| Bytes | Lang | Time | Link |
|---|---|---|---|
| 236 | brainfuck | 250329T021045Z | Weird Gl |
| 021 | Uiua | 250329T155111Z | janMakos |
| 1954 | ☾ | 250313T211506Z | Ganer |
| 074 | AWK | 250312T184449Z | xrs |
| 412 | Bespoke | 250312T035553Z | Josiah W |
| 023 | Uiua | 250202T150842Z | noodle p |
| 040 | AGL | 250216T001736Z | ErikDaPa |
| 076 | JavaScript V8 | 250214T004408Z | Weird Gl |
| 019 | Vyxal 3 | 250213T200256Z | pacman25 |
| 079 | JavaScript Node.js | 250202T160850Z | l4m2 |
| 037 | J | 171027T102651Z | FrownyFr |
| 051 | Retina 0.8.2 | 250203T184754Z | Unrelate |
| 123 | Retina | 170902T151151Z | Neil |
| 013 | Jelly | 250203T170941Z | Unrelate |
| 065 | Zsh | 191009T210214Z | GammaFun |
| 063 | ><> Fish | 230126T073938Z | mousetai |
| 036 | Pip | 230125T200903Z | Baby_Boy |
| 114 | Julia 1.0 | 230125T172422Z | Ashlin H |
| 023 | MATL | 170902T181151Z | Luis Men |
| 011 | Japt R | 201110T162753Z | Shaggy |
| 091 | Hexagony | 201103T031849Z | Undersla |
| 017 | 05AB1E | 191009T183638Z | Dorian |
| 063 | Powershell | 181009T135852Z | mazzy |
| 062 | Ruby n | 191009T003724Z | Value In |
| 037 | GolfScript | 181009T201339Z | JosiahRy |
| 012 | Stax | 181009T174309Z | recursiv |
| 095 | R | 181009T170546Z | J.Doe |
| 117 | R | 170905T133405Z | Giuseppe |
| 163 | Rust | 181009T154749Z | Endenite |
| 101 | Kotlin | 181009T143608Z | mazzy |
| 028 | K ngn/k | 180328T230543Z | ngn |
| 152 | Java 10 | 170904T122902Z | Kevin Cr |
| 020 | APL Dyalog Classic | 180205T010127Z | ngn |
| 015 | Charcoal | 171221T130602Z | Neil |
| 121 | PHP | 171028T064120Z | Jo. |
| 045 | q/kdb+ | 170904T135621Z | mkst |
| 197 | C++ | 170909T142259Z | HatsuPoi |
| 085 | Python 3 | 170906T130358Z | Felipe N |
| 129 | Kotlin | 170906T093642Z | jrtapsel |
| 101 | Mathematica | 170906T003656Z | hftf |
| 063 | C gcc | 170905T191909Z | MD XF |
| 063 | ><> | 170905T121650Z | Sok |
| 018 | 05AB1E | 170902T193605Z | scottine |
| 016 | Japt | 170902T181130Z | Justin M |
| 080 | Retina | 170903T152917Z | FryAmThe |
| 019 | Jelly | 170902T142822Z | Erik the |
| 069 | C gcc | 170903T083245Z | scottine |
| 073 | Haskell | 170902T185840Z | Cristian |
| 021 | Golfscript | 170903T045050Z | Josiah W |
| 017 | Husk | 170902T140354Z | H.PWiz |
| 072 | Mathematica | 170902T232826Z | JungHwan |
| 034 | Dyalog APL | 170902T211135Z | Adalynn |
| 079 | JavaScript ES6 | 170902T202239Z | edc65 |
| 087 | JavaScript ES6 | 170902T174937Z | Justin M |
| 184 | Mathematica | 170902T160358Z | ZaMoC |
| 015 | Husk | 170902T151451Z | Zgarb |
| 092 | Python 2 | 170902T143708Z | Halvard |
| 018 | Pyth | 170902T134252Z | Erik the |
| 044 | Perl 5 | 170902T133117Z | Dom Hast |
| 022 | SOGL V0.12 | 170902T140259Z | dzaima |
| 021 | Jelly | 170902T133050Z | Leaky Nu |
brainfuck, 332 236 bytes
++++++++[->++++++++>>>>++++>+<<<<<<]>+<,[[->->>+>+<<<<]>[>]>>>.<<<++++++++[->>>----<<<]>>>[,<<++++++++[->>>----<<<]>>>]<<<++++++++[->>>++++<<<]>>[-<<<<+>>>>]<[-<<+>>]>>>>------[>>]<[++.--<<<<+++++++++++++[-<-->]>>>>>++++>]<----<<<<<<+<]
This program is not optimal, since it does a lot of backtracking, but it's still pretty nice.
