| Bytes | Lang | Time | Link |
|---|---|---|---|
| 075 | JavaScript Node.js | 250208T112458Z | l4m2 |
| 011 | Maple | 230527T014707Z | 138 Aspe |
| 006 | Pari/GP | 171112T075844Z | alephalp |
| 003 | R | 171110T135850Z | Giuseppe |
| 098 | Proton | 171110T140125Z | hyperneu |
| 023 | 05AB1E | 200331T120950Z | Kevin Cr |
| 176 | Java OpenJDK 8 | 171114T194546Z | ceilingc |
| 091 | JavaScript ES6 | 171113T113437Z | edc65 |
| 128 | APLNARS | 181021T165220Z | user5898 |
| 045 | CJam | 181020T195013Z | Peter Ta |
| 010 | Jelly | 171110T161959Z | Dennis |
| 034 | MY | 171110T151557Z | Adalynn |
| 258 | Java 8 | 171110T162743Z | Kevin Cr |
| 141 | Clojure | 171114T213014Z | NikoNyrh |
| 149 | Python 3 | 171114T203350Z | Bolce Bu |
| 071 | Haskell | 171110T154750Z | totallyh |
| nan | SageMath | 171113T113644Z | user4594 |
| 043 | Jelly | 171110T145238Z | user2027 |
| 050 | Excel VBA | 171110T145640Z | Taylor R |
| 216 | Python 3 | 171110T144250Z | Кирилл М |
| 125 | C | 171110T145016Z | Steadybo |
| 075 | Python 2 | 171111T170530Z | xnor |
| 059 | Haskell | 171111T164914Z | xnor |
| 052 | Wolfram Language Mathematica | 171110T214649Z | Misha La |
| 015 | Jelly | 171110T173853Z | Leaky Nu |
| 095 | Python 2 | 171110T162101Z | totallyh |
| 062 | Haskell | 171111T130217Z | Christia |
| 032 | R | 171111T092215Z | JAD |
| 133 | TIBasic 83 series | 171111T065738Z | Misha La |
| 1442 | Wolfram Language Mathematica | 171110T232117Z | Not a tr |
| 035 | MATL | 171110T145902Z | Luis Men |
| 002 | Jelly | 171110T135335Z | Erik the |
| 028 | Octave | 171110T151402Z | Luis Men |
| 024 | Jelly | 171110T150008Z | hyperneu |
| 005 | J | 171110T150510Z | Galen Iv |
| 002 | TIBasic | 171110T145553Z | totallyh |
| 030 | Octave | 171110T144532Z | Stewie G |
| 003 | Julia | 171110T143057Z | Uriel |
| 029 | Python 2 + numpy | 171110T141207Z | Mr. Xcod |
| 003 | Wolfram Language Mathematica | 171110T135454Z | user2027 |
JavaScript (Node.js), 75 bytes
q=(a,i=0,j=1,s=0)=>a+a?a.map(e=>s-=e[i]*q(a.filter(_=>_!=e),i+1,j=-j))&&s:j
Maple, 11 bytes
Determinant
LinearAlgebra[Determinant](Matrix([[2, 3, 1], [3, 2, 3], [0, 3, 2]]));
LinearAlgebra[Determinant](LinearAlgebra[HilbertMatrix](4));
R, 3 bytes
Trivial Solution
det
R, 94 92 89 bytes
re-implemented solution
outgolfed by Jarko Dubbeldam
d=function(m)"if"(x<-nrow(m),m[,1]%*%sapply(1:x,function(y)(-1)^y*-d(m[-y,-1,drop=F])),1)
Recursively uses expansion by minors down the first column of the matrix.
f <- function(m){
x <- nrow(m) # number of rows of the matrix
if(sum(x) > 1){ # when the recursion reaches a 1x1, it has 0 rows
# b/c [] drops attributes
minor <- function(y){
m[y] * (-1)^y *
-d(m[-y,-1]) # recurse with the yth row and first column dropped
}
minors <- sapply(1:x,minor) # call on each row
sum(minors) # return the sum
} else {
m # return the 1x1 matrix
}
}
Proton, 98 bytes
f=m=>(l=len(m))-1?sum((-1)**i*m[0][i]*f([[m[k][j]for k:1..l]for j:0..l if j-i])for i:0..l):m[0][0]
-3 bytes thanks to Mr. Xcoder
-3 bytes thanks to Erik the Outgolfer
-1 byte thanks to S.S. Anne
Expansion over the first row
05AB1E, 23 bytes
ā<œε©2.ÆíÆ.±Iε®Nèè}«P}O
Port of @LeakyNun's Jelly answer.
Try it online or verify all but one test cases (the biggest test case times out on TIO).
