / deltas of w
& / where, builds list of ascending values
@ / apply
.q.mod[;2] / mod 2 to generate boolean list
x / apply uppercase to input x at these locations
Notes:
Think I may have missed the point. I enabled/disable caps when an a is encountered. Passes the first test cases but not the ones where caps is apparently already enabled...
><>, 139 129 bytes
1vo <
>>i:"z")?^:"A"^>~~>~1$-
^o+< >::"aA"@=?^=?^$v
^o-^? ("^"$*48:v?@:<
^ vv? )"Z":v?(< >>o
> ^v < >:0 )?^;
:< ^v?( "a"
A language with no concept of "characters" is surely the right tool for the job :)
Excel VBA, 115 bytes
A declared subroutine that takes input, s of expected type variant/string and outputs to the range [A1].
Sub f(s)
For i=1To Len(s)
c=Mid(s,i,1)
u=UCase(c)
If u="A"Then d=Not d Else[A1]=[A1]+IIf(d,u,LCase(c))
Next
End Sub
Pip, 22 bytes
(The SC operator was added because of this challenge.)
{LCaQ'a?xX!:ii?SCaa}Mq
Explanation
i is 0, x is empty string (implicit)
q Read a line of input
{ }M Map this function to its characters:
LCa The character, lowercased
Q'a Is it equal to lowercase a?
? If so:
!:i Logically negate i in place (0 -> 1, 1 -> 0)
xX Repeat the empty string that many times (thus, always return
empty string when the character is a/A)
Else:
i? Is i truthy (1)? If so, caps lock is on, so return:
SCa The character, swap-cased
Else return:
a The character, unchanged
Haskell, 96 94 Bytes
(Unix Line Endings)
import Data.Char
t=toUpper
i c|c>'Z'=t c|0<1=toLower c
f(x:s)|t x=='A'=f$i<$>s|0<1=x:f s
f x=x
Jelly, 14 bytes
Œu=”Aœp⁸ŒsJḤ$¦
Full program.
Explanation:
Œu=”Aœp⁸ŒsJḤ$¦ Arguments: x
Œu Uppercase x
=”A ^ Equals 'A' (vectorizes)
œp⁸ ^ Partition ⁸ [⁸=x]
¦ Apply link A, keep results at specific indices B
Œs A: Swap case
$ B: Form a >=2-link monadic chain
JḤ Arguments: y
J Get list indices ([1, length(list)]) of y
Ḥ Double (vectorizes) ^
This way, we only "apply" link A to even indices, so every second
element, starting from the secondd one.
Python 3, 100 bytes
def f(x):x=x.replace('A','a').split('a');return''.join(i.swapcase()if i in x[1::2]else i for i in x)
Perl 5 -p, 31 30 29 bytes
-1 byte thanks to @nwellnhof
-1 byte thanks to @ikegami
#!/usr/bin/perl -p
s/a([^a]*)a?/$1^uc$1^lc$1/egi
pwsh, 109 bytes
$Input|%{$i=$_[0]-ceq'a';$r='';foreach($s in $_.split('a')){$r+=($s.ToUpper(),$s.ToLower())[$i];$i=!$i};$r}
Java 8, 119 108 98 bytes
s->{int f=0,t;for(int c:s)if((t=c&95)==65)f^=1;else System.out.printf("%c",f<1|t<66|t>90?c:c^32);}
-11 bytes thanks to @OlivierGrégoire.
-10 bytes thanks to @Nevay.
Explanation:
s->{ // Method with char-array parameter and no return-type
int f=0,t; // Flag-integer, starting at 0
for(int c:s) // Loop over the characters of the input as integers
if((t=c&95)==65) // If the current character is an 'A' or 'a':
f^=1; // Toggle the flag (0→1 or 1→0)
else // Else:
System.out.printf("%c", // Print integer as character
f<1| // If the flag-integer is 0,
t<66|t>90? // or the current character isn't a letter:
c // Simply output the character as is
: // Else (the flag it 1 and it's a letter)
c^32);} // Print it with its case reversed
PowerShell Core, 105 bytes
"$args"|% t*y|%{if($_-in97,65){$c=!$c}else{Write-Host -n($_,("$_"|%("*per","*wer")[$_-in65..90]))[!!$c]}}
What with no real ternary operator and no default alias for printing to screen, it's not that short.