Uiua, 21 bytes
⊜(&p⬚@ ⌝⊏⊸-@A)\+⊂1⊸⧈≤
Explanation
⊸⧈≤ # Mask of decreases in order
\+⊂1 # Convert to mask of increasing regions
⊜( ) # For each region...
⊸-@A # Each letter's alphabet index
⬚@ ⌝⊏ # Put in string at that index, filled with spaces
&p # Print the line
☾, 19 chars (54 bytes)
⨝<´ᐖABC⬤∖⟞⨁ᐸ⨝𝗻
Note: ☾ uses a custom font, but you can run this code in the Web UI
For context, here is what the first two operations are actually doing:
AWK, 74 bytes
{for(i=j=1;j<=NF;)printf(i>26&&i=1)?RS:sprintf("%c",64+i++)~$j?$(j++):" "}
{for(i=j=1;j<=NF;) # down line of chars
printf(i>26&&i=1)? # abuse to avoid for loop and extra print
RS: # new line after each loop
sprintf("%c",64+i++)~$j # compare char to alphabet
?$(j++) # match and move to next char
:" "} # or print space
Bespoke, 412 bytes
GRID:A-B-C
letters forming words go in grid
to show examples for it:o,pelican,crested so smooth.god,oh,of breeze
blackout poetry utilizes letters of actual text to do words that go in words
but if you do blackout poetry alphabet grids,it gets simpler to see
it all is spelled somewhere here in my grids
looping all values of ABC to do check when char is equal
spacings or letters go out,as a repetition renews it
O, pelican, crested so smooth. God, oh, of breeze!
This program keeps track of an index from 1 to 26, representing the current letter. Thanks to ASCII being designed with the alphabet in mind, the 1-based index of an uppercase (or lowercase) letter can be found by taking its ASCII code modulo 32; this is what the index is compared to.
Uiua, 25 24 23 bytes
⊕(&p⬚@ ⌝▽°⊚⊸-@A)\+⊂0⊸⧈≤
Try it: Uiua pad
Explanation: The input is grouped into lines, and each group is formatted with spaces.
"CODEGOLF"
⊸⧈≤ # Compare each overlapping pair of characters (A ≤ B, 0/1)
[0 1 0 0 0 1 1]
\+⊂0 # Cumulative sums starting with 0
[0 0 1 1 1 1 2 3]
⊕□ # Group the input by these indices
{"CO" "DEGO" "L" "F"}
# The following happens to each group; consider the second
"DEGO"
⊸-@A # Index of each in the alphabet
"DEGO"
[3 4 6 14]
°⊚ # Boolean array with ones at those indices
"DEGO"
[0 0 0 1 1 0 1 0 0 0 0 0 0 0 1]
⬚@ ⌝▽ # Insert values at those ones, filling with spaces
" DE G O"
&p # Print with newline
AGL, 40 bytes
- a programming language i made! check out the link to my github repo.
.s#2{>!}/0:+{+}\*{"[^":+']+va|:' sr!p!}%
Explanation:
.s#2{>!}/0:+{+}\*{"[^":+']+va|:' sr!p!}%
.s# => convert to codepoints
2{>!}/0:+ => pairwise ≤ then add 0 to the beginning of list
{+}\* => split for each true value
{"[^":+']+ }% => '[^{string}]' (used for regex expr)
va|:' sr! => replace regex expr in 'A...Z' with spaces
p! => finally print
JavaScript (V8), 76 bytes
f=(s,i=j=1,c=s[j-1])=>c?(i?parseInt(c,36)-9^i?" ":++j&&c:`
`)+f(s,++i%27):""
Really proud with this answer. This question has many JS answers, so managing to write a small answer for once is really nice :)
JavaScript (Node.js), 79 bytes
f=(x,n=65)=>x.charCodeAt()-n++?n>91?`
`+f(x):' '+f(x,n):x&&x[0]+f(x.slice(1),n)
JavaScript (Node.js), 87 bytes
x=>x.replace(/./g,s=>s.padStart(parseInt(s,36)-9).padEnd(26)+`
`).replace(/\W{27}/g,'')
Retina 0.8.2, 60 51 bytes
S`\B
%(T01~`L`_o
}`$
Z
%O`.
(.)(?!\1)
\b \W{27}?
Still feels a wee bit hacky.
Explanation:
S`\B
Split the input on non-word-boundaries, into one letter per line.
%(T01~`L`_o
}`$
Z
Alphabet generator, executed per-line with %, and slightly modified with a limit 01~ to leave the first character un-transliterated--appends ABCDEFGHIJKLMNOPQRSTUVWXYZ to each line.
%O`.
Sort the characters of each line.
(.)(?!\1)
Replace any letter not followed by a copy of itself with a space.
\b \W{27}?