Explanation:
ā # Push a list in the range [1, (implicit) input-length]
< # Decrease it by 1 to make the range [0, input-length)
œ # Get all permutations of this list
ε # Map each permutation to:
© # Store the permutation in variable `®` (without popping)
2.Æ # Get all 2-element combinations of this list
í # Reverse each inner list
Æ # Reduce each by subtraction
.± # And take their signum (-1 if a<0; 0 if a==0; 1 if a>0)
I # Push the input
ε # Map each row to:
® # Get the current permutation from variable `®`
Nè # Use the map-index to index into this permutation
è # And use that to index into the row
}« # After the map: merge the two lists together
P # And take its product
}O # After the outer map: sum all value
# (after which it is output implicitly as result)
Java (OpenJDK 8), 195 192 177 176 bytes
long d(int[][]m){long D=0;for(int i=m.length,l=i-1,t[][]=new int[l][l],j,k;i-->0;D+=m[0][i]*(1-i%2*2)*(l<1?1:d(t)))for(j=l*l;j-->0;)t[j/l][k=j%l]=m[1+j/l][k<i?k:k+1];return D;}
Like many other answers, this also uses the Laplace formula. A slightly less golfed version:
long d(int[][]m){
long D=0;
int i=m.length,l=i-1,t[][]=new int[l][l],j,k
for(;i-->0;)
for(j=l*l;j-->0;)
t[j/l][k=j%l]=m[1+j/l][k<i?k:k+1];
D+=m[0][i]*(1-i%2*2)*(l<1?1:d(t));
return D;
}
JavaScript (ES6), 91
Recursive Laplace
q=(a,s=1)=>+a||a.reduce((v,[r],i)=>v-(s=-s)*r*q(a.map(r=>r.slice(1)).filter((r,j)=>j-i)),0)
Less golfed
q = (a,s=1) => // s used as a local variable
a[1] // check if a is a single element array
// if array, recursive call expanding along 1st column
? a.reduce((v,[r],i) => v-(s=-s)*r*q(a.map(r=>r.slice(1)).filter((r,j)=>j-i)),0)
: +a // single element, convert to number
Test
q=(a,s=1)=>+a||a.reduce((v,[r],i)=>v-(s=-s)*r*q(a.map(r=>r.slice(1)).filter((r,j)=>j-i)),0)
TestCases=`[[42]] -> 42
[[2, 3], [1, 4]] -> 5
[[1, 2, 3], [4, 5, 6], [7, 8, 9]] -> 0
[[13, 17, 24], [19, 1, 3], [-5, 4, 0]] -> 1533
[[372, -152, 244], [-97, -191, 185], [-53, -397, -126]] -> 46548380
[[100, -200, 58, 4], [1, -90, -55, -165], [-67, -83, 239, 182], [238, -283, 384, 392]] -> 571026450
[[432, 45, 330, 284, 276], [-492, 497, 133, -289, -28], [-443, -400, 56, 150, -316], [-344, 316, 92, 205, 104], [277, 307, -464, 244, -422]] -> -51446016699154`
.split('\n')
TestCases.forEach(r=>{
[a,k] = r.split (' -> ')
a = eval(a)
d = q(a)
console.log('Test '+(k==d ? 'OK':'KO')+
'\nMatrix '+a.join('|')+
'\nResult '+d+
'\nCheck '+k)
})APL(NARS), 64 chars, 128 bytes
{1≥k←↑⍴w←⍵:⍵⋄2=k:-/⌽w[2;]×⌽w[1;]⋄v←⍳k⋄-/w[1;]×∇¨{w[v∼1;v∼⍵]}¨⍳k}
This would be the formula used in the schools, it is easy, much easier than i tought... if w is a 2x2 matrix -/⌽w[2;]×⌽w[1;] rotate first row multiply with second row than reverse and make difference in pratice it does: (w[1;1]×w[2;2])-w[1;2]×w[2;1] else if it is a matrix nxn with n>2 multiply the first row with its adjunt Matrix (if i remember well the name), and make -/; test:
D←{1≥k←↑⍴w←⍵:⍵⋄2=k:-/⌽w[2;]×⌽w[1;]⋄v←⍳k⋄-/w[1;]×∇¨{w[v∼1;v∼⍵]}¨⍳k}
D ⊃(1 9 3)(4 ¯5 6)(7 8 9)
162
D 3 3 ⍴ ⍳20
0
D ⊃(1 0)(0 1)
1
D ,89
89
D 1
1
D 'ac'
RANK ERROR
CJam (50 45 bytes)
{:A_,{1$_,,.=1b\)/:CAff*A@zf{\f.*1fb}..-}/;C}
This is an anonymous block (function) which takes a 2D array on the stack and leaves an integer on the stack.