% t*yexpands to| ForEach-Object -Method ToCharArrayequiv. of"$args".ToCharArray()Write-Host -nis for the parameter-NoNewLine"$_"turns the[char]type back to[string](chars have no upper/lower case in .Net)|% *perdoes the same method call shortcut as earlier, but for.ToUpper(), same with.ToLower()($a,$b)[boolean test]abused as fake-ternary operator!!$cforce-casts to[bool]here it starts undefined$nullso it gets forced it into existence as "caps lock: $false".
Stax, 12 bytes
ìo'½`║â↨╪U?5
It splits on a regex, and then alternately toggles case. Here's the same program, unpacked, ungolfed, and commented.
"a|A"|s split on regex /a|A/
rE reverse and explode array to stack
W repeat forever...
p print top of stack with no newline
:~p print top of stack, case inverted, with no newline
Fortran (GFortran), 307 bytes
CHARACTER(999)F,G
G=' '
READ(*,'(A)')F
N=1
M=1
DO I=1,999
IF(F(I:I)=='a'.OR.F(I:I)=='A')THEN
M=-M
ELSEIF(M==1)THEN
G(N:N)=F(I:I)
N=N+1
ELSE
J=IACHAR(F(I:I))
SELECTCASE(J)
CASE(65:90)
G(N:N)=ACHAR(J+32)
CASE(97:122)
G(N:N)=ACHAR(J-32)
CASE DEFAULT
G(N:N)=F(I:I)
ENDSELECT
N=N+1
ENDIF
ENDDO
PRINT*,TRIM(G)
END
Since Fortran has not "advanced" tools for dealing with strings, I came up with this little monster.
Indented and commented:
CHARACTER(999)F,G !Define input and output strings (up to 999 characters)
G=' ' !Fill output with spaces
READ(*,'(A)')F !Take input
N=1 !Represent the position to be written in output string
M=1 !M=-1: Change case; M=1: Do not change case
DO I=1,999
IF(F(I:I)=='a'.OR.F(I:I)=='A')THEN !If the character is A...
M=-M !Ah-ha - you pressed cPS-LOCK!
ELSEIF(M==1)THEN !Case the character is not A, and do not need to change case...
G(N:N)=F(I:I) !...only copy the character
N=N+1
ELSE !Otherwise...
J=IACHAR(F(I:I)) !...get ascii of current character
SELECTCASE(J)
CASE(65:90) !If is upper case,
G(N:N)=ACHAR(J+32) !now is lower case
CASE(97:122) !If is lower case,
G(N:N)=ACHAR(J-32) !now is upper case
CASE DEFAULT !If do not belong to alphabet,
G(N:N)=F(I:I) !simply copy the character
ENDSELECT
N=N+1
ENDIF
ENDDO
PRINT*,TRIM(G) !Trim out trailing spaces
END !That's all folks!
Chip, 64 bytes
,Ava
>B#
>C#.,Bb
>D##>Cc
>E##>Dd
`~+L^Ee
G~+)~vS
g,\-zm.
f{-F`~'
How it works
This is where I wish I could color-code the source. However, all of the below are full programs, and may be run on their own.
First things first, write a (slightly mangled) cat program.
A-a
Bb
Cc
Dd
Ee
G
g
f--F
Now invert capitalization of all characters A-Za-z.
This is determined by:
c & 0x1F != 0- Filter out anything whose low 5 bits are zero
- This is done by the left most column and upper
~
((c & 0x1F) + 0x5) & ~0x1F == 0- Filter out anything, that when added to 5, carries into or beyond the 6th bit
- This is done by the two
#columns
c & 0x40 != 0- Filter out anything that is less than 64
- This is done by the lower
~
The program assumes it will receive no characters above 127.
The results are aggregated and, the inversion is done by the { at the bottom.