Delete any single space after a word boundary--since the previous stage never deletes any characters, each line is 27 characters including the duplicate letter from the input.
If the space is followed by 27 spaces or newlines, delete those as well, in order to consolidate lines as appropriate: a line's letter is earlier than the next line's letter iff it has strictly fewer leading spaces \$l_0\$ than the next line \$l_1\$, and the number of trailing spaces (excluding the extraneous one already matched by \b ) \$t_0 = 25 - l_0\$, so \$ l_0 < l_1 \leftrightarrow 25 < t_0 + l_1\$, and \W{27} matches a sum of exactly 26 trailing and leading spaces plus the one newline in between them (and matches no more so as to keep the letters aligned to the grid).
Retina, 130 126 123 bytes
$
¶Z
{T`L`_o`.+$
}`$
Z
+`(?<=(.)*)((.).*¶(?<-1>.)*(?(1)(?!)).+\3.*$)
$2
(?<=(.)*)((.).*¶(?<-1>.)*(?<-1>\3.*$))
¶$2
}`¶.*$
Try it online! Edit: Saved 4 7 bytes by using a better alphabet generator. Explanation:
$
¶Z
{T`L`_o`.+$
}`$
Z
Append the alphabet.
+`(?<=(.)*)((.).*¶(?<-1>.)*(?(1)(?!)).+\3.*$)
$2
Align as many letters as possible with their position in the alphabet.
(?<=(.)*)((.).*¶(?<-1>.)*(?<-1>\3.*$))
¶$2
Start a new line before the first letter that could not be aligned.
}`¶.*$
Delete the alphabet, but then do everything over again until there are no misaligned letters.
Jelly, 13 bytes
»ƑƝk¹ØA¹⁶e?þY
Shame ⁶ḟ¡ needs extra massaging to work, tying with »ƑƝk¹ØA⁶€ḟ¡þY or coming out longer like »ƑƝkµ⁶ɓḟ¡þYøØA or »ƑƝkµ⁶µḟ¡@ⱮØA)Y.
Ɲ For every pair of adjacent letters,
Ƒ is the first equal to
» their maximum?
k¹ Partition the letters after the positions of truthy results.
ØA þ For each partition, for each ['A' .. 'Z']:
¹ Leave the letter unchanged
e? if it's in the partition, else
⁶ replace it with a space.
Y Join rows on newlines.
Jelly, 13 bytes
<Ɲ¬kfȯ⁶ɗⱮ€ØAY
Just a port of Erik the Outgolfer's solution with modern builtins.
Ɲ For every pair of adjacent elements,
< is the first strictly less than the second?
¬k Partition the letters after the positions of falsy results.
€ For each partition,
ɗⱮ ØA for each ['A' .. 'Z']:
f Filter the partition to the letter,
ȯ⁶ and replace with a space if empty.
Y Join the rows on newlines.
Zsh, 65 bytes
-4 bytes thanks to @pxeger, -2 bytes thanks to @roblogic
repeat $#1;echo&&for y ({A-Z})printf ${(Ml:1:)1[1]%$y}&&1=${1#$y}
Try it online!
Try it online!
Try it online!
Append to $s a (M) matched letter, (l:1:) left-padded to one character, then remove the letter if it matches the start of $1.
><> (Fish), 63 bytes
0i:0(?;$:r:@\
'A'-=?\' 'o$\
oi$c3.\
:?!v >$:20.\1+d2*%
\ao/
Ties the other ><> answer but a very different approach
Pip, 36 bytes
Wa{YsX26b:0Fiz{iQ@a?y@b::POau++b}Py}
Uses lowercase input
How?
Wa{YsX26b:0Fiz{iQ@a?y@b::POau++b}Py} : One arg, string
a a a : First input, string
Wa{ } : While a isn't empty
s : Space character
X26 : Repeat 26 times
Y : Yank value
b:0 : Set b to zero
Fiz{ } : For each character in z(lowercase alphabet)
? : If
i : Letter
Q : Is equal to
@a : The first letter in the input string
:: : Swap the values of
y@b : Char at index b of y
POa : Head a; pop the first value of a
u : Nil(Terminate else)
++b : Iterate b
P : Print; output with newline
y : Line
Julia 1.0, 114 bytes
~w=(s=[w...];r="";i=j=0;while j<length(w) s[j+1]==['A':'Z';][i+=1] ? r*=s[j+=1] : r*=" ";i>25&&(i=0;r*="\n")end;r)
This solution builds the string character by character. Below is an ungolfed version:
function ~(w)
r=""
i=1
j=1
s=[w...]
a=['A':'Z';]
while j<=length(w)
if s[j] == a[i]
r*=s[j]
j=j+1
else
r*=" "
end
i=i+1
if i==27
i=1
r*="\n"
end
end
r
end
The following alternative approach builds a string of spaces for each character and inserts newlines afterwards. Strings are immutable in Julia, but if there is a more efficient way to assemble the strings, this method might be made shorter. Additionally, I couldn't find an efficient way to interleave Strings or Characters, since this relies on using the array transpose ', which only works on numeric types.