Dissection
This implements the Faddeev-LeVerrier algorithm, and I think it's the first answer to take that approach.
The objective is to calculate the coefficients \$c_k\$ of the characteristic polynomial of the \$n\times n\$ matrix \$A\$, $$p(\lambda )\equiv \det(\lambda I_{n}-A)=\sum _{k=0}^{n}c_{k}\lambda ^{k}$$ where, evidently, \$c_n = 1\$ and \$c_0 = (−1)^n \det A\$.
The coefficients are determined recursively from the top down, by dint of the auxiliary matrices \$M\$, $$\begin{aligned}M_{0}&\equiv 0&c_{n}&=1\qquad &(k=0)\\M_{k}&\equiv AM_{k-1}+c_{n-k+1}I\qquad \qquad &c_{n-k}&=-{\frac {1}{k}}\mathrm {tr} (AM_{k})\qquad &k=1,\ldots ,n~.\end{aligned}$$
The code never works directly with \$c_{n-k}\$ and \$M_k\$, but always with \$(-1)^k c_{n-k}\$ and \$(-1)^{k+1}AM_k\$, so the recurrence is $$(-1)^k c_{n-k} = \frac1k \mathrm{tr} ((-1)^{k+1} AM_{k}) \\ (-1)^{k+2} AM_{k+1} = (-1)^k c_{n-k}A - A((-1)^{k+1}A M_k)$$
{ e# Define a block
:A e# Store the input matrix in A
_, e# Take the length of a copy
{ e# for i = 0 to n-1
e# Stack: (-1)^{i+2}AM_{i+1} i
1$_,,.=1b e# Calculate tr((-1)^{i+2}AM_{i+1})
\)/:C e# Divide by (i+1) and store in C
Aff* e# Multiply by A
A@ e# Push a copy of A, bring (-1)^{i+2}AM_{i+1} to the top
zf{\f.*1fb} e# Matrix multiplication
..- e# Matrix subtraction
}/
; e# Pop (-1)^{n+2}AM_{n+1} (which incidentally is 0)
C e# Fetch the last stored value of C
}
Jelly, 16 15 12 10 bytes
Ḣ×Zß-Ƥ$Ṛḅ-
Uses Laplace expansion. Thanks to @miles for golfing off 3 5 bytes!
How it works
Ḣ×Zß-Ƥ$Ṛḅ- Main link. Argument: M (matrix / 2D array)
Ḣ Head; pop and yield the first row of M.
$ Combine the two links to the left into a monadic chain.
Z Zip/transpose the matrix (M without its first row).
ß-Ƥ Recursively map the main link over all outfixes of length 1, i.e., over
the transpose without each of its rows.
This yields an empty array if M = [[x]].
× Take the elementwise product of the first row and the result on the
right hand. Due to Jelly's vectorizer, [x] × [] yields [x].
Ṛ Reverse the order of the products.
ḅ- Convert from base -1 to integer.
[a] -> (-1)**0*a
[a, b] -> (-1)**1*a + (-1)**0*b = b - a
[a, b, c] -> (-1)**2*a + (-1)**1*b + (-1)**0*c = c - b + a
etc.
MY, 3 (4?) bytes
ω∥↵
Precision is a little weird (the second test case is 5.000000000000001), this can be fixed at a cost of one byte: ω∥⌊↵
Java 8, 266 261 259 258 bytes
long d(int[][]m){long r=0;int i=0,j,k,l=m.length,t[][]=new int[l-1][l-1],q=m[0][0];if(l<3)return l<2?q:q*m[1][1]-m[0][1]*m[1][0];for(;i<l;r+=m[0][i]*(1-i++%2*2)*d(t))for(j=0;++j<l;)for(k=l;k-->0;){q=m[j][k];if(k<i)t[j-1][k]=q;if(k>i)t[j-1][k-1]=q;}return r;}
Look mom, no build-ins.. because Java has none.. >.>
-7 bytes thanks to @ceilingcat.