,Ava
>B#
>C#. Bb
>D## Cc
>E## Dd
`~+' Ee
G~<
g,\*
f{-F
But attach that to a toggle (T flip-flop) that is initially off. Now, the toggle decides whether to invert the capitalization, and the filter from above decides which characters to apply it to. Put a * above the m to toggle on every cycle.
,Ava
>B#
>C#. Bb
>D## Cc
>E## Dd
`~+' Ee
G~<
g,\-zm.
f{-F`~'
Toggle the toggle when we see an Aa, and suppress that character too. We have an Aa if the filter above says we have A-Za-z, and the low five bits equal one (c & 0x1F == 1).
,Ava
>B#
>C#.,Bb
>D##>Cc
>E##>Dd
`~+L^Ee
G~+)~vS
g,\-zm.
f{-F`~'
PHP 101 99 bytes
for($s=$argn;$i<strlen($s);$i++)lcfirst($s[$i])==a?$s=strtolower($s)^strtoupper($s)^$s:print$s[$i];
Run like this:
echo '[the input]' | php -nR '[the code]'
Ungolfed:
for ($s = $argn; $i < strlen($s); $i++) {
if (lcfirst($s[$i]) == 'a') {
$s = strtolower($s) ^ strtoupper($s) ^ $s; // Flip the whole string's case.
} else {
print $s[$i]; // Print the current letter.
}
}
This just loops through the string with a for loop, and on each iteration it checks if the current letter is a, if so, then flip the case of the whole string (method from here), and if not, then print the current letter.
Ruby, 42 41 bytes
->s{s.sub!(/a(.*)/i){$1.swapcase}?redo:s}
A lambda accepting a string, mutating the string in place, and returning it. The trick here is that sub returns the string (a truthy value) if a substitution was made, and returns nil otherwise. The existence of swapcase is pretty handy, too.
-1 byte: Replace boolean logic with ternary operator, thanks to Asone Tuhid
->s{
s.sub!(/a(.*)/i){ # Replace "a" followed by anything with
$1.swapcase # the case-swapped capture group
} ? redo # If a match was found, restart the block
: s # Otherwise, return the modified string
}
6502 machine code routine (C64), 51 bytes
A0 00 84 FE B1 FC F0 2A C9 41 F0 06 90 1A C9 C1 D0 08 A9 80 45 FE 85 FE B0 11
B0 06 C9 5B B0 08 90 04 C9 DB B0 02 45 FE 20 16 E7 C8 D0 D6 E6 FD D0 D2 60
Expects a pointer to a 0-terminated input string in $fc/$fd, outputs to the screen.
Commented disassembly
.caps:
A0 00 LDY #$00
84 FE STY $FE ; init capslock state
.loop:
B1 FC LDA ($FC),Y ; next char from string
F0 2A BEQ .done ; NUL -> we're done
C9 41 CMP #$41 ; compare to 'a'
F0 06 BEQ .isa ; if equal, toggle capslock
90 1A BCC .out ; if smaller, direct output
C9 C1 CMP #$C1 ; compare to 'A'
D0 08 BNE .ctog ; if not equal, check for letter
.isa:
A9 80 LDA #$80 ; toggle bit 7 in caps lock state
45 FE EOR $FE
85 FE STA $FE
B0 11 BCS .next ; and go on
.ctog:
B0 06 BCS .cZ ; if char larger 'A', check for 'Z'
C9 5B CMP #$5B ; compare with 'z'+1
B0 08 BCS .out ; larger or equal -> direct output
90 04 BCC .tog ; smaller -> apply capslock
.cZ:
C9 DB CMP #$DB ; compare with 'Z'+1
B0 02 BCS .out ; larger or equal -> direct output
.tog:
45 FE EOR $FE ; toggle bit from capslock state
.out:
20 16 E7 JSR $E716 ; output char
.next:
C8 INY ; and loop to next char
D0 D6 BNE .loop
E6 FD INC $FD
D0 D2 BNE .loop
.done:
60 RTS
Example assembler program using the routine:
Code in ca65 syntax:
.import caps ; link with routine above
.segment "BHDR" ; BASIC header
.word $0801 ; load address
.word $080b ; pointer next BASIC line
.word 2018 ; line number
.byte $9e ; BASIC token "SYS"
.byte "2061",$0,$0,$0 ; 2061 ($080d) and terminating 0 bytes
.bss
string: .res $800
.data
prompt: .byte $d, "input> ", $0
.code
lda #$17 ; set upper/lower mode
sta $d018
lda #<prompt ; display prompt
ldy #>prompt
jsr $ab1e
lda #<string ; read string into buffer
sta $fc
lda #>string
sta $fd
jsr readline
lda #>string ; call our caps routine on buffer
sta $fd
jmp caps
; read a line of input from keyboard, terminate it with 0
; expects pointer to input buffer in $fc/$fd
; NO protection agains buffer overflows !!!