Julia 1.0, 166 bytes (alternate approach)
function f(s)
v=[s...]
r=" ".^(((q=diff(['@';v])).+25).%26).*string.(v)
map(i -> (q[i]<1 && (j='Z'-v[i-1];r[i]=r[i][1:j]*"\n"*r[i][j+1:end])),1:length(r))
join(r)
end
MATL, 24 23 bytes
''jt8+t1)wdh26X\Ys(26e!
Uses lowercase letters.
Try it at MATL Online!
Explanation
'' % Push empty string
jt % Push input string. Duplicate
8+ % Add 8 to each char (ASCII code). This transforms 'a' 105,
% 'b' into 106, which modulo 26 correspond to 1, 2 etc
t1) % Duplicate. Get first entry
wd % Swap. COnsecutive differences.
h % Concatenate horizontally
26X\ % 1-based modulo 26. This gives a result from 1 to 26
Ys % Cumulative sum
( % Write values (converted into chars) at specified positions
% of the initially empty string
26e % Reshape into a 26-row char matrix, padding with char 0
! % Transpose. Implicitly display. Char 0 is shown as space
Japt -R, 11 bytes
;ó< £BôkX ¸
;ó< £BôkX ¸ :Implicit input of string
ó< :Partition between characters where the first is < the second
£ :Map each X
; B : Uppercase alphabet
ô : Split at characters that return falsey (empty string)
kX : When the characters in X are removed
¸ : Join with spaces
:Implicit output joined with newlines
Hexagony, 91 bytes
A"$>}\$<>~,<.'~<\.';<.>$${}\../<..>=<...-/.$/=*=32;.>~<>"){-\}.>_{A}\\../010<$..>;=~<$@{{Z'
More readably:
A " $ > } \
$ < > ~ , < .
' ~ < \ . ' ; <
. > $ $ { } \ . .
/ < . . > = < . . .
- / . $ / = * = 3 2 ;
. > ~ < > " ) { - \
} . > _ { A } \ \
. . / 0 1 0 < $
. . > ; = ~ <
$ @ { { Z '
And with color paths:
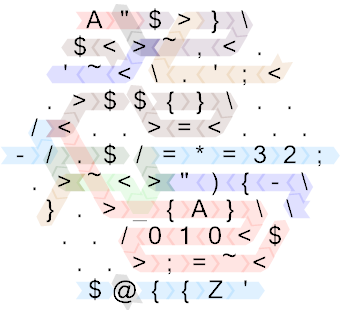
05AB1E, 21 19 17 bytes
Çü@0šÅ¡vð₂×yAykǝ,
Ç push a list of ascii values of the input [84, 69, 83, 84]
ü@ determine which letter is >= the next letter [1, 0, 0]
0š prepend a 0 (false) to that list [0, 1, 0, 0]
Å¡ split input on true values [["T"], ["E", "S", "T"]]
v for each list entry
ð₂× push 26 spaces
y push list entry (letters)
Ayk push the positions of that letters in the alphabet
ǝ replace characters c in string a with letters b
, print the resulting string
implicitly close for-loop
Powershell, 70 63 bytes
-7 bytes thanks @Veskah
$args|%{if($_-le$p){$x;rv x}
$x=("$x"|% *ht($_-65))+($p=$_)}
$x
Explanation:
For each character in the splatted argument:
- Output string
$xand clear$xvalue (rvis alias for Remove-Variable), if a code of the current character less or equivalent (-le) to a code of the previous character. - Append spaces and the current character to
$x, store it to$x. Also it freshes a previous character value.
Output last $x.
Ruby -n, 62 bytes
Scans the input string for sequences of increasing letters, and for each sequence, replace letters not in the sequence with spaces.
g=*?A..?Z
$_.scan(/#{g*??}?/){puts g.join.tr"^#$&"," "if$&[0]}
GolfScript, 37 bytes
64:a;{.a>{}{'
'\64:a;}if.a-(' '*\:a}%
I did a Golfscript one under a different name, but it had incorrect output.
Stax, 12 bytes
ü→Δe-Y─▲99╣w
Unpacked, ungolfed, and commented, it looks like this.