Explanation:
Try it here. (Only the last test case is too big to fit in a long of size 263-1.)
long d(int[][]m){ // Method with integer-matrix parameter and long return-type
long r=0; // Return-long, starting at 0
int i=0,j,k, // Index-integers
l=m.length, // Dimensions of the square matrix
t[][]=new int[l-1][l-1],// Temp-matrix, one size smaller than `m`
q=m[0][0]; // The first value in the matrix (to reduce bytes)
if(l<3) // If the dimensions are 1 or 2:
return l<2? // If the dimensions are 1:
q // Simply return the only item in it
: // Else (the dimensions are 2):
q*m[1][1]-m[0][1]*m[1][0];
// Calculate the determinant of the 2x2 matrix
// If the dimensions are 3 or larger:
for(;i<l; // Loop (1) from 0 to `l` (exclusive)
r+= // After every iteration: add the following to the result:
m[0][i] // The item in the first row and `i`'th column,
*(1-i++%2*2) // multiplied by 1 if `i` is even; -1 if odd,
*d(t)) // multiplied by a recursive call with the temp-matrix
for(j=0; // Reset index `j` to 0
++j<l;) // Inner loop (2) from 0 to `l` (exclusive)
for(k=l;k-->0;){ // Inner loop (3) from `l-1` to 0 (inclusive)
q=m[j][k]; // Set the integer at location `j,k` to reduce bytes
if(k<i) // If `k` is smaller than `i`:
t[j-1][k]=q; // Set this integer at location `j-1,k`
if(k>i) // Else-if `k` is larger than `i`:
t[j-1][k-1]=q; // Set this integer at location `j-1,k-1`
// Else: `k` and `i` are equals: do nothing (implicit)
} // End of inner loop (3)
// End of inner loop (2) (implicit / single-line body)
// End of loop (1) (implicit / single-line body)
return r; // Return the result-long
} // End of method
Clojure, 141 bytes
(fn D[A](apply +(map *(cycle[1 -1])(first A)(if(next A)(for[R[(range(count A))]i R](D(for[a(rest A)](for[j(remove #{i}R)](nth a j)))))[1]))))
Laplace's formula, longer than I'd like...
Python 3, 153 149 Bytes
def d(n):
l=len(n);r=range(0,l)
if l==1:return n[0][0]
else:return sum([(-1)**i*n[0][i]*d([[n[a][b]for b in r if b!=i]for a in r[1:]])for i in r])
I'm new to code golf, so I wouldn't be surprised if this could be improved. It's calculated in a pretty basic way; by summing the product of each element of the first row with the determinant of its respective minor, with a sign change based on the element's position.
Edit: Realized I could shorten it by using a single character for the function name :/
Haskell, 71 bytes
-3 bytes thanks to Lynn. Another one bytes the dust thanks to Craig Roy.
f[]=1
f(h:t)=foldr1(-)[v*f[take i l++drop(i+1)l|l<-t]|(i,v)<-zip[0..]h]
Try it online! Added -O flag for optimization purposes. It is not necessary.
Explanation (outdated)
f recursively implements cofactor expansion.
f[[x]]=x
This line covers the base case of a 1 × 1 matrix, in which case the determinant is mat[0, 0].
f(h:t)=
This uses Haskell's pattern matching to break the matrix into a head (the first row) and a tail (the rest of the matrix).
[ |(i,v)<-zip[0..]h]
Enumerate the head of the matrix (by zipping the infinite list of whole numbers and the head) and iterate over it.
(-1)*i*v
Negate the result based on whether its index is even since the calculation of the determinant involves alternating addition and subtraction.
[take i l++drop(i+1)l|l<-t]
This essentially removes the ith column of the tail by taking i elements and concatenating it with the row with the first (i + 1)th elements dropped for every row in the tail.
*f
Calculate the determinant of the result above and multiply it with the result of (-1)*i*v.
sum
Sum the result of the list above and return it.
SageMath, various
Here are a bunch of methods for computing the determinant that I found interesting, all programmed in SageMath. They can all be tried here.
Builtin, 3 bytes
det
This one isn't too interesting. Sage provides global-level aliases to many common operations that would normally be object methods, so this is shorter than lambda m:m.det().
Real Part of Product of Eigenvalues, 36 bytes
lambda m:real(prod(m.eigenvalues()))
Unfortunately, eigenvalues is not one of those global-level aliases. That, combined with the fact that Sage doesn't have a neat way to compose functions, means we're stuck with a costly lambda. This function symbolic values which are automatically converted to numeric values when printed, so some floating point inaccuracy may be present in some outputs.
Product of Diagonal in Jordan Normal Form, 60 bytes
lambda m:prod(m.jordan_form()[x,x]for x in range(m.nrows()))
In Jordan Normal form, an NxN matrix is represented as a block matrix, with N blocks on the diagonal. Each block consists of either a single eigenvalue, or a MxM matrix with a repeated eigenvalue on the diagonal and 1s on the super-diagonal (the diagonal above and to the right of the "main" diagonal). This results in a matrix with all eigenvalues (with multiplicity) on the main diagonal, and some 1s on the super-diagonal corresponding to repeated eigenvalues. This returns the product of the diagonal of the Jordan normal form, which is the product of the eigenvalues (with multiplicty), so this is a more roundabout way of performing the same computation as the previous solution.