.proc readline
ldy #$0
sty $cc ; enable cursor blinking
sty $fe ; temporary for loop variable
lda $fd
sta $2 ; initial page of string buffer
getkey: jsr $f142 ; get character from keyboard
beq getkey
sta $fb ; save to temporary
and #$7f
cmp #$20 ; check for control character
bcs prepout ; no -> to normal flow
cmp #$d ; was it enter/return?
beq prepout ; -> normal flow
cmp #$14 ; was it backspace/delete?
bne getkey ; if not, get next char
lda $fe ; check current index
bne prepout ; not zero -> ok
lda $2 ; otherwise check if we're in the
cmp $fd ; first page of the buffer
beq getkey ; if yes, can't use backspace
prepout: ldx $cf ; check cursor phase
beq output ; invisible -> to output
sei ; no interrupts
ldy $d3 ; get current screen column
lda ($d1),y ; and clear
and #$7f ; cursor in
sta ($d1),y ; current row
cli ; enable interrupts
output: lda $fb ; load character
jsr $e716 ; and output
ldx $cf ; check cursor phase
beq store ; invisible -> to store
sei ; no interrupts
ldy $d3 ; get current screen column
lda ($d1),y ; and show
ora #$80 ; cursor in
sta ($d1),y ; current row
cli ; enable interrupts
lda $fb ; load character
store: cmp #$14 ; was it backspace/delete?
beq backspace ; to backspace handling code
ldy $fe ; load buffer index
sta ($fc),y ; store character in buffer
cmp #$d ; was it enter/return?
beq done ; then we're done.
iny ; advance buffer index
sty $fe
bne getkey ; not zero -> ok
inc $fd ; otherwise advance buffer page
bne getkey
done: lda #$0 ; terminate string in buffer with zero
ldy $fe ; get buffer index
iny
bne termidxok ; and advance ...
inc $fd
termidxok: sta ($fc),y ; store terminator in buffer
inc $cc ; disable cursor blinking
rts ; return
backspace: ldy $fe ; load buffer index
bne bsidxok ; if zero
dec $fd ; decrement current page
bsidxok: dey ; decrement buffer index
sty $fe
bcs getkey ; and get next key
.endproc
SNOBOL4 (CSNOBOL4), 141 92 bytes
I =INPUT
S I ANY("Aa") REM . R =REPLACE(R,&LCASE &UCASE,&UCASE &LCASE) :S(S)
OUTPUT =I
END
Assumes a single line of input.
A whopping 49 bytes saved by @ninjalj!
Line S does all the work, explained below:
I # in the subject string I match the following PATTERN:
ANY("Aa") # match A or a and
REM . R # match the remainder of I, assigning this to R
=REPLACE( # replace the PATTERN above with
R, ...) # R with swapped cases.
:S(S) # and if there was a match, goto S, else goto next line PHP 4, 77 76 75
foreach(spliti(a,$argn)as$b)echo$a++&1?strtoupper($b)^strtolower($b)^$b:$b;
Split into substrings by A (case insensitive) then toogle every second case.
Old version
for(;a&$c=$argn[$i++];)trim($c,aA)?print($c^chr($f*ctype_alpha($c))):$f^=32;
walks over the string and toogles a flag if the current char is a or A else the char gets toogled depending on the flag and echoed.