{<!} block tests if one value is >= another
) use block to split input into partitions by testing adjacent pairs
m map partitions using rest of the program and output
zs put a zero-length array under the partition in the stack
F for each letter in the array, run the rest of the program
65- subtract 65 (ascii code for 'A')
_& set the specified index to the character, extending the array if necessary
R, 95 bytes
Just run through the upper case alphabet repeatedly while advancing a counter by 1 if you encounter the letter in the counter position of the word and printing out the letter, a space otherwise.
function(s)while(F>""){for(l in LETTERS)cat("if"((F=substr(s,T,T))==l,{T=T+1;l}," "));cat("
")}
R, 129 117 bytes
function(s){z={}
y=diff(x<-utf8ToInt(s)-64)
z[diffinv(y+26*(y<0))+x[1]]=LETTERS[x]
z[is.na(z)]=" "
write(z,1,26,,"")}
Explanation (ungolfed):
function(s){
z <- c() # initialize an empty vector
x <- utf8ToInt(s)-64 # map to char code, map to range 1:26
y <- diff(x) # successive differences of x
idx <- cumsum(c( # indices into z: cumulative sum of:
x[1], # first element of x
ifelse(y<=0,y+26,y))) # vectorized if: maps non-positive values to themselves + 26, positives to themselves
z[idx] <- LETTERS[x] # put letters at indices
z[is.na(z)] <- " " # replace NA with space
write(z,"",26,,"") # write z as a matrix to STDOUT ("") with 26 columns and empty separator.
Rust, 163 bytes
|s:&str|{let mut s=s.bytes().peekable();while s.peek().is_some(){for c in 65..91{print!("{}",if Some(c)==s.peek().cloned(){s.next();c}else{32}as char)}println!()}}
Explanation
|s:&str|{ // Take a single parameter s (a string)
let mut s=s.bytes().peekable(); // Turn s into a peekable iterator
while s.peek().is_some(){ // While s is nonempty:
for c in 65..91{ // For every c in range [65, 91) (uppercase alphabet):
print!("{}",if Some(c)==s.peek().cloned(){ // If the next character in s is the same as c:
s.next(); // Advance the iterator
c // Print c as a character
} else { // Else:
32 // Print a space
} as char) //
} //
println!() // Print a newline
}
}
Kotlin, 101 bytes
Port of the Powershell.
{s:String->var p=' '
var x=""
var r=""
s.map{c->if(c<p){r+=x+"\n";x=""}
x=x.padEnd(c-'A')+c
p=c}
r+x}
K (ngn/k), 29 28 bytes
{{x@x?`c$65+!26}'(&~>':x)_x}
{ } function with argument x
>':x for each char, is it greater than the previous char?
~ negate
& where (at which indices) do we have true
( )_x cut x at those indices, return a list of strings
{ }' for each of those strings
`c$65+!26
the English alphabet
x? find the index of the first occurrence of each letter in x, use 0N (a special "null" value) if not found
x@ index x with that; indexing with 0N returns " ", so we get a length-26 string in which the letters from x are at their alphabetical positions and everything else is spaces
Java 10, 161 159 152 bytes
s->{var x="";int p=0;for(var c:s)x+=p<(p=c)?c:";"+c;for(var y:x.split(";"))System.out.println("ABCDEFGHIJKLMNOPQRSTUVWXYZ".replaceAll("[^"+y+"]"," "));}
-2 bytes thanks to @Nevay.
-7 byte printing directly instead of returning a String, and converting to Java 10.
Explanation:"
s->{ // Method with String parameter and no return-type
var x=""; // Temp-String
int p=0; // Previous character (as integer), starting at 0
for(var c:s) // Loop (1) over the characters of the input
x+=p<(p=c)? // If the current character is later in the alphabet
// (replace previous `p` with current `c` afterwards)
c // Append the current character to Temp-String `x`
: // Else:
";"+c; // Append a delimiter ";" + this character to Temp-String `x`
for(var y:x.split(";")) // Loop (2) over the String-parts
System.out.println( // Print, with trailing new-line:
"ABCDEFGHIJKLMNOPQRSTUVWXYZ"
// Take the alphabet,
.replaceAll("[^"+y+"]"," "));}
// and replace all letters not in the String-part with a space
The first part of the method splits the input-word into parts with a delimiter.
For example: CODEGOLF → CO;DEGO;L;F or BALLOON → B;AL;LO;O;N.
The second part loops over these parts, and uses the regex [^...] to replace everything that isn't matched with a space.
For example .replaceAll("[^CO]"," ") leaves the C, and O, and replaces everything else with a space.