Because Sage wants the Jordan normal form to be over the same ring as the original matrix, this only works if all of the eigenvalues are rational. Complex eigenvalues result in an error (unless the original matrix is over the ring CDF (complex double floats) or SR). However, this means that taking the real part is not necessary, compared to the above solution.
Product of Diagonal in Smith Decomposition
lambda m:prod(m.smith_form()[0].diagonal())
Unlike Jordan normal form, Smith normal form is guaranteed to be over the same field as the original matrix. Rather than computing the eigenvalues and representing them with a block diagonal matrix, Smith decomposition computes the elementary divisors of the matrix (which is a topic a bit too complicated for this post), puts them into a diagonal matrix D, and computes two matrices with unit determinant U and V such that D = U*A*V (where A is the original matrix). Since the determinant of the product of matrices equals the product of the determinants of the matrices (det(A*B*...) = det(A)*det(B)*...), and U and V are defined to have unit determinants, det(D) = det(A). The determinant of a diagonal matrix is simply the product of the elements on the diagonal.
Laplace Expansion, 109 bytes
lambda m:m.nrows()>1and sum((-1)**j*m[0,j]*L(m[1:,:j].augment(m[1:,j+1:]))for j in range(m.ncols()))or m[0,0]
This performs Laplace expansion along the first row, using a recursive approach. det([[a]]) = a is used for the base case. It should be shorter to use det([[]]) = 1 for the base case, but my attempt at that implementation had a bug that I haven't been able to track down yet.
Leibniz's Formula, 100 bytes
L2 = lambda m:sum(sgn(p)*prod(m[k,p[k]-1]for k in range(m.ncols()))for p in Permutations(m.ncols()))
This directly implements Leibniz's formula. For a much better explanation of the formula and why it works than I could possibly write, see this excellent answer.
Real Part of e^(Tr(ln(M))), 48 bytes
lambda m:real(exp(sum(map(ln,m.eigenvalues()))))
This function returns symbolic expressions. To get a numerical approximation, call n(result) before printing.
This is an approach that I haven't seen anyone use yet. I'm going to give a longer, more-detailed explanation for this one.
Let A be a square matrix over the reals. By definition, the determinant of A is equal to the product of the eigenvalues of A. The trace of A is equal to the sum of A's eigenvalues. For real numbers r_1 and r_2, exp(r_1) * exp(r_2) = exp(r_1 + r_2). Since the matrix exponential function is defined to be analogous to the scalar exponential function (especially in the previous identity), and the matrix exponential can be computed by diagonalizing the matrix and applying the scalar exponential function to the eigenvalues on the diagonal, we can say det(exp(A)) = exp(trace(A)) (the product of exp(λ) for each eigenvalue λ of A equals the sum of the eigenvalues of exp(A)). Thus, if we can find a matrix L such that exp(L) = A, we can compute det(A) = exp(trace(L)).
We can find such a matrix L by computing log(A). The matrix logarithm can be computed in the same way as the matrix exponential: form a square diagonal matrix by applying the scalar logarithm function to each eigenvalue of A (this is why we restriced A to the reals). Since we only care about the trace of L, we can skip the construction and just directly sum the exponentials of the eigenvalues. The eigenvalues can be complex, even if the matrix isn't over the complex ring, so we take the real part of the sum.
Jelly, 43 bytes
Finally I've done writing my non-builtin solution in a golfing language!
ḣ⁹’’¤;ṫḊ€Ç×⁸ị@⁹’¤¤ḷ/¤
çЀ⁸J‘¤µJ-*×NS
ÇḢḢ$Ṗ?
Thanks to HyperNeutrino for saving a byte!
Try it online! (spaced code for clarity)
terribly long way to remove n'th elements from a list, will improve later
This answer had been outgolfed by answers of HyperNeutrino, Dennis and Leaky Nun. Jelly is very popular as a golfing language.
Quick explanation:
ÇḢḢ$Ṗ? Main link.
? If
Ṗ after remove the last element, the value is not empty (truthy)
Ç then execute the last link
ḢḢ$ else get the element at index [1, 1].
çЀ⁸J‘¤µJ-*×NS Helper link 1, take input as a matrix.