Yabasic, 121 bytes
An anonymous function that takes input as a line of text from STDIN and outputs to STDOUT.
Line Input""s$
For i=1To Len(s$)
c$=Mid$(s$,i,1)
u$=Upper$(c$)
If u$="A"Then
d=!d
ElsIf d Then?u$;Else?Lower$(c$);Fi
Next
Wolfram Language (Mathematica), 70 bytes
#//.{x___,"a"|"A",y___}:>Join[{x},ToUpperCase@#+ToLowerCase@#-#&@{y}]&
Takes input and output as a list of characters. For convenience I've added code in the footer to convert this from and back to a string.
How it works
The #//.{x___,"a"|"A",y___}:>Join[{x},...{y}]& part is standard: we find the first A (uppercase or lowercase), reverse case of that comes after the A, and repeat until there are no more A's to be found.
The interesting part is how we reverse case: the function ToUpperCase@# + ToLowerCase@# - #&. We add together the upper-cased version of the input and the lower-cased version of the input, then subtract the actual input. For example, given the list {"I","n","P","u","T"} this computes
{"I","N","P","U","T"}+{"i","n","p","u","t"}-{"I","n","P","u","T"}
which threads over lists as
{"I"+"i"-"I","N"+"n"-"n","P"+"p"-"P","U"+"u"-"u","T"+"t"-"T"}
and although Mathematica doesn't have any particular way of adding two strings, it's smart enough to simplify a+b-a to b for any values of a and b, including string values, so this simplifies to {"i","N","p","U","t"}.
R, 92 bytes
cat(`[<-`(v<-el(strsplit(scan(,""),"a|A")),w<-c(F,T),chartr("a-zA-Z","A-Za-z",v)[w]),sep="")
Thank @Giuseppe for fixing the answer.
Explanation
# Write
cat(
# Replace and return, this is the function that powers
# the R store at index operations, a[i]<-b
`[<-`(
# First arg - what to replace = extract first list element
# of a string input after splitting at a or A
v<-el(strsplit(scan(,""),"a|A")),
# Second arg - index to replace = abuse vector recycling
# to create infinite F, T, F, T, F, etc series
w<-c(F,T),
# Third arg - replacement values = replace with case toggled letters
chartr("a-zA-Z","A-Za-z",v)[w]),
# Write without separation
sep="")
APL (Dyalog Classic), 46 41 40 bytes
'aA'~⍨⊢819⌶⍨¨2|(⊢≠819⌶¨)+≠\∘(∨⌿'aA'∘.=⊢)
How??
'aA'~⍨- Remove alla's from ...⊢819⌶⍨¨2|(⊢≠819⌶¨)- ... the alternating upper-and-lower-case of the argument ...+≠\∘... based upon ...(∨⌿'aA'∘.=⊢)... the position ofaand/orA.
Japt v2.0a0, 16 bytes
e/a.*/i_År\l_c^H
Explanation
e :Recursively replace
/a.*/i :RegEx /a.*/gi
_ :Pass each match through a function
Å : Slice off the first character
r : Replace
\l : RegEx /[A-Za-z]/g
_ : Pass each match though a function
c^ : Bitwise XOR the character code
H : With 32
Retina, 33 21 17 bytes
i(Tv`lL`Ll`a.*
a
Explanation:
i( i is for case-insensitive, the paren makes it modify both stages
Tv` Transliteration, with simple overlaps (v) - 1 match at every start pos
lL`Ll` Replace lowercase with uppercase, and vice versa
a.* Every 'a' will match, overlapping to the end of the string
This swaps the case on all letters after each 'a'
a Replace all 'a's with nothing
-12 bytes thanks to Martin
-4 bytes thanks to Leo
Python 3, 114, 101, 97 bytes
import re
print(''.join(i.swapcase()if j%2else i for j,i in enumerate(re.split('a|A',input()))))
Split on all a's and toggle the case on the odd parts
Thanks @ElPedro !
Python, 63 bytes
f=lambda s:s and[s[0]+f(s[1:]),f(s[1:]).swapcase()][s[0]in"aA"]
Another Python solution, works in Python 2 and 3. Takes a very long time for all but small inputs.