Charcoal, 15 bytes
Fθ«J⌕αι⁺ⅉ‹⌕αιⅈι
Try it online! Link is to verbose version of code. Explanation:
θ Input string
F « Loop over characters
α α Uppercase letters predefined variable
ι ι Current character
⌕ ⌕ Find index
ⅈ Current X co-ordinate
‹ Compare
ⅉ Current Y co-ordinate
⁺ Sum
J Jump to aboslute position
ι Print current character
PHP, 121 bytes
<?$p=$argv[1];$b=substr;while($p){for($i=A;$i!=AA;$i++){if($p[0]==$i){echo$b($p,0,1);$p=$b($p,1);}else echo" ";}echo'
';}
q/kdb+, 48 45 bytes
Solution:
-1{@[26#" ";.Q.A?x;:;x]}@/:(0,(&)(<=':)x)_x:;
Note: Link is to a K (oK) port of this solution as there is no TIO for q/kdb+.
Examples:
q)-1{@[26#" ";.Q.A?x;:;x]}@/:(0,(&)(<=':)x)_x:"STACKEXCHANGE";
ST
A C K
E X
C H
A N
G
E
q)-1{@[26#" ";.Q.A?x;:;x]}@/:(0,(&)(<=':)x)_x:"BALLOON";
B
A L
L O
O
N
Explanation:
Q is interpreted right-to-left. The solution is split into two parts. First split the string where the next character is less than or equal to the current:
"STACKEXCHANGE" -> "ST","ACK","EX","CH","AN","G","E"
Then take a string of 26 blanks, and apply the input to it at the indices where the input appears in the alphabet, and print to stdout.
"__________________________" -> __________________ST______
Breakdown:
-1{@[26#" ";.Q.A?x;:;x]}each(0,where (<=':)x) cut x:; / ungolfed solution
-1 ; / print to stdout, swallow return value
x: / store input as variable x
cut / cut slices x at these indices
( ) / do this together
(<=':)x / is current char less-or-equal (<=) than each previous (':)?
where / indices where this is true
0, / prepended with 0
each / take each item and apply function to it
{ } / lambda function with x as implicit input
@[ ; ; ; ] / apply[variable;indices;function;arguments]
26#" " / 26 take " " is " "...
.Q.A?x / lookup x in the uppercase alphabet, returns indice(s)
: / assignment
x / the input to apply to these indices
Notes:
- -3 bytes by replacing prev with the K4 version
C++, 202 197 bytes
-5 bytes thanks to Zacharý
#include<iostream>
#include<string>
using c=std::string;void f(c s){std::cout<<c(s[0]-65,32)<<s[0];for(int i=1;i<s.size();++i)std::cout<<(s[i]>s[i-1]?c(s[i]-s[i-1]-1,32):"\n"+c(s[i]-65,32))<<s[i];}
Python 3, 87 85 bytes
def f(s,l=65):c,*t=s;o=ord(c)-l;return o<0and'\n'+f(s)or' '*o+c+(t and f(t,o-~l)or'')
Kotlin, 133 131 129 bytes
fun r(s:String){var c=0
while(0<1){('A'..'Z').map{if(c==s.length)return
if(s[c]==it){print(s[c])
c++}else print(" ")}
println()}}
Explained
fun r(s: String) {
// Current character
var c = 0
// Keep going until the end of the string
while (0 < 1) {
// Go through the letters
('A'..'Z').map{
// If the word is done then stop
// Have to check after each letter
if (c == s.length) return
// If we are at the right letter
if (s[c] == it) {
// Print it
print(s[c])
// Go to the next letter
c++
// Otherwise print space
} else print(" ")
}
// Put a newline between the lines
println()
}
}
Test
fun main(args:Array<String>)=r("CODEGOLF")
Edit: Ran through my compressor, saved 2 bytes.
Mathematica, 101 bytes
StringRiffle[
Alphabet[]/.#->" "&/@
(Except[#|##,_String]&@@@
Split[Characters@#,#==1&@*Order]),"
",""]&
Split the input into strictly increasing letter sequences, comparing adjacent letters with Order. If Order[x,y] == 1, then x precedes y in the alphabet and thus can appear on the same line.
For each sequence of letters, create a pattern to match strings Except for those letters; #|## is a shorthand for Alternatives. Replace letters of the Alphabet that match the pattern with spaces.
Illustration of the intermediate steps:
"codegolf";
Split[Characters@#,#==1&@*Order] &@%
Except[#|##,_String]&@@@ #&@%
Alphabet[]/.#->" "&/@ %
{{"c", "o"}, {"d", "e", "g", "o"}, {"l"}, {"f"}}
{Except["c" | "c" | "o", _String],
Except["d" | "d" | "e" | "g" | "o", _String],
Except["l" | "l", _String],
Except["f" | "f", _String]}
{{" "," ","c"," "," "," "," "," "," "," "," "," "," "," ","o"," "," "," "," "," "," "," "," "," "," "," "},
{" "," "," ","d","e"," ","g"," "," "," "," "," "," "," ","o"," "," "," "," "," "," "," "," "," "," "," "},
{" "," "," "," "," "," "," "," "," "," "," ","l"," "," "," "," "," "," "," "," "," "," "," "," "," "," "},
{" "," "," "," "," ","f"," "," "," "," "," "," "," "," "," "," "," "," "," "," "," "," "," "," "," "," "}}
C (gcc), 91 63 bytes
-28 thanks to ASCII-only
_;f(char*s){for(_=64;*s;)putchar(++_>90?_=64,10:*s^_?32:*s++);}
Previous:
i,j;f(char*s){while(s[i]){for(j=65;j<91;j++)s[i]==j?putchar(s[i++]):printf(" ");puts("");}}
Yes, there's a shorter solution, but I noticed after I wrote this one... Try it online!