çЀ Apply the previous link, thread right argument to
⁸J‘¤ the range [2, 3, ..., n+1]
µ With the result,
J-* generate the range [-1, 1, -1, 1, ...] with that length
×N Multiply by negative
S Sum
ḣ⁹’’¤;ṫḊ€Ç×⁸ị@⁹’¤¤ḷ/¤ Helper link 2, take left input as a matrix, right input as a number in range [2..n+1]
ḣ
⁹’’¤ Take head ρ-2 of the matrix
; concatenate with
ṫ tail ρ (that is, remove item ρ-1)
Ḋ€ Remove first column
Ç Calculate determinant of remaining matrix
× ¤ multiply by
ḷ/ the first column,
ị@ row #
⁹’¤ ρ-1 (just removed in determinant calculation routine) of
⁸ ¤ the matrix.
Excel VBA, 58 50 Bytes
Returns the determinant of the matrix entered into the the upper left corner of the default Sheet1 object.
?Evaluate("MDeterm("+Sheet1.UsedRange.Address+")")
-8 Bytes thanks to Greedo
Python 3, 238 bytes, 227 bytes, 224 bytes, 216 bytes
from functools import*
from itertools import*
r=range;n=len;s=sum
f=lambda l:s(reduce(lambda p,m:p*m,[l[a][b]for a,b in zip(r(n(l)),j)])*(-1)**s(s(y<j[x]for y in j[x:])for x in r(n(l)))for j in permutations(r(n(l))))
My solution uses the definition of a determinant for calculations. Unfortunately, the complexity of this algorithm is n! and I can not show the passage of the last test, but in theory this is possible.
C, 176 125 bytes
Thanks to @ceilingcat for golfing 42 bytes, and thanks to both @Lynn and @Jonathan Frech for saving a byte each!
d(M,n)int*M;{int i=n--,s=*M*!n,c,T[n*n];for(;i--;s+=M[i]*(1-i%2*2)*d(T,n))for(c=n*n;c--;T[c]=M[n-~c+c/n+(c%n>=i)]);return s;}
Calculates the determinant using the Laplace expansion along the first row.
Unrolled:
d(M, n)int*M;
{
int i=n--, s=*M*!n, c, T[n*n];
for (; i--; s+=M[i]*(1-i%2*2)*d(T,n))
for (c=n*n; c--;)
T[c] = M[n-~c+c/n+(c%n>=i)];
return s;
}
Python 2, 75 bytes
f=lambda m,p=[]:m[0][0]*f(zip(*p+m[1:])[1:])-f(m[1:],p+m[:1])if m else[]==p
Wolfram Language (Mathematica), 53 52 bytes
1##&@@@(t=Tuples)@#.Signature/@t[Range@Tr[1^#]&/@#]&
Unfortunately, computing the determinant of an n by n matrix this way uses O(nn) memory, which puts large test cases out of reach.
How it works
The first part, 1##&@@@(t=Tuples)@#, computes all possible products of a term from each row of the given matrix. t[Range@Tr[1^#]&/@#] gives a list of the same length whose elements are things like {3,2,1} or {2,2,3} saying which entry of each row we picked out for the corresponding product.
We apply Signature to the second list, which maps even permutations to 1, odd permutations to -1, and non-permutations to 0. This is precisely the coefficient with which the corresponding product appears in the determinant.
Finally, we take the dot product of the two lists.
If even Signature is too much of a built-in, at 73 bytes we can take
1##&@@@(t=Tuples)@#.(1##&@@Order@@@#~Subsets~{2}&/@t[Range@Tr[1^#]&/@#])&
replacing it by 1##&@@Order@@@#~Subsets~{2}&. This computes Signature of a possibly-permutation by taking the product of Order applied to all pairs of elements of the permutation. Order will give 1 if the pair is in ascending order, -1 if it's in descending order, and 0 if they're equal.
-1 byte thanks to @user202729
Jelly, 15 bytes
LŒ!ðŒcIṠ;ị"Pð€S
How it works
LŒ!ðŒcIṠ;ị"Pð€S input
L length
Œ! all_permutations
ð ð€ for each permutation:
Œc take all unordered pairs
I calculate the difference between
the two integers of each pair
Ṡ signum of each difference
(positive -> 1, negative -> -1)
; append:
ị" the list of elements generated by taking
each row according to the index specified
by each entry of the permutation
P product of everything
S sum
Why it works -- mathy version
The operator det takes a matrix and returns a scalar. An n-by-n matrix can be thought of as a collection of n vectors of length n, so det is really a function that takes n vectors from ℤn and returns a scalar.
Therefore, I write det(v1, v2, v3, ..., vn) for det [v1 v2 v3 ... vn].
Notice that det is linear in each argument, i.e. det(v1 + λw1, v2, v3, ..., vn) = det(v1, v2, v3, ..., vn) + λ det(w1, v2, v3, ..., vn). Therefore, it is a linear map from (ℤn)⊗n to ℤ.