Rust, 330 bytes
fn main(){let mut i=String::new();std::io::stdin().read_line(&mut i);let mut o=vec![];let mut c=false;for l in i.trim().as_bytes(){if*l==65||*l==97{c=!c;}else if c{if l.is_ascii_uppercase(){o.push((*l).to_ascii_lowercase());}else{o.push((*l).to_ascii_uppercase());}}else{o.push(*l);}}println!("{}",String::from_utf8(o).unwrap());}
Ungolfed
fn main() {
let mut input = String::new();
std::io::stdin().read_line(&mut input);
let mut output_chars = vec![];
let mut capslock = false;
for letter in input.trim().as_bytes() {
if *letter == 65 || *letter == 97 {
capslock = !capslock;
} else if capslock {
if letter.is_ascii_uppercase() {
output_chars.push((*letter).to_ascii_lowercase());
} else {
output_chars.push((*letter).to_ascii_uppercase());
}
} else {
output_chars.push(*letter);
}
}
println!("{}", String::from_utf8(output_chars).unwrap());
}
Since this uses bytes instead of chars in the loop, 65 and 97 are the byte values for 'A' and 'a'.
I'm new to Rust, so this might be golfable further.
Python 2, 103, 97 bytes
import re
def f(s):print"".join(j.swapcase()if i%2else j for i,j in enumerate(re.split('a|A',s)))
AutoHotKey, 7 bytes
a::vk14
// Is this valid? This really do what OP want -- replace a by CapsLock (vk14).
Run this program, and type the input from keyboard..
Husk, 11 bytes
Γ·§?m\:€"Aa
Explanation
I'm using the somewhat obscure overloading of Γ called listNF, which constructs recursive functions that operate on lists.
It corresponds to the following Haskell pattern:
listNF f = g
where g (x : xs) = f g x xs
g [] = []
The idea is that listNF takes a helper function f and returns a new function g, which takes a list.
The function f takes a function, which will always be g, and the head x and tail xs of the list, and does something with them.
In our application, f calls g recursively on xs.
The program is interpreted like this:
Γ (· (§ (?m\) : (€"Aa")))
Γ ( ) Create a function g that takes a list (x:xs) and applies a function on x and xs.
· ( ) Compose g with second argument of function in parentheses.
Instead of x and xs, the function is called on x and the result of a recursive call of g on xs.
(€"Aa") Check if x is 'A' or 'a'.
(?m\) If it is, then swap the case of every char in g(xs).
§ : Otherwise, prepend x to g(xs).
CJam, 31 bytes
q{_eu'A={;T!:T;}{_el_eu+|T=}?}%
Explanation
Loops through searching for a and non-a
CJam, 47 bytes
Slightly more fun version
[q'a'Aer'A/_2%\2/z)\;{_[el_eu]z{\(@|1=\}%e_}%]z
Explanation
This code has two parts.
[
Part 1
q -> Read all input as a single string
'a'Aer -> Replace 'a' in string with 'A'
'A/ -> Split by 'A' leaving empty sets
_ -> Duplicate
2% -> Get all rows where i%2 is 0
\ -> Swap top two elements of stack
2/ -> Split into array with groups of length 2
z -> Zip/Transpose
)\; -> Right uncons, swap and pop.
Part 2
{
_[el_eu] -> Create an array containing the lower case and upper case version
z -> Zip/Transpose
{
\ -> Swap top two
( -> Uncons left
@ -> Rotate top three elements of stack
| -> Set union
1= -> Get element at array indice 1 (Wraps)
\ -> Swap top two
}% -> Map onto every element of string
e_ -> Flatten
}% -> Map onto every element of array
]z -> Zip/Transpose
The first part splits the string by 'A' leaving any empty sets behind. For the string "baacadE" that will give the following array.
["b", "", "c", "dE"]
That way, all normal case elements are at even indices and reverse case are odd. Which After executing the rest of the first part gives the following.
[["b", "c"], ["", "dE"]]
The second part will take the odd half and reverse the case of every string. This is done with the set union operator |. So for the element "dE" It will do the following. Since the set union operator preserves the order of the elements found in the first string/array we can always assume the reverse case element will be the second one in the string/array.