><>, 63 bytes
d5*v
(?;\i:0
~{?\}::{::}@=::{$" ["a${=:}?$~@?$~o10d2*-{?$~{+}}?
Input is expected in uppercase.
05AB1E, 18 bytes
ćIgµ¶?AvDyÊið?ë¼?ć
Got trouble with 05AB1E ć (extract 1) leaving an empty string/list on the stack after the last element is extracted. This solution would be 1-2 bytes shorter if it weren't for that.
ćIgµ¶?AvDyÊið?ë¼?ć Implicit input
ć Extract the 1st char from the string
Igµ While counter != length of the string
¶? Print a newline
Av For each letter of the lowercased alphabet
DyÊ Is the examined character different from the current letter?
ið? If true, then print a space
ë¼?ć Else increment the counter, print the letter and push
the next character of the string on the stack
Japt, 18 16 bytes
-2 bytes thanks to @Shaggy
;ò¨ £B®kX ?S:Z
·
Uppercase input only.
Explanation
;
Switch to alternate variables, where B is the uppercase alphabet.
ò¨
Split the input string between characters where the first is greater than or equal to (¨) the second.
£
Map each partition by the function, where X is the current partition.
B®
Map each character in the uppercase alphabet to the following, with Z being the current letter.
kX
Remove all letters in the current partition from the current letter. If the current letter is contained in the current partition, this results in an empty string.
?S:Z
If that is truthy (not an empty string), return a space (S), otherwise return the current letter.
·
Join the result of the previous line with newlines and print the result.
Retina, 80 bytes
^
;¶
{`;.*
¶;ABCDEFGHIJKLMNOPQRSTUVWXYZ
¶¶
¶
)+`;(.*)(.)(.*¶)\2
$.1$* $2;$3
;.*
There is always exactly one leading newline. The code somewhat clunkily prepends the word with the alphabet along with a marker (semicolon). It then moves the marker up to the first letter of the word, while changing all other letters it passes into spaces. It also removes the first letter of the word. It repeats this until the first letter of the word isn't after the marker anymore. Then it clears that marker and the rest of the alphabet, and replaces it with a new line and the alphabet with a marker again. It keeps repeating this until the input word is empty, then it cleans up the last alphabet and marker, leaving the desired output.
C (gcc), 69 bytes
i;f(char*s){for(i=64;*s;putchar(*s^i?32:*s++))i+=i^90?1:puts("")-26;}
Haskell, 81 74 73 bytes
q@(w:y)!(x:z)|w==x=x:y!z|1<2=min ' 'x:q!z
x!_=x
a=['A'..'Z']++'\n':a
(!a)
Saved 1 byte thanks to Laikoni!
Haskell Hugs optimizations
The Hugs interpreter allows me to save one more byte by doing
(!cycle$['A'..'Z']++"\n")instead of:(!cycle(['A'..'Z']++"\n")), but GHC does not like the former. (This is now obsolete; Laikoni already rewrote that line in a way that saved 1 byte.)Apparently, Hugs also does not require parentheses around the list pattern matcher, so I could save two more bytes going from:
q@(w:y)!(x:z)toq@(w:y)!x:z.
Golfscript, 22 21 bytes
-1 byte thanks to careful final redefining of the n built-in.
{.n>{}{'
'\}if:n}%:n;
Explanation (with a slightly different version):
{.n>{}{"\n"\}if:n}%:n; # Full program
{ }% # Go through every character in the string
.n> if # If ASCII code is greater than previous...
# (n means newline by default, so 1st char guaranteed to fit)
{} # Do nothing
{"\n"\} # Else, put newline before character
:n # Redefine n as the last used character
:n; # The stack contents are printed at end of execution
# Literally followed by the variable n, usually newline
# So because n is by now an ASCII code...
# ...redefine n as the new string, and empty the stack
Husk, 22 21 19 17 bytes
-2 bytes thanks to Zgarb (and a new language feature)
mȯΣẊṠ:ȯR' ←≠:'@ġ>
Explanation
ġ> Group into increasing sublists
mȯ To each sublist apply the following three functions
:'@ ¹Append '@' (The character before 'A') to the start
Ẋ ²Apply the following function to all adjacent pairs
≠ Take the difference of their codepoints
← Minus 1
ȯR' Repeat ' ' that many times
Ṡ: Append the second argument to the end.