It suffices to determine the image of the basis under the linear map. The basis of (ℤn)⊗n consists of n-fold tensor products of the basis elements of ℤn, i.e. e.g. e5 ⊗ e3 ⊗ e1 ⊗ e5 ⊗ e1. Tensor products that include identical tensors must be sent to zero, since the determinant of a matrix in which two columns are identical is zero. It remains to check what the tensor products of distinct basis elements are sent to. The indices of the vectors in the tensor product form a bijection, i.e. a permutation, in which even permutations are sent to 1 and odd permutations are sent to -1.
For example, to find the determinant of [[1, 2], [3, 4]]: note that the columns are [1, 3] and [2, 4]. We decompose [1, 3] to give (1 e1 + 3 e2) and (2 e1 + 4 e2). The corresponding element in the tensor product is (1 e1 ⊗ 2 e1 + 1 e1 ⊗ 4 e2 + 3 e2 ⊗ 2 e1 + 3 e2 ⊗ 4 e2), which we simplify to (2 e1 ⊗ e1 + 4 e1 ⊗ e2 + 6 e2 ⊗ e1 + 12 e2 ⊗ e2). Therefore:
det [[1, 2], [3, 4]]
= det(1 e1 + 3 e2, 2 e1 + 4 e2)
= det(2 e1 ⊗ e1 + 4 e1 ⊗ e2 + 6 e2 ⊗ e1 + 12 e2 ⊗ e2)
= det(2 e1 ⊗ e1) + det(4 e1 ⊗ e2) + det(6 e2 ⊗ e1) + det(12 e2 ⊗ e2)
= 2 det(e1 ⊗ e1) + 4 det(e1 ⊗ e2) + 6 det(e2 ⊗ e1) + 12 det( e2 ⊗ e2)
= 2 (0) + 4 (1) + 6 (-1) + 12 (0)
= 4 - 6
= -2
Now it remains to prove that the formula for finding the parity of the permutation is valid. What my code does is essentially find the number of inversions, i.e. the places where an element on the left is bigger than an element on the right (not necessarily consecutively).
For example, in the permutation 3614572, there are 9 inversions (31, 32, 61, 64, 65, 62, 42, 52, 72), so the permutation is odd.
The justification is that each transposition (swapping two elements) either adds one inversion or takes away one inversion, swapping the parity of the number of inversions, and the parity of the permutation is the parity of the number of transpositions needed to achieve the permutation.
Therefore, in conclusion, our formula is given by:
Why it works -- non-mathy version
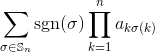
where σ is a permutation of 𝕊n the group of all permutations on n letters, and sgn is the sign of the permutation, AKA (-1) raised to the parity of the permutation, and aij is the (ij)th entry in the matrix (i down, j across).
Python 2, 95 bytes
-12 bytes thanks to Lynn.
Port of my Haskell answer.
f=lambda m:sum((-1)**i*v*f([j[:i]+j[i+1:]for j in m[1:]])for i,v in enumerate(m[0]))if m else 1
Haskell, 62 bytes
a#((b:c):r)=b*d(a++map tail r)-(a++[c])#r
_#_=0
d[]=1
d l=[]#l
Try it online! (Footer with test cases taken from @totallyhuman's solution.)
d computes the determinant using a Laplace expansion along the first column. Needs three bytes more than the permanent.
R, 32 bytes
function(m)Re(prod(eigen(m)$va))
Uses Not a Tree's algorithm of taking the eigenvalues of the matrix and taking the real part of their product.
TI-Basic (83 series), 137 133 bytes
Ans→[A]
For(N,max(dim(Ans)),2,-1
Matr▶list(Ans,N,C
1+sum(not(cumSum(not(not(∟C→R
If R>N
Then
0[A]→[A]
Else
rowSwap([A],R,N
*row(cos(π(R≠N))Ans(N,N),Ans,1
*row(-Ans(N,N)⁻¹,Ans,N
For(I,1,N
*row+(Ans(I,N),Ans,N,I→[A]
End
End
End
Ans(1,1
(Indentation is purely decorative and doesn't appear on the calculator.)
Instead of the built-in det(, does row reduction by hand. The pivots are built backwards, starting at the (n,n)th entry and going back to the (1,1)th (or is that (1,1)st?).
Every time we need to divide by a number to set the pivot to 1, we multiply the first row by the same number (possibly negated, if we needed to swap rows), so that the determinant of the matrix stays the same. (If we didn't find a pivot, we zero out the entire matrix.) As a result, at the end, the (1,1)th (1,1)st top left entry holds the determinant.
Wolfram Language (Mathematica), between 14 and 42 bytes
We've had a 3-byte built-in and a 53-byte solution that completely avoids built-ins, so here are some weirder solutions somewhere in between.