["dE", "dD"]
["dD", "dE"]
["dD", "E", "d"]
["E", "d", "dD"]
["E", "dD"]
["E", "D"]
...
["D", "E", "eE"]
["D", "Ee"]
["D", "e"]
All That is left to do is zip up the two halves.
Charcoal, 21 bytes
FS¿⁼a↧ι≦¬κ¿κι¿№αι↧ι↥ι
Try it online! Link is to verbose version of code. Explanation:
FS
Loop through each character in the line of input.
¿⁼a↧ι
Test whether it equals a in lower case.
≦¬κ
If so then logically negate k. (Note that for some reason Charcoal considers k's default value None to be truthy.)
¿κ
Otherwise check whether k is currently truthy.
ι
If so then just print the character.
¿№αι
Otherwise check whether the current character is an upper case letter.
↧ι
If it is then print it in lower case.
↥ι
Otherwise print it in upper case.
Python 3, 78 72 bytes
import re
lambda x:re.sub("[Aa](.*?)(a|A|$)",lambda m:m[1].swapcase(),x)
05AB1E, 12 bytes
õ?„AaS¡Dvć?š
Explanation
õ? # print an empty string (to account for the special case of only A's)
„AaS¡ # split on occurrences of "A" or "a"
D # duplicate
v # for each element in the top copy
ć? # extract and print the head of the other copy
š # switch the case of the rest of the other copy
C, 72 bytes
Thanks to @Ton Hospel for helping to save 16 bytes!
t,c;f(char*s){for(t=0;c=*s++;6305%c?putchar(isalpha(c)?c^t:c):(t^=32));}
Vim, 16 bytes
qq/\ca
xg~$@qq@q
Assumes the input is on a single line
Explanation
qq Start a loop
/\ca␊ Find the first occurence of an a, end the loop if there are none left
xg~$ Remove it and invert the case of the rest of the file
@qq@q End the loop
Husk, 15 bytes
ω(F·+otm\↕·≠_'a
Explanation
ω(F·+(tm\)↕·≠_'a) -- example input: "Bar, baz and Foo."
ω( ) -- apply the following, until fixpoint is reached:
↕ -- | split string with predicate
· _ -- | | the lower-cased character
≠ 'a -- | | is not 'a'
-- | : ("B","ar, baz and Foo.")
F -- | apply the following to the tuple
+ -- | | join the elements with..
· ( ) -- | | ..the second element: "ar, baz and Foo."
m\ -- | | | swap case: "AR, BAZ AND fOO."
t -- | | | tail: "R, BAZ AND fOO."
-- | : "BR, BAZ AND fOO."
-- : "BR, Bz ND fOO."
Haskell, 92 bytes
import Data.Char
g x|x<'['=toLower x|1>0=toUpper x
f(a:b)|elem a"aA"=f$g<$>b|1>0=a:f b
f x=x
Explanation
First we declare g to be the function that maps lowercase to upper case and uppercase to lowercase. This is actually the majority of our bytecount. Then we define the function f. If the input to f is of the form a:b we do
f(a:b)
|elem a"aA"=f$g<$>b
|1>0=a:f b
a and A match the first pattern and thus we apply f to the input with it's case inverted. Otherwise we move a out front and apply f to b.
Pyth, 21 bytes
ssm+Pdr2edcscR\AcQ\a2
Explanation
ssm+Pdr2edcscR\AcQ\a2
scR\AcQ\a Split the input on 'a' and 'A'
c 2 Split the blocks into pairs.
m d d For each pair...
+P r2e ... cAPSlOCK the second block.
ss Join the blocks together.
V, 9 bytes
ò/ãa
xg~$
Hexdump:
00000000: f22f e361 0a78 677e 24 ./.a.xg~$
Explanation:
ò " Recursively:
/ãa " Move forward to the next 'a' (upper or lowercase)
" This will break the loop when there are no more 'a's
x " Delete the 'a'
g~$ " Toggle the case of every character after the cursor's position.