Σ ³concatenate
Mathematica, 73 71 72 bytes
Print@@(Alphabet[]/.Except[#|##,_String]->" ")&@@@Split[#,Order@##>0&];&
(* or *)
Print@@@Outer[If[!FreeQ@##,#2," "]&,Split[#,Order@##>0&],Alphabet[],1];&
sacrificed a byte to fix the output
Takes a list of lower case characters (which is a "string" per meta consensus).
Usage
f = (Print@@(Alphabet[]/.Except[#|##,_String]->" ")&@@@Split[#,Order@##>0&];&)
f[{"c", "o", "d", "e", "g", "o", "l", "f"}]
c o de g o l f
Dyalog APL, 47 37 34 bytes
{↑{⍵∘{⍵∊⍺:⍵⋄' '}¨⎕A}¨⍵⊂⍨1,2≥/⎕A⍳⍵}
How? (argument is ⍵)
⍵⊂⍨1,2≥/⎕A⍳⍵, split into alphabetically ordered segments{...}¨, apply this function to each letter (argument is⍵):⎕A, the alphabet...¨, apply this function to each argument (argument is⍵):⍵∘, pass⍵in as the left argument (⍺) to the function:{⍵∊⍺:⍵⋄' '}, if⍵is in⍺, then return⍵, otherwise a space. This function is what creates a line of text.
↑, turn into an array (equivalent of adding the newlines)
JavaScript (ES6), 79
Edit As a leading newline is accepted, I can save 2 bytes
s=>eval("for(o='',v=i=0;c=s.charCodeAt(i);v%=27)o+=v++?c-63-v?' ':s[i++]:`\n`")
For 1 byte more, I can accept lowercase or uppercase input:
s=>eval("for(o='',v=i=0;c=s[i];v%=27)o+=v++?parseInt(c,36)-8-v?' ':s[i++]:`\n`")
Less golfed
s=>{
var i,o,c,v
for(o = '', v = 1, i = 0; c = s.charCodeAt(i); v %= 27)
o += v++ ? c-63-v ? ' ' : s[i++] : '\n'
return o
}
Test
f=s=>eval("for(o='',v=i=0;c=s.charCodeAt(i);v%=27)o+=v++?c-63-v?' ':s[i++]:`\n`")
function update() {
var i=I.value
i=i.replace(/[^A-Z]/gi,'').toUpperCase()
O.textContent=f(i)
}
update()<input id=I value='BALLOON' oninput='update()' >
<pre id=O></pre>JavaScript (ES6), 87 bytes
f=([...s])=>s[0]?(g=i=>i>35?`
`+f(s):(i-parseInt(s[0],36)?" ":s.shift())+g(i+1))(10):""
Accepts uppercase or lowercase input. Output match the case of the input.
Tests
f=([...s])=>s[0]?(g=i=>i>35?`
`+f(s):(i-parseInt(s[0],36)?" ":s.shift())+g(i+1))(10):""
;O.innerText=["CODEGOLF","STACKEXCHANGE","F","ZYXWVUTSRQPONMLKJIHGFEDCBA","ANTIDISESTABLISHMENTARIANISM"]
.map(f).join("=".repeat(26)+"\n")<pre id=O>Mathematica, 184 bytes
(t=Characters@#;s=Flatten@Table[Alphabet[],(l=Length)@t];q=1;For[i=1,i<=l@s,i++,If[s[[i]]!=t[[q]],s[[i]]=" ",q++];If[q>l@t,q--;t[[q]]=0]];StringRiffle[StringPartition[""<>s,26],"\n"])&
Husk, 15 bytes
TṪS`?' €…"AZ"ġ>
Explanation
TṪS`?' €…"AZ"ġ> Implicit input, e.g. "HELLO"
ġ> Split into strictly increasing substrings: x = ["H","EL","LO"]
…"AZ" The uppercase alphabet (technically, the string "AZ" rangified).
Ṫ Outer product of the alphabet and x
S`?' € using this function:
Arguments: character, say c = 'L', and string, say s = "EL".
€ 1-based index of c in s, or 0 if not found: 2
S`?' If this is truthy, then c, else a space: 'L'
This gives, for each letter c of the alphabet,
a string of the same length as x,
containing c for those substrings that contain c,
and a space for others.
T Transpose, implicitly print separated by newlines.
Python 2, 92 bytes
f=lambda x,y=65:x and(y<=ord(x[0])and" "*(ord(x[0])-y)+x[0]+f(x[1:],-~ord(x[0]))or"\n"+f(x))