The Wolfram Language has a lot of very intense functions for decomposing matrices into products of other matrices with simpler structure. One of the simpler ones (meaning I've heard of it before) is Jordan decomposition. Every matrix is similar to a (possibly complex-valued) upper triangular matrix made of diagonal blocks with a specific structure, called the Jordan decomposition of that matrix. Similarity preserves determinants, and the determinant of a triangular matrix is the product of the diagonal elements, so we can compute the determinant with the following 42 bytes:
1##&@@Diagonal@Last@JordanDecomposition@#&
The determinant is also equal to the product of the eigenvalues of a matrix, with multiplicity. Luckily, Wolfram's eigenvalue function keeps track of multiplicity (even for non-diagonalisable matrices), so we get the following 20 byte solution:
1##&@@Eigenvalues@#&
The next solution is kind of cheating and I'm not really sure why it works. The Wronskian of a list of n functions is the determinant of the matrix of the first n-1 derivatives of the functions. If we give the Wronskian function a matrix of integers and say that the variable of differentiation is 1, somehow it spits out the determinant of the matrix. It's weird, but it doesn't involve the letters "Det" and it's only 14 bytes…
#~Wronskian~1&
(The Casoratian determinant works as well, for 1 more byte: #~Casoratian~1&)
In the realm of abstract algebra, the determinant of an n x n matrix (thought of as the map k → k that is multiplication by the determinant) is the nth exterior power of the matrix (after picking an isomorphism k → ⋀n kn). In Wolfram language, we can do this with the following 26 bytes:
HodgeDual[TensorWedge@@#]&
And here's a solution that works for positive determinants only. If we take an n-dimensional unit hypercube and apply a linear transformation to it, the n-dimensional "volume" of the resulting region is the absolute value of the determinant of the transformation. Applying a linear transformation to a cube gives a parallelepiped, and we can take its volume with the following 39 bytes of code:
RegionMeasure@Parallelepiped[Last@#,#]&
MATL, 3 bytes / 5 bytes
With built-in function
&0|
Without built-in
Thanks to Misha Lavrov for pointing out a mistake, now corrected
YvpYo
This computes the determinant as the product of the eigenvalues, rounded to the closest integer to avoid floating-point inaccuracies.
Yv % Implicit input. Push vector containing the eigenvalues
p % Product
Yo % Round. Implicit display
Jelly, 2 bytes
ÆḊ
Currently only built-in solution. :( Looks like others have managed to find out interesting non-built-in solutions.
Octave, 28 bytes
@(x)round(prod(diag(qr(x))))
This uses the QR decomposition of a matrix X into an orthgonal matrix Q and an upper triangular matrix R. The determinant of X is the product of those of Q and R. An orthogonal matrix has unit determinant, and for a triangular matrix the determinant is the product of its diagonal entries. Octave's qr function called with a single output gives R.
The result is rounded to the closest integer. For large input matrices, floating-point inaccuracies may produce an error exceeding 0.5 and thus produce a wrong result.
Jelly, 24 bytes
œcL’$ṚÑ€
J-*×Ḣ€×ÇSµḢḢ$Ṗ?
Explanation
œcL’$ṚÑ€ Helper Link; get the next level of subdeterminants (for Laplace Expansion)
œc Combinations without replacement of length:
L’$ Length of input - 1 (this will get all submatrices, except it's reversed)
Ṛ Reverse the whole thing
Ñ€ Get the determinant of each of these
J-*×Ḣ€×ÇSµḢḢ$Ṗ? Main Link
? If the next value is truthy
Ṗ Remove the last element (truthy if the matrix was at least size 2)
J-*×Ḣ€×ÇSµ Then expand
ḢḢ$ Otherwise, get the first element of the first element (m[0][0] in Python)
J [1, 2, ..., len(z)]
-* (-1 ** z) for each z in the length range
× Vectorizing multiply with
Ḣ€ The first element of each (this gets the first column); modifies each row (makes it golfier yay)
×Ç Vectorizing multiply with the subdeterminants
S Sum
-2 bytes thanks to user202729's solution
TI-Basic, 2 bytes
det(Ans
Ah, well.
Please don't upvote trivial answers.
As a high school student (who's forced to own one of these calculators), this function is hella useful so...
Octave, 30 bytes
@(x)-prod(diag([~,l,~]=lu(x)))
or, the boring 4 byte solution (saved 6 bytes thanks to Luis Mendo (forgot the rules regaring builtin functions)):
@det
Explanation:
Coming up! :)
Wolfram Language (Mathematica), 3 bytes
Det
Per the meta consensus, mainly upvote nontrivial solutions that take effort to write.